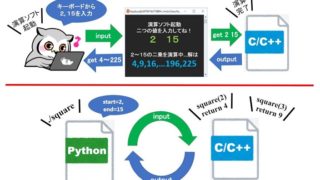
こんにちは。
現役エンジニアの”はやぶさ”@Cpp_Learningです。
C++でソフトウェア開発をしています。C++でプログラミングをしていると…
【やりたいこと】
- 並列処理で高速化したい
- 安全にマルチタスクを実現したい
と思うことがあります。
いくつか方法はありますが、”Cpp-Taskflow”を使えば、”スマート”に【やりたいこと】を実現できそうだったので、勉強してみました。
勉強した内容を自分なりに消化吸収して…

微力ではありますが、現役エンジニアの”はやぶさ”が皆様の勉強をサポートさせて頂きます。本記事をきっかけに、情報処理技術をもっと学びたい!という人が増えると嬉しいです(*・ω・)ノ♪
なお、本記事の【文章構成】は以下の通りなので、ソースコードだけ見せて!という人は、目次から『Cpp-Taskflowで並列処理(マルチタスク)-基礎編-』に飛んで後編から読み進めて下さいな。
【文章構成】
- 前編:マルチタスク・排他制御などの情報処理技術の説明
- 後編:マルチタスクプログラミングの実践 -基礎から応用まで-
Contents
タスク(プロセス)とは
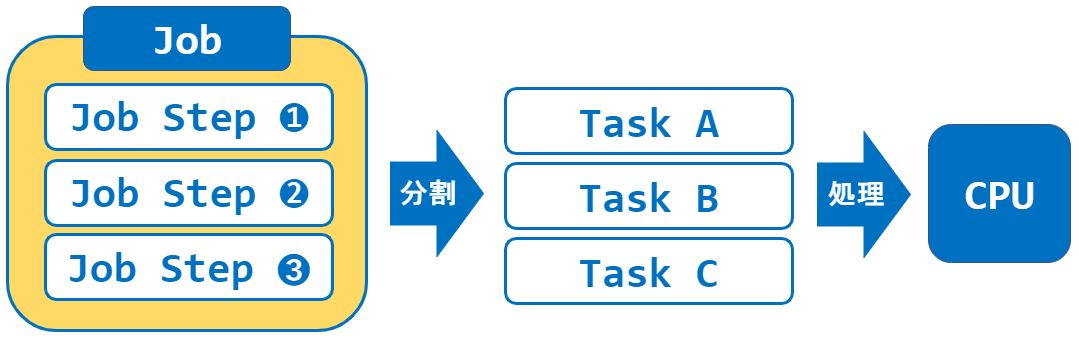
ユーザーがコンピュータにやらせたい処理のことをジョブと呼びます。
例えば、「画像ファイルを読み込む ⇒ 画像を加工 ⇒ 別ファイルに保存」というプログラムがあったとします。この一連の処理を1つのジョブと考えることができます。
ジョブはジョブステップという単位に分割されます。今回の場合、3つのジョブステップに分割されます。
【ジョブステップ】
- 画像ファイルを読み込む(ジョブステップ❶)
- 画像ファイルを加工(ジョブステップ❷)
- 加工後の画像ファイルを保存(ジョブステップ➌)
さらに、ジョブをタスクという単位に分割し、CPUがタスク単位で処理を行います。
※タスクのことをプロセスと呼ぶことがあります。
- ジョブはタスクという単位で分割されます
- CPUはタスク単位で処理を行います
- タスクのことをプロセスと呼ぶことがあります
シングルタスクとマルチタスク
シングルタスクとマルチタスクについて説明します。
シングルタスクとは
ジョブを分割せず、1つのタスクで処理するとします。

この場合、”Task A”はCPU(などのハードウェア資源)を占有して利用することができます。
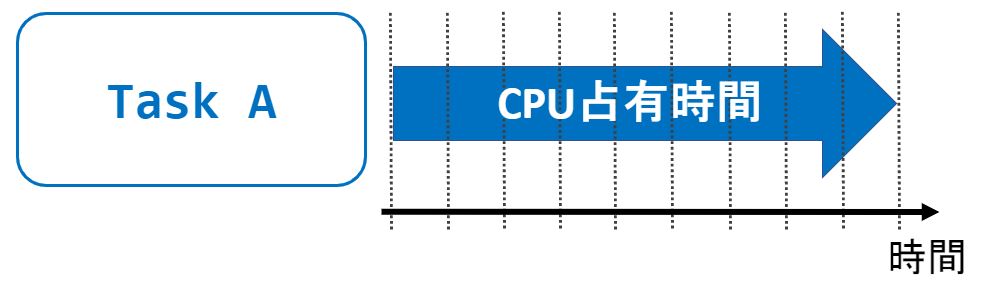
このように1つのタスクがハードウェア資源を占有して利用する処理をシングルタスクと呼びます。
マルチタスクとは
ジョブを3つのタスクに分割したとします。
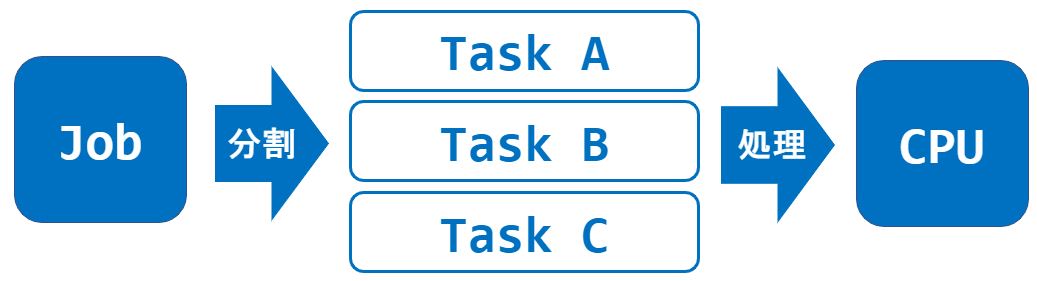
この場合、”Task A”・”Task B”・”Task C”はCPU(などのハードウェア資源)を共有して利用することになります。
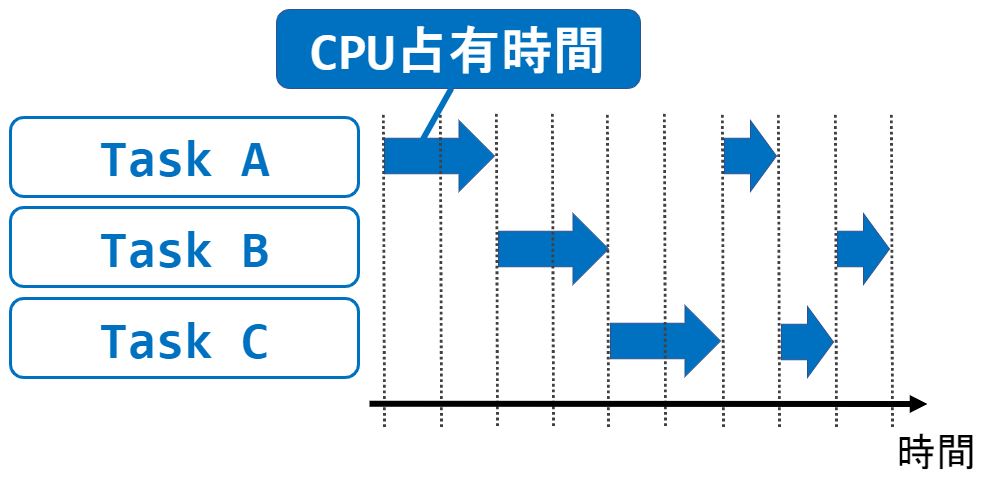
このように複数のタスクがハードウェア資源を共有して利用する処理をマルチタスクと呼びます。
【シングルタスク】
1つのタスクがCPUなどのハードウェア資源を占有して利用する処理
【マルチタスク】
複数タスクがCPUなどのハードウェア資源を共有して利用する処理
マルチタスクと排他制御
マルチタスクの場合、タスク同士がハードウェア資源を取り合い、適切な処理ができないときがあります。
このような競合を防ぐために排他制御をする必要があります。
