こんにちは。
現役エンジニアの”はやぶさ”@Cpp_Learningです。最近は、Pytorchを使って深層学習を楽しんでいます。
今回は、ハイパーパラメータ自動最適化フレームワーク Optuna を使って、ハイパーパラメータの自動チューニングを実践したので、備忘録も兼ねて本記事を書きます。
Contents
Optunaとは
Optunaやハイパーパラメータについては、PFN公式ブログに丁寧な解説がありますので、本記事では割愛し…
Optunaを活用したハイパーパラメータ自動チューニングのイメージのみを説明します。
従来、人がチューニングしていたハイパーパラメータを…
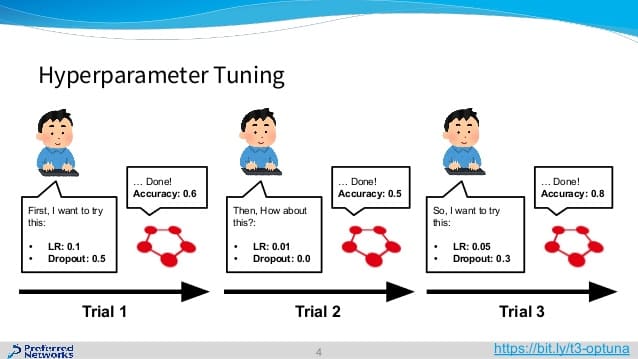
Optunaが代わりにやってくれます(ハイパーパラメータの自動チューニング)
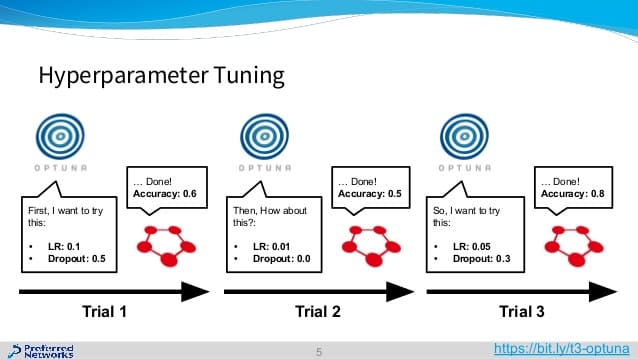
以上!
なお、上図は Chainer の例ですが、以下のExamplesコードが用意してあります。
- Scikit-learn
- LightGBM
- CatBoost
- MXNet
- PyTorch
- PyTorch Ignite
- PyTorch Lightning
- XGBoost
- Tensorflow
- Keras
など
LightGBM のハイパーパラメータをチューニングすることに特化した LightGBMTuner なんてのもあります。
Optunaの基本的な使い方
Optunaの基本的な使い方を紹介します。
インストール
Optunaは以下のコマンドでインストールできます。
pip install optuna
Optunaの基本的なコード
以下がOptunaの基本的なコードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import optuna # 目的関数 def objective(trial): ''' 最適化対象のコード ''' return score # 最適化(score:最小化, トライアル数:100) study = optuna.create_study() study.optimize(objective, n_trials=100) |
目的関数を定義し、Studyで最適化(スコア最小化)を実行します。なお、スコア最大化の場合は以下のコードを使います。
|
1 2 3 4 5 |
# 最適化(score:最大化, トライアル数:50) study = optuna.create_study(direction='maximize') study.optimize(objective, n_trials=50) |
トライアル数ではなく、時間をトリガーに最適化を終了させることもできます。以下のコードを使えば、60secでトライアルが終了します。
|
1 2 3 4 |
study = optuna.create_study(direction='maximize') study.optimize(objective, timeout=60) |
トライアル数と時間の両方を設定することもできます。例えば「トライアル数:100だけど、10min(600sec)超える場合は打ち切り」などは以下のコードで実現できます。
|
1 2 3 4 |
study = optuna.create_study(direction='maximize') study.optimize(objective, n_trials=100, timeout=600) |
最適化対象のコード(チューニング例)
最適化対象のコード例は以下の通りです。
|
1 2 3 4 5 6 7 |
# 最適化対象のコード n_channels = trial.suggest_int('n_channels', 6, 12) # 6~12 dropout = trial.suggest_uniform('dropout', 0.2, 0.5) # 0.2~0.5 lr = trial.suggest_loguniform('lr', 1e-5, 1e-1) # 1e-5~1e-1 k_size = trial.suggest_categorical('ksize', [3, 5, 7]) # 3 or 5 or 7 optimizer_name = trial.suggest_categorical('optimizer', ['Adam', 'SGD']) # Adam or SGD |
パラメータを6~12(int)の範囲でチューニングしたり、3 or 5 or 7のように3つのパラメータからチューニングするなどが可能です。
最適化の結果
最適化の結果は以下のコードで確認できます。
|
1 2 3 4 5 6 7 8 |
print('Best trial:') trial = study.best_trial print(' Value: {}'.format(trial.value)) print(' Params: ') for key, value in trial.params.items(): print(' {}: {}'.format(key, value)) |
トライアルの様子はデータフレーム形式で確認できます。
|
1 2 3 4 |
df = study.trials_dataframe() # pandasのDataFrame形式 print(df.head()) |
基本的な使い方については以上になります。
実践!Optunaでハイパーパラメータの自動チューニング -Pytorch Lightning編-
今回は、Pytorch Lightning で設計したCNNのハイパーパラメータをOptunaで自動チューニングしてみます。
Pytorch Lightningについては、インストール方法から実践まで以下の記事で説明済みのため、本記事では割愛します。

最適化対象
PyTorch LightningのExample(公式) では以下の項目をOptunaでチューニングしています。
- NNのレイヤー数(n_layers)
- ドロップアウト(dropout)
今回は、レイヤー数を固定して以下の項目をOptunaでチューニングしてみます。
- CNNのチャンネル数(n_channels)
- NNのニューロン数(n_neurons)
- オプティマイザー(optimizer)
- 学習率(lr)
Import
最初はimportから
