こんにちは。
データサイエンティストの卵 ”ひよこ” です🐣

機械学習や統計モデリングについて、”はやぶさ先生”@Cpp_Learningから色々と教わりながら、日々データと真剣に向き合ってるよ♪
今回はデータサイエンスに役立つルールベースの話をするよー
Contents
データサイエンスとは
データサイエンスとは『データから価値ある情報を抽出するアプローチや研究分野のこと』です。
例えば、統計ベースの解析や機械学習による推論なんかも数あるアプローチの一つです。
データサイエンスを武器にして仕事する人たちをデータサイエンティストと呼びます。データサイエンティストは21世紀で最もセクシーな職業らしいです✨
仮説検証
”はやぶさ先生”は以下の手順でデータサイエンスすることが多いよ。
- 仮説を立てる
- 仮説を検証するための試験方法(データ収集のやり方含む)を検討する
- 様々なアプローチでデータを多角的に観察・検証する
- 初手はデータ可視化
- 統計ベースの解析
- ルールベース・機械学習・振動解析などケースバイケース
※どのステップでも有識者やユーザーと議論しながら進められるのがベストです
いわゆる仮説検証というやつだよ♪
データサイエンティストだからといってデータのみから判断するのではなく、ドメイン知識などのあらゆる情報を全て利用して、総合的に判断することが重要です。
価値ある情報を抽出・提供することがゴールだよ。以下はゴールではないよ!
- 複雑なアプローチを検討・設計すること
- データを料理すること
探索的データ解析(EDA:Exploratory Data Analysis)

そんなときは仮説検証のステップ➌を先に実施します。いわゆる探索的データ解析(EDA)というやつです🐣
特徴的なデータを見つけて、何故そうなるのか?ちょっとして○○なのでは!などと深堀りすることで仮説を思いつくことがあります。
下記のポケモンを題材にしたEDAがすごく面白いし、参考になるよ
Avinton Exploratory Data Analytics(探索的データ解析) 勉強会|Avinton blog
機械学習はアプローチの一つ
近年のAIブームもあり、機械学習を活用してデータを料理することをデータサイエンスだと考えている人がいるかも(?)
繰り返しますが、機械学習は数あるアプローチの一つに過ぎません。データを可視化するだけで価値ある情報を発見できることもあります。
機械学習で課題解決とかできたらカッコイイけど…

って”はやぶさ先生”が言ってたよ🐣
その特徴量は重要ですか?
機械学習モデルによる推論は強力な武器ですが、説明性・解釈性が困難なケースもあります。

因果推論・因果探索を行うことで、説明根拠のあるデータ分析を実践できるかもしれません。
複数のアプローチにトライし、多角的な視点で考察することが重要です🐣
機械学習は難しい
機械学習について勉強してるけど、以下が難し過ぎて”ひよこ”には扱えないかも…🐣
- モデリング
- ハイパーパラメータチューニング
- モデルの評価
AutoMLを駆使しながら頑張ってるけど、仮説検証に機械学習…特に深層学習を使うのは難しいと感じています。


深層学習で色々とトライしてたときに…
とか言われて泣いちゃった🐣なんで?初期値が違っても十分時間を使って学習すれば同じ結果にならないの??
…という機械学習のツライ部分も理解した上で、今回は”ひよこ”にもできるルールベースの仮説検証にトライしたよ♪
Human Learning -ルールベースシステムの設計ツール-
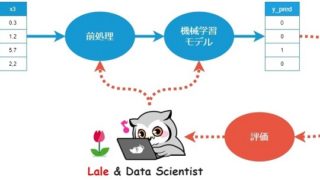
AIブームが来る以前は、ルールベースのシステムを設計するのが一般的でした。

近年では上図のルール(rules)部分が機械学習(ML:Machine Learning)に置き換わりました。ただし、MLモデルの適切な設計・評価ができず、悪い結果を出力するケースがあります。

