こんにちは。
現役エンジニアの”はやぶさ”@Cpp_Learningです。最近は Pytorch を使って深層学習を楽しんでいます。
今回はPyTorchをscikit-learnのような使い心地にするライブラリ skorch を紹介します。
Contents
skorchとは
skorchとはPyTorchをラップしてscikit-learnと完全互換させた深層学習ライブラリです。
Ecosystem | PyTorch では以下のように紹介しています。
skorch is a high-level library for PyTorch that provides full scikit-learn compatibility.
skorchの公式GitHub だと以下のように説明しています。
A scikit-learn compatible neural network library that wraps PyTorch.
skorchを使うモチベーション
scikit-learnやKerasユーザーがPytorchを使うとき、以下のような不満をもつ(戸惑う)人がいると思います。
- 学習コードが冗長的
- 推論コードも冗長的
Pytorchの魅力の1つは学習用のループ処理などを柔軟に書けることです。しかし、柔軟ゆえにコードがユニークになりがちです。
またPytorchではモデルに対し、学習/推論を切り替える必要があります(下記コード参照)。
|
1 2 3 4 |
# 学習用 model.train() # 推論用 model.eval() |
なので…

とフクロウの”くるる”@kururu_owl は感じているようです。
skorchを使えば、Pytorchで設計したニューラルネットワークに対し、scikit-learnのようにmodel.fit()で学習, model.predict()で推論という単純明快なコードになります。
実践!skorch
色々と言葉で説明するより、コード見た方が理解しやすいので、以降からコードを交えてskorchの基本的な使い方を紹介します。
インストール
使用するライブラリ一覧は以下の通りです。
- scikit-learn 0.22.1
- torch 1.4.0
- skorch 0.7.0
※Google Colaboratoryで動作確認しました(2020/03/14)
Google Colaboratoryなら、以下のコマンドでインストールすれば環境構築完了です。
pip install skorch
以降からソースコードを書いていきます。
Import
最初はimportから
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import pickle import numpy as np import matplotlib.pyplot as plt import torch from torch import nn import torch.nn.functional as F from sklearn.manifold import TSNE from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report, accuracy_score from skorch import NeuralNetClassifier from skorch.callbacks import Callback, Checkpoint, EarlyStopping from skorch.dataset import CVSplit torch.manual_seed(0); |
データセット作成
make_classificationを使って適当な2値分類用のデータセットを作成します。
- サンプル数:300
- クラス数:2
- 特徴量(パラメータ数):5
- 乱数シード:固定
このデータセットをtrain用/test用で分割(train:test = 7:3)するコードが以下です。
|
1 2 3 4 5 6 7 8 9 10 11 |
# make dataset x, y = make_classification( n_samples=300, n_classes=2, n_features=5, # scale=[10, 10, 20, 20, 20], random_state=0 ) # split dataset (train:test = 7:3) x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=42) |
make_classificationの使い方については、以下が参考になります。
t-SNEで次元圧縮して可視化
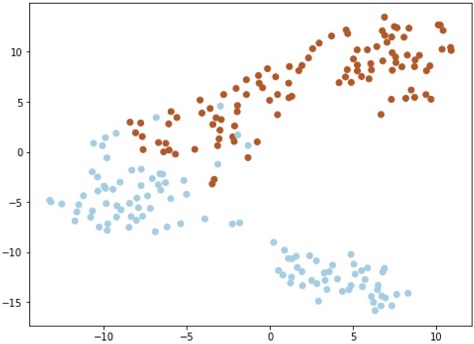
trainデータを可視化してみます。ただし、特徴量が5次元なので、t-SNEで2次元に圧縮してから可視化します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
def plot_tsne(x, y, colormap=plt.cm.Paired): '''Visualize features with t-SNE''' plt.figure(figsize=(8, 6)) # clean the figure plt.clf() tsne = TSNE() x_embedded = tsne.fit_transform(x) plt.scatter(x_embedded[:, 0], x_embedded[:, 1], c=y, cmap=colormap) # plt.xticks(()) # plt.yticks(()) plt.show() # Visualize features plot_tsne(x_train, y_train) |