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import os import shutil import torch import torch.nn as nn import torch.nn.functional as F # from torch.optim import Adam, SGD import torch.optim as optim import torch.utils.data from torchvision import datasets from torchvision import transforms import optuna import pytorch_lightning as pl |
Logger
Loggerクラスを自作します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
class DictLogger(pl.logging.LightningLoggerBase): """PyTorch Lightning `dict` logger.""" def __init__(self, version): super(DictLogger, self).__init__() self.metrics = [] self._version = version def log_metrics(self, metric, step_num=None): self.metrics.append(metric) @property def version(self): return self._version |
CNN設計
Pytorchの公式チュートリアル を参考にCNNを設計し、隠れ層のチャンネル数などをOptunaでチューニングします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
class Net(nn.Module): def __init__(self, trial): super().__init__() # We optimize the number of channels and neurons. n_channels = trial.suggest_int('n_channels', 6, 12) n_neurons = trial.suggest_int('n_neurons', 80, 160) # Convolutional Neural Network self.conv1 = nn.Conv2d(1, n_channels, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(n_channels, 16, 5) self.fc1 = nn.Linear(16 * 4 * 4, n_neurons) self.fc2 = nn.Linear(n_neurons, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 4 * 4) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return F.log_softmax(x, dim=1) |
Optimizer
オプティマイザー選定および学習率のチューニングについてもOptunaを活用するため、以下の関数を自作します。
|
1 2 3 4 5 6 |
def Get_Optimizer(trial, model): # Generate the optimizers. optimizer_name = trial.suggest_categorical('optimizer', ['Adam', 'RMSprop', 'SGD']) lr = trial.suggest_loguniform('lr', 1e-5, 1e-1) optimizer = getattr(optim, optimizer_name)(model.parameters(), lr=lr) return optimizer |
※関数化は必須ではありませんが、推奨です。
- 関数化により、後から出てくる学習システムのコードがスッキリします
- クラス化と迷いましたが、今回は関数にしました
System設計
PyTorch Lightningでは、以下のような学習システムを設計します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
class LightningNet(pl.LightningModule): def __init__(self, trial): super(LightningNet, self).__init__() self.trial = trial # for optuna self.model = Net(self.trial) def forward(self, data): return self.model(data) def training_step(self, batch, batch_nb): data, target = batch output = self.forward(data) loss = F.nll_loss(output, target) return {'loss': loss} def validation_step(self, batch, batch_nb): data, target = batch output = self.forward(data) pred = output.argmax(dim=1, keepdim=True) correct = pred.eq(target.view_as(pred)).sum().item() accuracy = correct / data.size(0) return {'validation_accuracy': accuracy} def validation_end(self, outputs): accuracy = sum(x['validation_accuracy'] for x in outputs) / len(outputs) # Pass the accuracy to the `DictLogger` via the `'log'` key. return {'log': {'accuracy': accuracy}} def configure_optimizers(self): # Generate the optimizers. return Get_Optimizer(self.trial, self.model) @pl.data_loader def train_dataloader(self): return torch.utils.data.DataLoader( datasets.MNIST(DIR, train=True, download=True, transform=transforms.ToTensor()), batch_size=BATCHSIZE, shuffle=True) @pl.data_loader def val_dataloader(self): return torch.utils.data.DataLoader( datasets.MNIST(DIR, train=False, download=True, transform=transforms.ToTensor()), batch_size=BATCHSIZE, shuffle=False) |
