こんにちは。
現役エンジニアの”はやぶさ”@Cpp_Learningです。仕事でもプライベートでも機械学習で色々やってます。
今回は機械学習のハイパーパラメータ自動チューニングからパイプラインの自動選定までを丸っと実現できる Lale|IBM の簡単な使い方を紹介します。
Contents
パイプライン構築
機械学習モデルに対し、データの入出力をシームレスに実現するため、以下のようなパイプラインを構築するのですが…

扱うデータやタスクに応じて、数ある前処理や機械学習モデルの最適な組み合わせを検討する必要があります。
また採用する前処理や機械学習アルゴリズム次第では、ハイパーパラメータのチューニングが必要です。
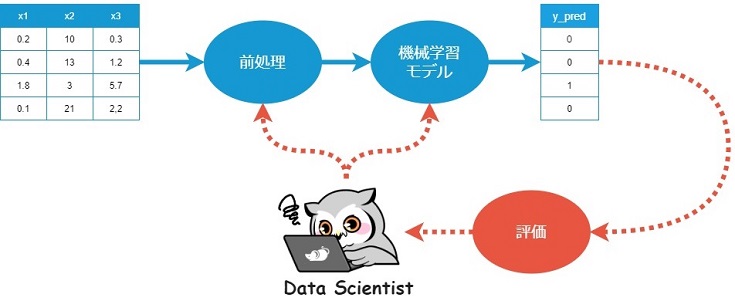
多くの場合、数回の検討・調整では上手くいかず、何度も PoC を回すことになります。