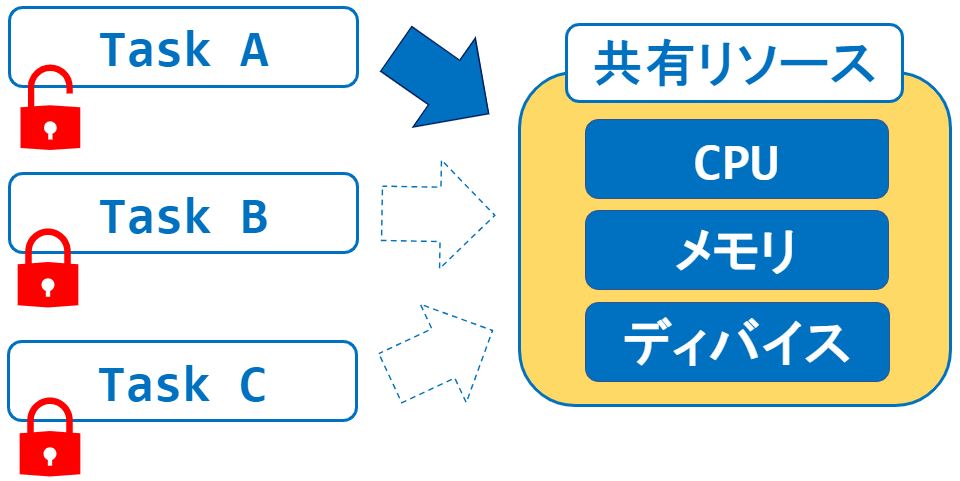 例えば、”Task A”が共有リソースにアクセスするとき、他のタスクをロックしてアクセス競合を防ぐように制御します。
例えば、”Task A”が共有リソースにアクセスするとき、他のタスクをロックしてアクセス競合を防ぐように制御します。
- マルチタスクでは、資源の取り合いが原因で不具合が発生するときがあります
- 各タスクの排他制御により、共有リソースのアクセス競合を防ぎます
ここまでが『前編:マルチタスク・排他制御などの情報処理技術』の説明でした。
続いて『後編:マルチタスクプログラミングの実践 -基礎から応用まで-』について説明します。
(前編 完)
Cpp-Taskflowで並列処理(マルチタスク)-基礎編-
排他制御の実装方法は、いくつかありますが、”Cpp-Taskflow”を使うとスマートに実装することができます。
Cpp-Taskflowのシンプルな使い方
”Cpp-Taskflow|GitHub”は”ヘッダーオンリーなライブラリ”なので、taskflow.hppをインクルードするだけで使うことができます。
Cpp-Taskflowのシンプルな使い方(simple.cpp)は以下の通りです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
// Cpp-Taskflow is header-only #include "../taskflow/taskflow.hpp" int main(){ tf::Taskflow tf; auto [A, B, C, D] = tf.emplace( [] () { std::cout << "Task A" << std::endl; }, // task dependency graph [] () { std::cout << "Task B" << std::endl; }, // [] () { std::cout << "Task C" << std::endl; }, // +---+ [] () { std::cout << "Task D" << std::endl; } // +---->| B |-----+ ); // | +---+ | // +---+ +-v-+ A.precede(B); // A runs before B // | A | | D | A.precede(C); // A runs before C // +---+ +-^-+ B.precede(D); // B runs before D // | +---+ | C.precede(D); // C runs before D // +---->| C |-----+ // +---+ tf.wait_for_all(); // block until finish return 0; } |
順番に解説していきます。
Step 1: Create a Task
最初にタスク生成用のオブジェクトを生成します。
|
1 2 3 |
tf::Taskflow tf; |
次に”Task A”を生成します。
|
1 2 3 |
tf::Task A = tf.emplace([](){ "タスクAの処理" }); |
例えば、”Task A”と表示する処理の場合は以下の通りです。
|
1 2 3 |
tf::Task A = tf.emplace([](){ std::cout << "Task A" << std::endl; }); |
タスクの生成と処理を別々に書くこともできます。