ニューラルネットワーク設計
ニューラルネットワーク設計では、Pytorchのコードがそのまま使えます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
class Net(nn.Module): def __init__(self, input=5): super(Net, self).__init__() self.layer1 = nn.Linear(input, 100) self.layer2 = nn.Linear(100, 200, bias=True) self.layer3 = nn.Linear(200, 10, bias=True) self.layer4 = nn.Linear(10, 2, bias=True) def forward(self, x): x = x.float() x = F.relu(self.layer1(x)) x = F.relu(self.layer2(x)) x = F.relu(self.layer3(x)) x = self.layer4(x) output = F.softmax(x, dim=-1) return output |
学習
ハイパーパラメータをセットしたmodelを定義し、model.fit()で学習します。簡単ですね!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
monitor = lambda Net: all(Net.history[-1, ('train_loss_best', 'valid_loss_best')]) # set param(make trainer) model = NeuralNetClassifier( Net, max_epochs=100, lr=0.01, warm_start=True, # optimizer=torch.optim.Adam, optimizer=torch.optim.SGD, optimizer__momentum=0.9, iterator_train__shuffle=True, callbacks=[Checkpoint(), EarlyStopping()], # train_split=CVSplit(cv=10, stratified=True, random_state=0) ) # learn model.fit(x, y) |
 ※自動で学習時のloss/valの変化が表示されます(上図はmax_epochs=10のとき)
※自動で学習時のloss/valの変化が表示されます(上図はmax_epochs=10のとき)
check point や early stop も設定できます。
今回は分類なので NeuralNetClassifier を使いましたが、回帰の場合は NeuralNetRegressor を使います
推論と評価
model.predict()で推論します。簡単ですね!
|
1 2 3 4 5 6 7 |
# predict y_pred = model.predict(x_test) # print(y_test-y_pred) # 真値と予測値の差分 # print precision, recall, f1-score, support print(classification_report(y_test, y_pred)) print("score:", accuracy_score(y_test, y_pred)) |
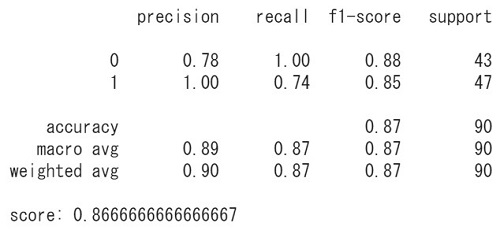
modelの評価には classification_report を使いました(スコアだけなら accuracy_score でもOK)。
skorchを使えば、Pytorchで設計したニューラルネットワークに対し、scikit-learnのように単純明快なコードで学習/推論ができます
モデルの保存と読込み
以下のコードでmodelの保存と読込みができます。
|
1 2 3 4 5 6 7 8 |
# save model model_file = "./best_model.pkl" with open(model_file, 'wb') as f: pickle.dump(model, f) # load model with open(model_file, mode='rb') as f: best_model = pickle.load(f) |
ロードしたモデルで推論
学習にも評価にも未使用なデータに対し、ロードしたモデルによる分類をしてみます。
|
1 2 3 4 5 6 |
# 適当なデータを作成 my_data = np.array([[1, 2, 3, 4, 5]]) # 推論 my_pred = best_model.predict(my_data) print("result:", my_pred) # result is 0 or 1 |
※2値分類なので、結果は ”0” または ”1” で出力されます。
以上がskorchの基本的な使い方です。
【補足】パイプラインやグリッドサーチもできる
skorchを使えば、scikit-learnのpipeline(パイプライン)やGridSearch(グリッドサーチ)のコードを書くこともできます。
最後にskorchを紹介している日本語の記事を紹介します。
まとめ
skorch の基本的な使い方をソースコード付きで説明しました。
PyTorchで”サッと”ネットワーク設計してscikit-learnライクな学習/推論ができるので、とても楽だと感じました。
PyTorchの学習コードをスッキリ書ける pytorch-lightning などもあります。

タスクに応じて、使い分けるのも良いかもしれませんね。