そこでMLに解を算出させるのではなく、ルールベースシステム設計のサポートツールとしてMLを活用するというアイデアがあります。
このアイデアを比較的簡単に実現できるのが Human Learning です。
実践!ルールベースな仮説検証
Human Learning の マインド や Examples はどれも非常に参考になりますが、今回は特にオススメの Human Preprocessing を紹介します🐣
課題
今回はタイタニックのデータセットを使い、『どんな乗客が生存できたか?』という課題に対し、仮説検証を実践します。
- 「重要な特徴量は○○」という仮説(ルール)を検討する
- 重要な特徴量を把握する=仮説を検証する
- 検証にscikit-learnがサポートしてるMLなどを活用する
インストール
最初に以下のコマンドでインストールします。
pip install human-learn
以降から実践するよー♪
Import
まずはimportから
|
1 2 3 4 5 6 7 8 |
import pandas as pd from hulearn.datasets import load_titanic from hulearn.preprocessing import PipeTransformer from sklearn.pipeline import Pipeline from sklearn.naive_bayes import GaussianNB from sklearn.model_selection import GridSearchCV |
データセット
以下のコードでデータセットをロードします。
|
1 2 3 |
df = load_titanic(as_frame=True) X, y = df.drop(columns=['survived']), df['survived'] X.head() |
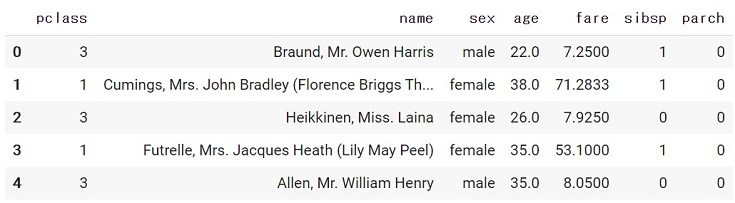
Xに乗客の情報、yに生存できたか否か(1 or 0)の情報が保存してあります。
仮説と前処理
”ひよこ”は「名前の文字数」と「乗客の性別」が重要な特徴量!という仮説を考えました🐣
この仮説を検証するために、前処理用の関数を作成します。
|
1 2 3 4 5 6 7 8 |
def preprocessing(df, n_char=True, gender=True): df = df.copy() if n_char: df['nchar'] = df['name'].str.len() if gender: df['gender'] = (df['sex'] == 'male').astype("float") return df.drop(columns=["name", "sex"]) |
以下のように True or False の選択により、前処理後の特徴量を採用するか否かを設定できます。
|
1 2 |
prep_df = preprocessing(X, n_char=True, gender=True) prep_df.head() |
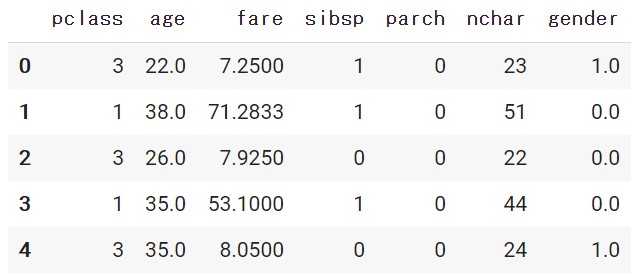
|
1 2 |
prep_df = preprocessing(X, n_char=False, gender=True) prep_df.head() |
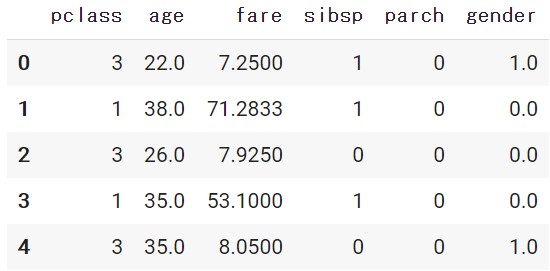
PipeTransformerを活用したパイプライン設計
PipeTransformer を活用することで、さきほど作った前処理関数を scikit-learn pipeline の一部として使えるように、互換性を持たせて変換してくれます。
|
1 2 |
# Important, don't forget to declare `n_char` and `gender` here. tfm = PipeTransformer(preprocessing, n_char=True, gender=True) |
今回は『前処理 ⇒ Gaussian Naive Bayes』のパイプラインを設計し、さらにグリッドサーチを用いて、前処理後の特徴量を採用するか否かの選択を自動化します。
|
1 2 3 4 5 6 7 8 9 10 11 |
pipe = Pipeline([ ('prep', tfm), ('model', GaussianNB()) ]) params = { "prep__n_char": [True, False], "prep__gender": [True, False] } grid = GridSearchCV(pipe, cv=3, param_grid=params).fit(X, y) |
このように Pandas ベースの前処理をパイプラインに組み込める PipeTransformer は非常に強力です。
仮説検証
グリッドサーチの結果は辞書型で保存されるので、key を指定して values を取得します。
|
1 2 3 4 5 6 7 |
cv_result = grid.cv_results_ # print(cv_result) print(cv_result['param_prep__gender']) print(cv_result['param_prep__n_char']) print(cv_result['mean_test_score']) print(cv_result['std_test_score']) |
今回は以下のコードにより、結果を表で出力させました🐣
|
1 2 3 4 5 6 7 8 |
result_df = pd.DataFrame({ 'param_prep__gender':cv_result['param_prep__gender'].data, 'param_prep__n_char':cv_result['param_prep__n_char'].data, 'mean_test_score':cv_result['mean_test_score'], 'std_test_score':cv_result['std_test_score'] }) result_df |
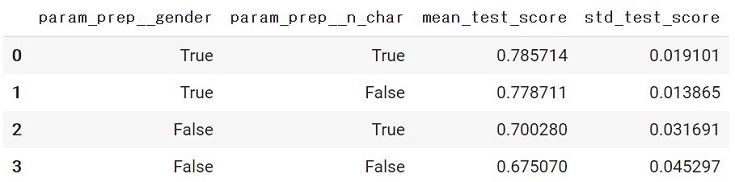
この表から『「名前の文字数」よりも「乗客の性別」の方が生存に大きく影響する』という検証結果を得ることができました🐣
このような仮説検証を繰り返し、もし『裕福な成人男性の生存率が高い』という結果が得られたなら、以下のようなルールベースシステムを設計できる見込みがあります。
下記の項目(特徴量)から、その乗客が生存できたか否かを判定
- 裕福か?(pclass==1)
- 20歳以上か?(age >= 20)
- 男性か?(sex==male)
ルールベースなので、非常に納得感のある判定結果を出力してくれます。
おわりに
データサイエンティストの卵 ”ひよこ” です🐣
機械学習に頼り過ぎるのではなく、協力しながら仮説検証にトライしました。最終的にはルールベースシステムの構築までしたかったけど…1回の検証だけでは難しかったです💦
でも仮説検証を繰り返せば、いつか皆が納得してくれるルールベースシステムを構築できると信じて頑張るよ♪
本記事は参考になったかな?
”ひよこ”と同じデータサイエンティストの卵 や 強よ強よな人 はどんなマインドでデータサイエンスと向き合っているのか気になるなー
もし教えてくれる人は、”はやぶさ先生”@Cpp_LearningのTwitter経由で教えてくれたら嬉しいな(本記事の感想も大歓迎です!)
本記事の評判が良ければ、また頑張って”ひよこ”が記事書いちゃおっかなー!笑
おしまい

