|
1 2 3 4 |
tf::Task A = tf.emplace([](){}); A.work([] () { std::cout << "Task A" << std::endl; }); |
タスクが複数でも単数のとき同様に生成することができます。
|
1 2 3 4 5 6 |
tf::Task A = tf.emplace([](){ std::cout << "Task A" << std::endl; }); tf::Task B = tf.emplace([](){ std::cout << "Task B" << std::endl; }); tf::Task C = tf.emplace([](){ std::cout << "Task C" << std::endl; }); tf::Task D = tf.emplace([](){ std::cout << "Task D" << std::endl; }); |
以下のようにタスクをまとめて生成することもできます。
|
1 2 3 4 5 6 7 8 |
auto [A, B, C, D] = tf.emplace( [] () { std::cout << "Task A" << std::endl; }, [] () { std::cout << "Task B" << std::endl; }, [] () { std::cout << "Task C" << std::endl; }, [] () { std::cout << "Task D" << std::endl; } ); |
簡単にタスク(プロセス)を生成できます
Step 2: Define Task Dependencies
生成したタスクをどの順番で処理するかを定義します。
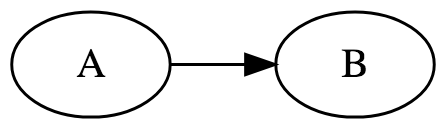
”Task A” ⇒ ”Task B”の順番に処理する書き方は2通りあります。
【Precede(1 on 1)】
|
1 2 3 |
A.precede(B); // A runs before B. |
【Gather(1 on 1)】
|
1 2 3 |
B.gather(A); // B runs after A |
1対1じゃなくても定義できます。
【Precede(1 on N)】
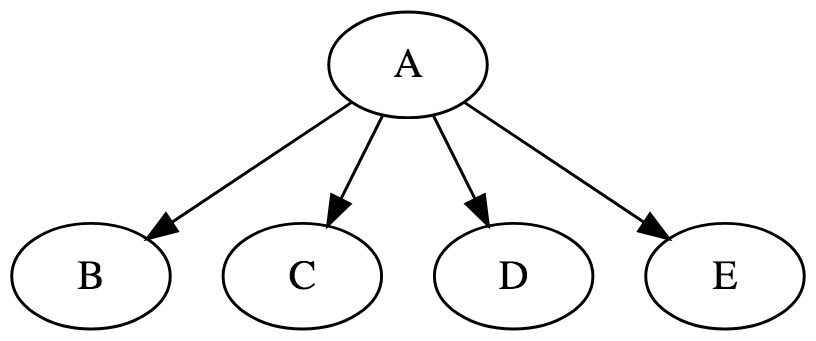
|
1 2 3 4 5 |
// make A run before B, C, D, and E // B, C, D, and E run in parallel A.precede(B, C, D, E); |
※”Task B”, ”Task C”, ”Task D”, ”Task E”は並列処理されます
【Gather(N on 1)】
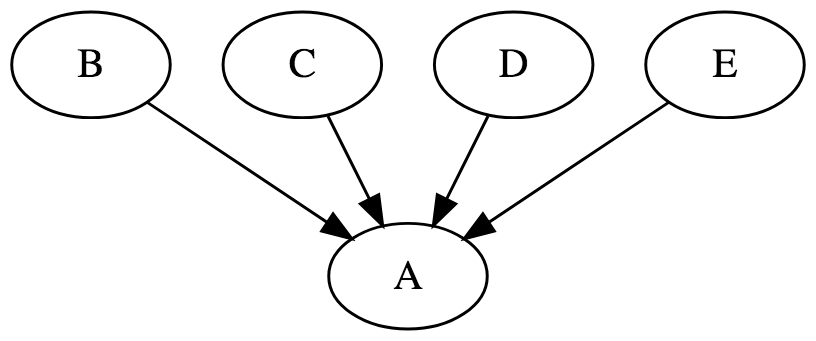
|
1 2 3 4 5 |
// B, C, D, and E run in parallel // A runs after B, C, D, and E complete A.gather(B, C, D, E); |
※”Task B”, ”Task C”, ”Task D”, ”Task E”は並列処理されます
簡単にマルチタスクの並列処理が実装できます
Step 3: Execute the Tasks
全タスクの処理が完了するまで待機します。
|
1 2 3 |
tf.wait_for_all(); // block until finish |