Optuna用の変数:self.trial があること以外は、Pytorch Lightningの基本的なコードと同じです。
Objective
最適化対象のコード(目的関数)を自作します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
def objective(trial): # PyTorch Lightning will try to restore model parameters from previous trials if checkpoint # filenames match. Therefore, the filenames for each trial must be made unique. checkpoint_callback = pl.callbacks.ModelCheckpoint( os.path.join(MODEL_DIR, 'trial_{}'.format(trial.number)), save_best_only=False) # The default logger in PyTorch Lightning writes to event files to be consumed by # TensorBoard. We create a simple logger instead that holds the log in memory so that the # final accuracy can be obtained after optimization. When using the default logger, the # final accuracy could be stored in an attribute of the `Trainer` instead. logger = DictLogger(trial.number) trainer = pl.Trainer( logger = logger, train_percent_check = PERCENT_TRAIN_EXAMPLES, val_percent_check = PERCENT_TEST_EXAMPLES, checkpoint_callback = checkpoint_callback, max_nb_epochs = EPOCHS, gpus = 0 if torch.cuda.is_available() else None, ) model = LightningNet(trial) trainer.fit(model) return logger.metrics[-1]['accuracy'] |
今回は、accuracyを最適化(最大化)します。
Optimize hyperparameters of the model
Studyで最適化を実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
PERCENT_TRAIN_EXAMPLES = 0.1 PERCENT_TEST_EXAMPLES = 0.1 BATCHSIZE = 128 CLASSES = 10 EPOCHS = 10 DIR = os.getcwd() MODEL_DIR = os.path.join(DIR, 'result') study = optuna.create_study(direction='maximize') study.optimize(objective, n_trials=100, timeout=600) shutil.rmtree(MODEL_DIR) |
今回は、トライアル数:100, Timeout:600(600secで打ち切り)としました。
Result of optimization
以下のコードで最適化の結果を確認します。
|
1 2 3 4 5 6 7 8 9 10 |
print('Number of finished trials: {}'.format(len(study.trials))) print('Best trial:') trial = study.best_trial print(' Value: {}'.format(trial.value)) print(' Params: ') for key, value in trial.params.items(): print(' {}: {}'.format(key, value)) |
今回の最適化結果は以下の通りでした。
- Number of finished trials: 83
- Best trial:
- Value: 0.9720982142857143
- Params:
- n_channels: 6
- n_neurons: 115
- optimizer: Adam
- lr: 0.008573323660481427
トライアル数:83(10分で100トライアル終了しなかった)、Value(Accuracy):0.97を叩き出したベストハイパーパラメータ(Params)が上記の通りです。
以下のコードでトライアルの様子を確認できます。
|
1 2 3 4 |
df = study.trials_dataframe() # pandasのDataFrame形式 print(df.tail(10)) |
本記事では表を出しませんが、トライアルの終盤はオプティマイザー:Adam一択だったことを確認できました。

以上で実践も終了です。
まとめ
Optunaの基本的な使い方から、Optuna + Pytorch Lightning の実践まで説明しました。

Optunaによる自動最適化とPytorch Lightningによる学習システムの組み合わせ…名付けて『自動最適化機能付き学習システム』ってところかな(*・ω・)ノ♪
本記事で公開しているソースコードは自由に使ってOKです(改良も問題なし)。
Optuna + Pytorch Lightnigを是非使ってみてください。
よろしくお願いします。


