と考えているフクロウには Lale をオススメします。
Laleとは
Lale とはデータサイエンスを半自動化するためのPythonライブラリです。
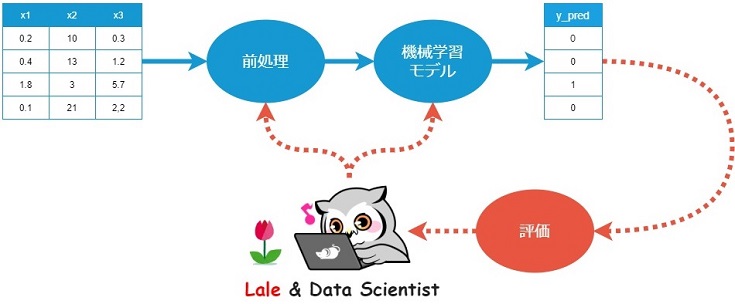
具体的には複数ある前処理と機械学習モデルの最適な組み合わせを自動選定し、かつハイパーパラメータの自動チューニングまで行った上で、scikit-learn と互換性のあるパイプラインを構築できるライブラリです。
というフクロウのために、Lale の使い方を紹介します。
実践!Laleによるパイプライン自動選定からハイパーパラメータ自動調整まで -基礎編-
最初に以下のコマンドで Lale をインストールします。
pip install lale
以降からコードを書いていきます。
Import
まずはimportから
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from sklearn import datasets from sklearn import metrics from sklearn.preprocessing import Normalizer, StandardScaler from sklearn.metrics import classification_report, accuracy_score from sklearn.model_selection import train_test_split from sklearn.decomposition import PCA from sklearn.tree import DecisionTreeClassifier import lale # import lale.datasets from lale.lib.lale import Hyperopt from lale.operators import make_pipeline from lale.lib.lale import NoOp, ConcatFeatures from xgboost import XGBClassifier from lightgbm import LGBMClassifier lale.wrap_imported_operators() |
最後のコードは Lale を使うときの”おまじない”です。
データセット
今回は load_breast_cancer のデータセットを使い、機械学習による2値分類を行います。
以下のコードでデータセットをロードし、学習用と評価用に分けます。
|
1 2 3 4 5 6 |
cancer = datasets.load_breast_cancer() x = cancer.data y = cancer.target # split dataset (train:test = 7:3) x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=42) |
パイプライン設計から可視化まで
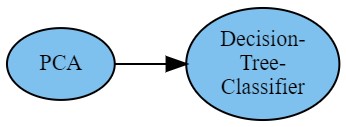
以下のコードで『PCA ⇒ 決定木』のパイプラインを設計できます。
|
1 2 3 |
# create pipeline(PCA → Tree) pipeline = PCA >> DecisionTreeClassifier |
可視化もできます。
|
1 2 3 |
# visualize pipeline pipeline.visualize() |
少し複雑なパイプライン設計
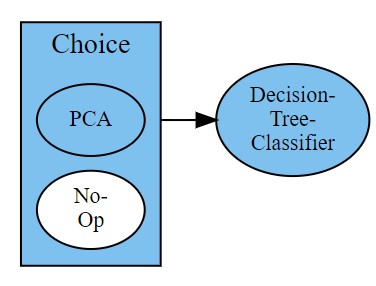
前処理を選択可能なパイプライン『PCA or raw data ⇒ 決定木』も設計できます。
|
1 2 3 4 5 |
# create pipeline(PCA or raw data → Tree) pipeline = (PCA | NoOp) >> DecisionTreeClassifier # visualize pipeline pipeline.visualize() |
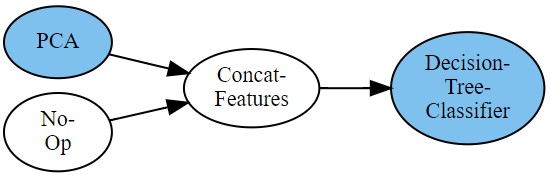
複数の前処理した結果を結合してモデルに入力する『PCA + raw data ⇒ 決定木』もできます。
|
1 2 3 4 5 6 7 8 9 |
# create pipeline(PCA and raw data → Tree) pipeline = ( (PCA & NoOp) >> ConcatFeatures >> DecisionTreeClassifier ) # visualize pipeline pipeline.visualize() |
パイプライン自動選定からハイパーパラメータ自動調整まで
今回は以下のパイプラインを設計したとします。
Laleを使ってパイプライン選定からハイパーパラメータの調整までを自動化します。
|
1 2 3 4 5 6 7 8 9 |
# Hyperparameter Tuning model = pipeline.auto_configure( x_train, y_train, optimizer=Hyperopt, cv=3, max_evals=10, # scoring='r2' scoring='accuracy' ) |
※パイプライン選定(Chaice)が無い場合は、上記のコードでハイパーパラメータの自動チューニングのみを行います。
パイプライン選定およびハイパーパラメータ調整の結果を確認
以下のコードでチューニング結果を確認できます。
|
1 2 3 |
# print best model model.pretty_print(ipython_display=True, show_imports=False) |
decision_tree_classifier = DecisionTreeClassifier(
max_features=0.25040322158625117,
min_samples_leaf=0.04370434701236803,
min_samples_split=0.32229487429436415
)
pipeline = NoOp() >> decision_tree_classifier
『raw data ⇒ 決定木』が選択され、かつハイパーパラメータのチューニング結果は上記の通りでした。
推論と評価
最後に構築したパイプラインに評価用データを入力し、モデルを評価します。
|
1 2 3 4 5 6 7 |
y_pred = model.predict(x_test) # print("y_pred:", y_pred) # print("y_test:", y_test) # print precision, recall, f1-score, support print(classification_report(y_test, y_pred)) print("score:", accuracy_score(y_test, y_pred)) |
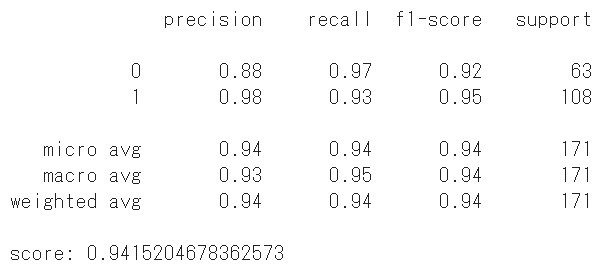
なかなか良いスコアですね。ここまでが【基礎編】です。
そんなことないで、以降の【応用編】で実践します。
実践!Laleによるパイプライン自動選定からハイパーパラメータ自動調整まで -応用編-
【基礎編】では前処理の選定からハイパーパラメータの調整までを自動化しました。【応用編】では複数の機械学習モデルも自動選定するパイプラインを設計します。
GBDT -LightGBMとXGBoostを比較・選定-
やっぱりGBDT (Gradient Boosting Decision Tree)使いたいですよね。また前処理に標準化なども追加・選択できるようにします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
from sklearn import datasets from sklearn.preprocessing import Normalizer, StandardScaler from sklearn.metrics import classification_report, accuracy_score from sklearn.model_selection import train_test_split from sklearn.decomposition import PCA from sklearn.tree import DecisionTreeClassifier import lale from lale.lib.lale import Hyperopt from lale.lib.lale import NoOp, ConcatFeatures from xgboost import XGBClassifier from lightgbm import LGBMClassifier lale.wrap_imported_operators() # datasets cancer = datasets.load_breast_cancer() x = cancer.data y = cancer.target # split dataset (train:test = 7:3) x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=42) # create pipeline pipeline = ( (Normalizer | StandardScaler | NoOp) >> (PCA | NoOp | (PCA & NoOp) >> ConcatFeatures) >> (DecisionTreeClassifier | XGBClassifier | LGBMClassifier) ) # visualize pipeline pipeline.visualize() # Hyperparameter Tuning model = pipeline.auto_configure( x_train, y_train, optimizer=Hyperopt, scoring='accuracy' ) # print best model model.pretty_print(ipython_display=True, show_imports=False) # predict y_pred = model.predict(x_test) # print("y_pred:", y_pred) # print("y_test:", y_test) # print precision, recall, f1-score, support print(classification_report(y_test, y_pred)) print("score:", accuracy_score(y_test, y_pred)) |
設計したパイプラインは下図の通りです。
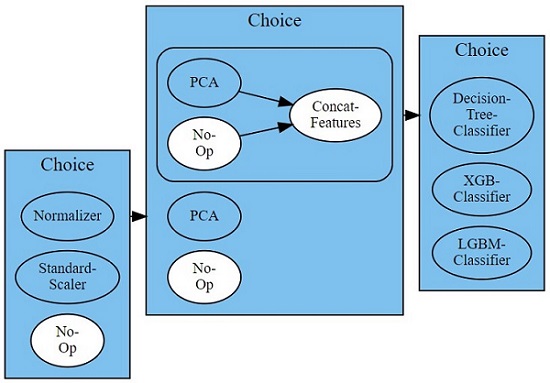
Laleをによる選定・チューニング結果は以下の通りでした。

良いスコアですね。
そうですね。便利なツールはどんどん取り入れれば良いと思います。ただし Lale については以下の注意点があります。
- 2020/09/19時点の Lale は α版
- 公式ドキュメントが不足気味
いずれも時間が解決してくれる気もしますが、Laleが使えなくても、データサイエンスできるように知識やスキルを蓄えておくと安心ですね。
まとめ
Laleでパイプライン構築からハイパーパラメータのチューニングまで自動化しました。
Lale含めAutoMLツールを上手に活用し、効率よくデータサイエンスを実践できると良いですね。
今後もAutoMLに関する情報をキャッチしたら、記事にしたいと思います。

以下 本記事と関連のある記事を紹介。