以上が”Cpp-Taskflow”の基本的な使い方です。
簡単にタスク管理(排他制御による各タスクのやり取り)ができます
Cpp-Taskflowで並列処理(マルチタスク)-Debug編-
並列処理のデバッグには苦労しますが、”Cpp-Taskflow”なら簡単にデバッグできます。
Debug a Taskflow Graph
名前を付けた各タスクのフロー(並列処理するタイミングなど)を可視化することができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
// the only include you need #include "../taskflow/taskflow.hpp" int main(){ tf::Taskflow tf; tf::Task A = tf.emplace([] () {}).name("A"); tf::Task B = tf.emplace([] () {}).name("B"); tf::Task C = tf.emplace([] () {}).name("C"); tf::Task D = tf.emplace([] () {}).name("D"); tf::Task E = tf.emplace([] () {}).name("E"); A.precede(B, C, E); C.precede(D); B.precede(D, E); tf.dump(std::cout); return 0; } |
または
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
// This example demonstrates how to use 'dump' method to inspect a taskflow graph. #include "../taskflow/taskflow.hpp" int main(){ tf::Taskflow tf; auto [A, B, C, D, E] = tf.emplace( [] () {}, [] () {}, [] () {}, [] () {}, [] () {} ); A.precede(B, C, E); C.precede(D); B.precede(D, E); A.name("A"); B.name("B"); C.name("C"); D.name("D"); E.name("E"); tf.dump(std::cout); return 0; } |
順番に解説していきます。
Name
各タスクに人間が理解しやすい名前を付けることができます。
|
1 2 3 |
tf::Task A = tf.emplace([] () {}).name("my name is A"); |
または
|
1 2 3 4 |
tf::Task A = tf.emplace([] () {}); A.name("my name is A");” |
tf::Task Aはコンピュータ用の定義です。人間用の分かりやすい名前は”name”使って付けることができます
Dump the Present Taskflow Graph
GraphVizでタスクフロー図を描画するためのコードを生成します。
|
1 2 3 |
tf.dump(std::cout); |
今回の場合、以下のコードが生成されます。
digraph Taskflow {
“A” -> “B”
“A” -> “C”
“A” -> “E”
“B” -> “D”
“B” -> “E”
“C” -> “D”
}
動作環境次第では、以下のようなコードを生成するかもしれません。
digraph Taskflow {
p0x7fc91c7e0020[label=”A”];
p0x7fc91c7e0020 -> p0x7fc91c7e0138;
p0x7fc91c7e0020 -> p0x7fc91c7e0250;
p0x7fc91c7e0020 -> p0x7fc91c7e0480;
p0x7fc91c7e0138[label=”B”];
p0x7fc91c7e0138 -> p0x7fc91c7e0368;
p0x7fc91c7e0138 -> p0x7fc91c7e0480;
p0x7fc91c7e0250[label=”C”];
p0x7fc91c7e0250 -> p0x7fc91c7e0368;
p0x7fc91c7e0368[label=”D”];
p0x7fc91c7e0480[label=”E”];
}
PCにインストール済みのGraphVizを使って、生成したコードから図を描画することができます。
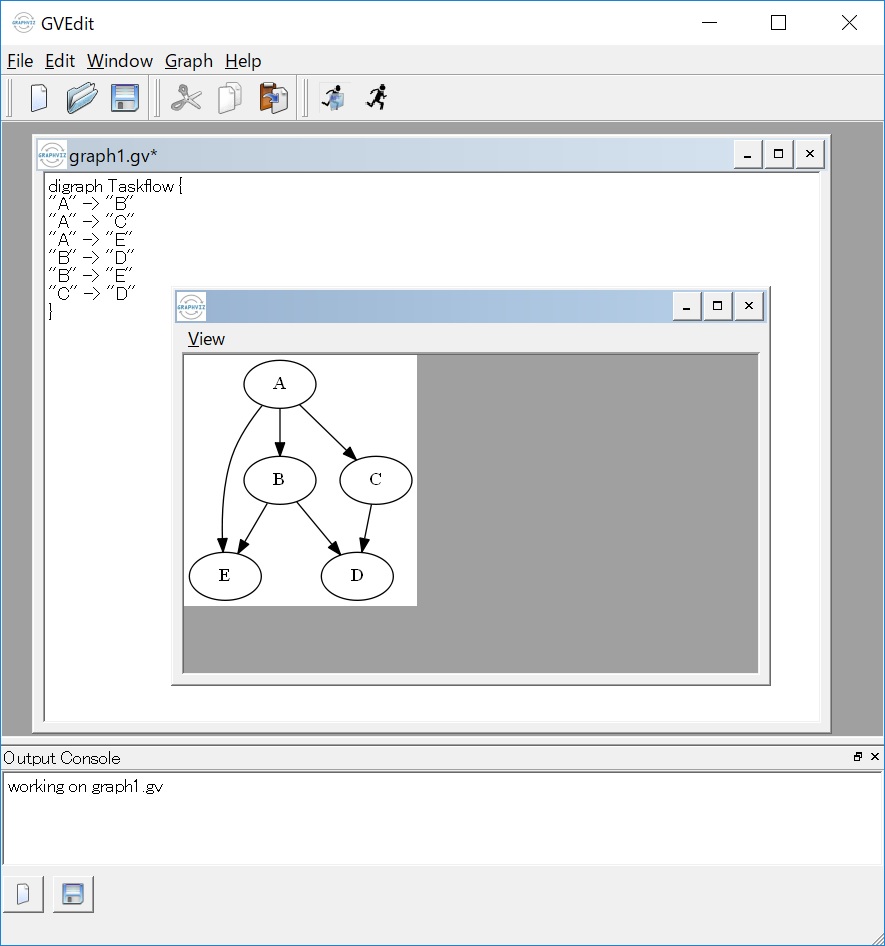
※Windows版のGraphVizで可視化しました
このように簡単にタスクフローを可視化できるため、「各タスクの不具合」や「各タスクの処理タイミングによる不具合」を早期発見 ⇒ 修正するデバッグが捗ります。
簡単にマルチタスクのフローを可視化できるため、不具合の早期発見 ⇒ 修正するデバッグが捗ります
Graphviz Onlineで図を描画する方法
GraphVizをインストールできない人がいるかも(?)しれないので、本記事では”Graphviz Online”を使って図を描画する方法を説明します。
下のボタンから”Graphviz Online”を試すことができます。
ボタンを押すとブラウザに、エディタ(左側の黒い画面)とリアルタイムプレビュー(右側の白い画面)が表示されるので、エディタ(左側の黒い画面)に先ほど生成したコードをコピペすれば、図が描画されます。
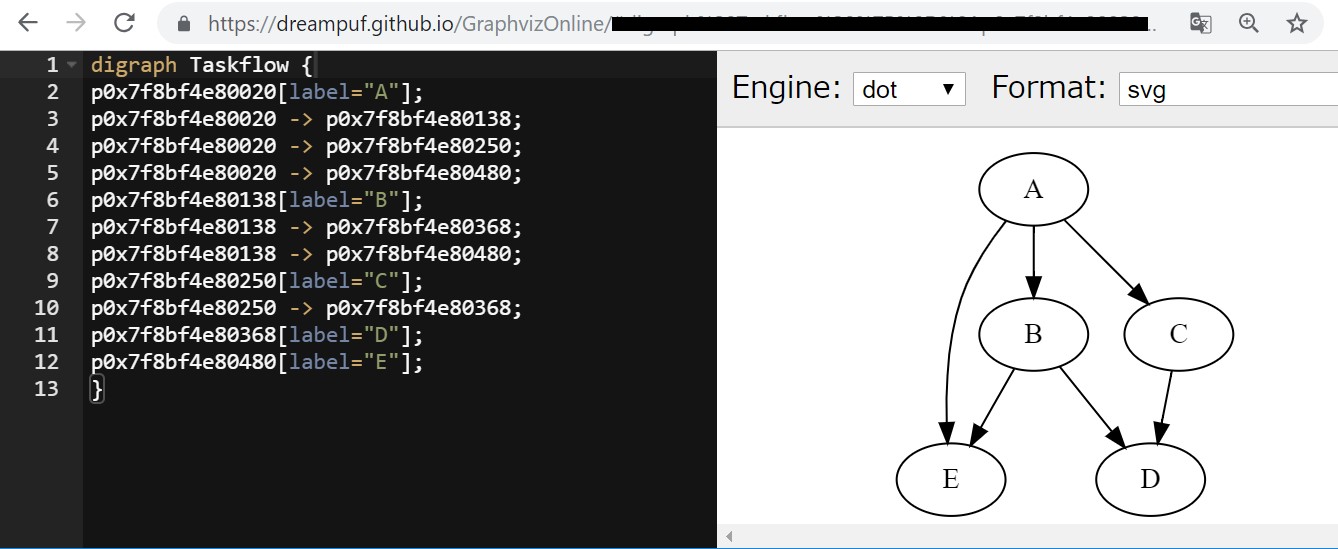
※ブラウザにはChromeを使いました
このようにオンライン(環境構築不要)でマルチタスクのフローを可視化できます。
”Graphviz Online”を使えば、環境構築不要でフロー図の描画ができます
Cpp-Taskflowで並列処理(マルチタスク)-応用編-
基礎編では「Task 〇」と表示するだけの簡単なマルチタスクを実践しました。
以降からは、簡単な演算をマルチタスクで実践します。
【課題】四則演算のマルチタスク
a = 6, b = 8, c = 0, d = 3, e = 9, f = 0, g = 0で以下の演算を行います。
g = a × b ÷ (d + e)
g = 6 × 8 ÷ (3 + 9)
g = 48 ÷ 12
g = 4
※c = a × b, f = d + e
タスクフローは以下の通りです。
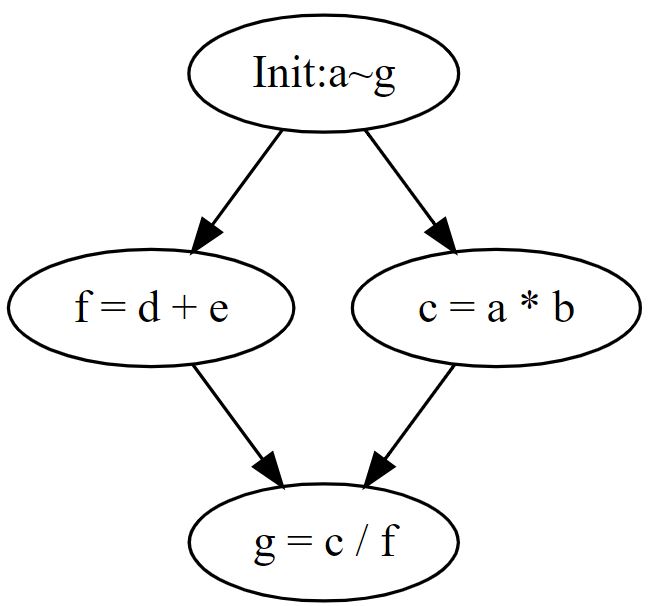
cとfの演算は並列処理することで高速化できます。
ただし、cとfの演算が完了した後にgの演算を行わないと、正しい解が得られません。
つまり、各タスクの管理(演算タイミング)が重要になってきます。
この課題を”Cpp-Taskflow”でスマートに解決します!
マルチタスクプログラムを実装するときは以下のことを検討します。
- どんな処理をタスクにするか?
- 並列処理が可能なタスクはどれか?
- 各タスクの管理(演算タイミング)は正しいか?
マルチタスクプログラム❶ -sample1.cpp-
基礎編で学んだことを活かして、最初に作成したソースコード(sample1.cpp)が以下です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
#include "../taskflow/taskflow.hpp" int main(){ tf::Taskflow tf; int a, b, c; int d, e, f; int g; // Create A~D task auto [A, B, C, D] = tf.emplace( [&a, &b, &c, &d, &e, &f, &g] () { std::cout << "==== Task A ====" << std::endl; a = 6, b = 8, c = 0; d = 3, e = 9, f = 0; g = 0; std::cout << "Init Param" << std::endl; std::cout << "a = " << a << std::endl; std::cout << "b = " << b << std::endl; std::cout << "d = " << d << std::endl; std::cout << "e = " << e << std::endl; }, [&a, &b, &c] () { std::cout << "==== Task B ====" << std::endl; c = a * b; std::cout << "c = a * b" << std::endl; std::cout << "c = " << c << std::endl; }, [&d, &e, &f] () { std::cout << "==== Task C ====" << std::endl; f = d + e; std::cout << "f = d * e" << std::endl; std::cout << "f = " << f << std::endl; }, [&c, &f, &g] () { std::cout << "==== Task D ====" << std::endl; g = c / f; std::cout << "g = c / f" << std::endl; std::cout << "g = " << g << std::endl; } ); // Precede A.precede(B); // B runs after A A.precede(C); // C runs after A B.precede(D); // D runs after B C.precede(D); // D runs after C // debug A.name("Init a~g"); B.name("c = a * b"); C.name("f = d + e"); D.name("g = c / f"); tf.dump(std::cout); // block until finished tf.wait_for_all(); // work of main() std::cout << "==== main ====" << std::endl; std::cout << "g - 2 = " << g - 2 << std::endl; return 0; } |
各タスクが引数をもっている以外は、基礎編で学んだ内容ですね。
基礎が大事です!
マルチタスクプログラム❷ -sample2.cpp-
sample1.cppの可読性の向上を考慮して改良したもの(sample2.cpp)が以下です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
#include "../taskflow/taskflow.hpp" int main(){ tf::Taskflow tf; int a, b, c; int d, e, f; int g; // Create A~D task tf::Task A = tf.emplace([](){}).name("Init a~g"); tf::Task B = tf.emplace([](){}).name("c = a * b"); tf::Task C = tf.emplace([](){}).name("f = d + e"); tf::Task D = tf.emplace([](){}).name("g = c / f");; // Work of A~D task A.work([&a, &b, &c, &d, &e, &f, &g] () { std::cout << "==== Task A ====" << std::endl; a = 6, b = 8, c = 0; d = 3, e = 9, f = 0; g = 0; std::cout << "Init Param" << std::endl; std::cout << "a = " << a << std::endl; std::cout << "b = " << b << std::endl; std::cout << "d = " << d << std::endl; std::cout << "e = " << e << std::endl; }); B.work([&a, &b, &c] () { std::cout << "==== Task B ====" << std::endl; c = a * b; std::cout << "c = a * b" << std::endl; std::cout << "c = " << c << std::endl; }); C.work([&d, &e, &f] () { std::cout << "==== Task C ====" << std::endl; f = d + e; std::cout << "f = d + e" << std::endl; std::cout << "f = " << f << std::endl; }); D.work([&c, &f, &g] () { std::cout << "==== Task D ====" << std::endl; g = c / f; std::cout << "g = c / f" << std::endl; std::cout << "g = " << g << std::endl; }); // Precede A.precede(B); // B runs after A A.precede(C); // C runs after A B.precede(D); // D runs after B C.precede(D); // D runs after C // debug tf.dump(std::cout); // block until finished tf.wait_for_all(); // work of main() std::cout << "==== main ====" << std::endl; std::cout << "g - 2 = " << g - 2 << std::endl; return 0; } |
コードの行数は少し増えましたが、可読性が良くなったと思いませんか?
好みもありますが、各タスクの生成と処理を同時に書くと、可読性が悪くなる印象を受けました。
また、事前に検討したタスクフロー図(設計図)に従い、ソースコードを作成するので…
【Cpp-Taskflowによるソースコード作成手順】
- 各タスクに名前を付ける
- 各タスクの処理を書く
という流れで作成する方が、読み手・書き手どちらにも理解しやすいソースコードになります。
可読性の良いソースコードを作成することは、チームメンバーだけでなく”未来の自分”のためにもなります!
マルチタスクプログラム➌ -sample3.cpp-
sample2.cppは簡単な演算しか実装していませんが、今後は各タスクに複雑な処理を実装するかもしれません。
なので、ソースコードの”拡張性”を考慮して改良したもの(sample3.cpp)を作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 |
#include "../taskflow/taskflow.hpp" // For Work B int mult(int x, int y){ return x * y; } // For Work C int add(int x, int y){ return x + y; } // For Work D int divs(int x, int y){ return x / y; } // For Work main() int sub(int x, int y){ return x - y; } int main(){ tf::Taskflow tf; int a, b, c; int d, e, f; int g; // Create A~D task tf::Task A = tf.emplace([](){}).name("Init a~g"); tf::Task B = tf.emplace([](){}).name("c = a * b"); tf::Task C = tf.emplace([](){}).name("f = d + e"); tf::Task D = tf.emplace([](){}).name("g = c / f");; // Work of A~D task A.work([&a, &b, &c, &d, &e, &f, &g] () { std::cout << "==== Task A ====" << std::endl; a = 6, b = 8, c = 0; d = 3, e = 9, f = 0; g = 0; std::cout << "Init Param" << std::endl; std::cout << "a = " << a << std::endl; std::cout << "b = " << b << std::endl; std::cout << "d = " << d << std::endl; std::cout << "e = " << e << std::endl; }); B.work([&a, &b, &c] () { std::cout << "==== Task B ====" << std::endl; c = mult(a, b); std::cout << "c = a * b" << std::endl; std::cout << "c = " << c << std::endl; }); C.work([&d, &e, &f] () { std::cout << "==== Task C ====" << std::endl; f = add(d, e); std::cout << "f = d + e" << std::endl; std::cout << "f = " << f << std::endl; }); D.work([&c, &f, &g] () { std::cout << "==== Task D ====" << std::endl; g = divs(c, f); std::cout << "g = c / f" << std::endl; std::cout << "g = " << g << std::endl; }); // Precede and gather A.precede(B, C); // A run before B, C (A -> B, A -> C) D.gather(B, C); // D runs after B, C (B -> D, C -> D) // debug tf.dump(std::cout); // block until finished tf.wait_for_all(); // work of main() std::cout << "==== main ====" << std::endl; std::cout << "g - 2 = " << sub(g, 2) << std::endl; return 0; } |
sample2とsample3の違いは、各タスクの処理を”関数化”している点です。
簡単な四則演算だと関数化する旨味は少ないですが、複雑な処理(アルゴリズム)でも”関数化”しておけば、ソースコードの”拡張性”および”可読性”が向上します。
また、チーム開発では、関数やクラス毎に担当者(チームメンバ)を割り振って開発する方が開発効率が向上します。
あと好みもありますが、”Precede”や”Gather”は【1 on 1】よりも【1 on N】または【N on 1】で書いた方が「並列処理」していることを直観的に理解しやすい印象を受けました。
- 処理を意味のある単位で”関数化”することで、ソースコードの”拡張性”と”可読性”が向上します
- 関数やクラス毎に担当者を決めて分散開発する方が開発効率が良いです
ビルドと動作確認
”Cpp-Taskflow|GitHub”をクローン生成あるいはダウンロードすると、以下の場所に”taskflow.hpp”があります。
cpp-taskflow/taskflow/taskflow.hpp
”Cpp-Taskflow”は”ヘッダーオンリーなライブラリ”なので、”taskflow.hpp”をインクルードするだけで使うことができます。
本記事で説明したソースコードは、以下の記事で紹介したWSL(Windows Subsystem for Linux)で動作確認しています。

※C++17がビルドできる環境ならWindows/Linuxどちらでも動きます。
ソースコードのビルドから実行までを順番に説明していきます。
前準備
以下のコマンドで前準備を行います。
git clone https://github.com/cpp-taskflow/cpp-taskflow.git
cd cpp-taskflow/
mkdir Myproject
cp -r taskflow Myproject/include/
本記事で説明したソースコード(sample3.cppなど)を”Myproject”に保存します。
ビルド&実行
以下のコマンドで”Myproject”に移動します。
cd Myproject
sample3.cppを以下のコマンドでビルドします。
g++ sample3.cpp -std=c++17 -O2 -pthread -o CppTaskflow_Sample3
なお、本記事で説明したソースコードは”taskflow.hpp”を相対パスでインクルードしていますが、以下のように絶対パスでインクルードしたとします。
|
1 2 3 4 |
// #include "../taskflow/taskflow.hpp" #include <taskflow/taskflow.hpp> |
その場合は、以下のコマンドでビルドします。
g++ sample3.cpp -I include/ -std=c++17 -O2 -pthread -o CppTaskflow_Sample3
CppTaskflow_Sample3という実行ファイルが生成できたらビルド成功です。
以下のコマンドで実行します。
./CppTaskflow_Sample3
makefile
ビルドおよび実行を効率的に実施するために、makefileを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# compile option CFLAGS = -std=c++17 # include path INCLUDE = include/ # C++(cpp) source files SOURCES = sample3.cpp # Target TARGET = CppTaskflow_Sample3 all: $(CXX) $(SOURCES) -I $(INCLUDE) $(CFLAGS) -o $(TARGET) -O2 -pthread # g++ sample3.cpp -I include/ -std=c++17 -O2 -pthread -o CppTaskflow_Sample3 run: ./$(TARGET) clean: rm -f $(TARGET) |
ビルドするソースコードを変更するときは”SOURCES”を書き換え、実行ファイル名を変更するときは”TARGET”を書き換えます。
以下のコマンドでビルド
make
以下のコマンドで実行
make run
以下のコマンドで実行ファイルの削除
make clean
一連の流れを実施したときのターミナル画面は以下の通りです。
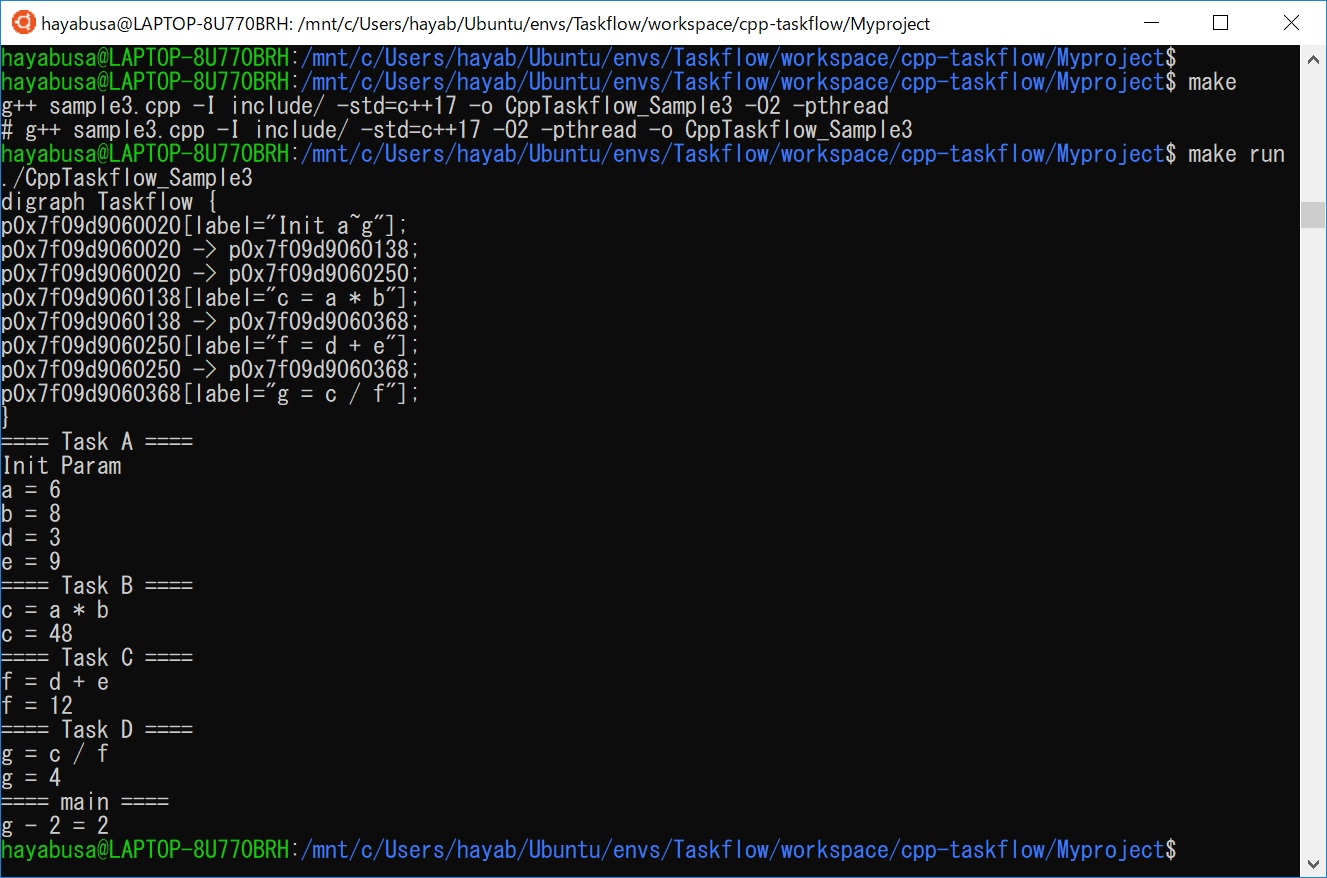
ちゃんと以下の演算ができていますね(*・ω・)ノ♪
g = a × b ÷ (d + e)
g = 6 × 8 ÷ (3 + 9)
g = 48 ÷ 12
g = 4
※c = a × b, f = d + e
最後に”タスク D”が算出した「g = 4」に対し、main関数で「g – 2 = 2」の演算をしました。
(これで、main関数とタスク間で数値のやり取りができることを確認しました)
makefileでコマンドを自作することで、ビルドなどを効率良く実施できます
まとめ
長文読解お疲れさまでした。本記事は以下の【文章構成】で説明しました。
【文章構成】
- 前編:マルチタスク・排他制御などの情報処理技術の説明
- 後編:マルチタスクプログラミングの実践 -基礎から応用まで-
本記事を一読しただけでは、よく分からない!という人でも、本記事を繰り返し読み、手を動かしながらソースコードの動作を理解していけば…
C++でマルチタスクを実装できるようになります!
本記事をきっかけに…


という人が増えると嬉しいです(*・ω・)ノ♪
(後編 完)
おまけ -メッセージとおすすめの書籍-
時間に余裕のある人は読んでみてね↓
メッセージ
フクロウの”くるる”が笑顔で呟く
さっきまで笑顔だっったのに、今度は少し悲しい表情で呟く

表情が”くるくる”変わって可愛い…!
”くるるちゃん”のように、落ち込んでる人いますか?
大丈夫です!これから学べば良いだけの話です!むしろ、この記事で勉強できてラッキーでしたね(*・ω・)ノ♪
本記事、実は後編の内容のみを書く予定でした(サンプルコードもsample1.cppだけ説明して終わる予定でした)。
しかし…

という人をサポートしたい!という想いから、一気に書き上げました(結構書くの大変でした。。)
そのため、ライブラリの使い方だけでなく”考え方”や”マインド”なども書いたことで、長文になってしまいましたが、読み易くなるように最大限配慮したつもりです。。

本記事を読んだ”くるるちゃん”のように落ち込んだ後、直ぐに立ち直って貪欲に学んでほしいと思います!応援してます!!
おすすめの書籍
うずうず…”くるる”が羽毛を揺れしながら呟く
はい!「もっと勉強したい!」というモチベーションの高い人のために勉強方法や本を紹介!
基本情報技術者試験
情報処理技術やIT用語の理解に不安のある人は、基本情報技術者試験を受験し、実力を把握するのが良いと思います。
勉強時間を確保できない!という人でも「基本情報技術者試験の参考書」を一読して理解を深め、IT用語の辞書として手元に置いておくと良いですよ。
以下の参考書は、イラスト多めで読みやすい良本です。


※動物好きなので、イメージ&クレバー方式の本をメインに使ってました
実装テクニック
本記事でソースコードの”可読性”や”拡張性”という単語を使いましたが、私自身の言葉を使えば…
『読み手や使い手のことを想ってソースコードを書くのが正解』
というのが私の思想です。
色々な人が作成したソースコードを眺め、自身も沢山コードを書いて…色々と苦悩しながら行き着いた先は”シンプルなコード”でした。
ここでいう”シンプルなコード”というのは、”短いコード”という意味ではなく…という説明をすると長くなるので『リーダブルコード 』を読んでください!
より良いコードを書くためのシンプルで実践的なテクニックを学べる良本です。

ソフトウェア設計
本記事では、処理の流れを意識したソースコードを書いたり、処理の一部を”関数化”することで、ソースコードの”可読性”や”拡張性”を向上させました。
また、事前にソフトウェア設計を行い、クラス化などを検討した上で実装した場合も、”可読性”や”拡張性”が向上します。
”ソフトウェア設計”や”UML”が学べる記事を紹介します(記事内で本の紹介もあります)。


(完)