こんにちは。
現役エンジニアの”はやぶさ”@Cpp_Learningです。仕事でもプライベートでも機械学習で色々やってます。
今回は『時系列データと機械学習 -入門から実践まで-』について書きます。
本記事は以下の文章構成なので、好きな所から読んで下さい。
- 第0部:時系列データとseglearnの概要説明
- 第1部:時系列データと機械学習 -入門編-
- 第2部:時系列データと機械学習 -実践編-
- 第3部:おまけ -本ブログのサポートについて-
※時系列データに機械学習を適用するときに便利なライブラリ seglearn をフル活用しました
Contents
時系列データとseglearnについて
実践の前に時系列データと seglearn について簡単な説明をしておきます。
時系列データの扱い方
時系列データとは?どんな前処理をするのか?などについては、以下の記事で説明しました。
なので上記の記事を読んでから本記事を読むことをオススメします。
本記事のメインは『時系列データの前処理から学習・推論までをハンズオン形式で学べるチュートリアル』です。
seglearnとは
seglearnについて、公式では以下のように説明しています。
This project is an sklearn extension for machine learning time series or sequences. It provides an integrated pipeline for segmentation, feature extraction, feature processing, and a final estimator compatible with sklearn model evaluation and parameter optimization tools. Seglearn provides a flexible approach to multivariate time series and contextual data for classification, regression, and forecasting problems. Support and examples are provided for learning time series with classical machine learning and deep learning models.
引用元:seglearn公式
翻訳サービスの DeepL を使って日本語にしたものが以下です。
このプロジェクトは、時系列や系列を機械学習するためのsklearnの拡張機能です。これは、セグメンテーション、特徴抽出、特徴処理、およびsklearnモデル評価およびパラメータ最適化ツールと互換性のある最終推定器のための統合されたパイプラインを提供します。Seglearnは、分類、回帰、予測問題のための多変量時系列や文脈データへの柔軟なアプローチを提供します。古典的な機械学習や深層学習モデルを用いた時系列学習のためのサポートと例が提供されています。
DeepLすごい!さらに自分の言葉でコンパクトに言い換えると…
seglearnとは 時系列データのセグメンテーションから特徴抽出、学習までのパイプライン化が柔軟かつ簡単に実現できるsklearnの拡張機能 です。
入門!時系列データと機械学習 -seglearnチュートリアル-
seglearn の基本的な使い方を交えて『時系列データと機械学習 -入門編-』を説明します。
インストール
まずは、以下のコマンドで seglearn をインストールします(2020/03/29時点 ver 1.1.1)
pip install -U seglearn
以降からソースコードを書いていきます。
時系列データ作成
まずは適当な時系列データを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 |
import pandas as pd import matplotlib.pyplot as plt import numpy as np t = np.arange(5000) / 100 x = np.sin(t) * t * 2.5 + t * t plt.plot(t,y) plt.xlabel("[sec]") plt.ylabel("[m/s^2]") plt.grid(True) |
セグメンテーション
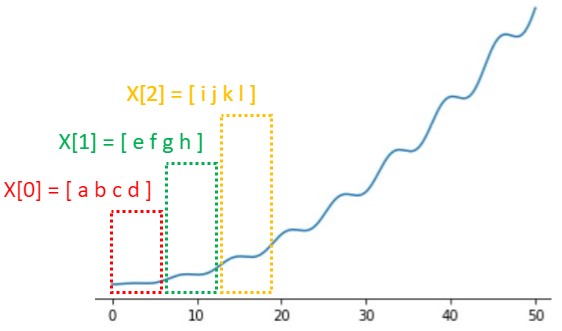
ここでいうセグメンテーションとは、以下のようにデータを区分けするという意味です。
seglearnを活用すれば、以下のコードで簡単にセグメンテーションを実現できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from seglearn.transform import SegmentX # remember for a single time series, we need to make a list xs = [x] # segmentation segment = SegmentX(width=4, overlap=0) X = segment.transform(xs) print(X[0][0]) # [0. 0.00035 0.00139993 0.00314966] print(X[0][1]) # [0.00559893 0.0087474 0.0125946 0.01714 ] print(X[0][2]) # [0.02238294 0.02832267 0.03495835 0.04228903] # print(X) |
- セグメントテーションしたいデータをリスト化(コードp4参照)
- 区分けする幅(width)は任意に変更できる(コードp7参照)
セグメンテーション(オーバーラップあり)
下図のようにオーバーラップを考慮してセグメンテーションしたいときもあります。
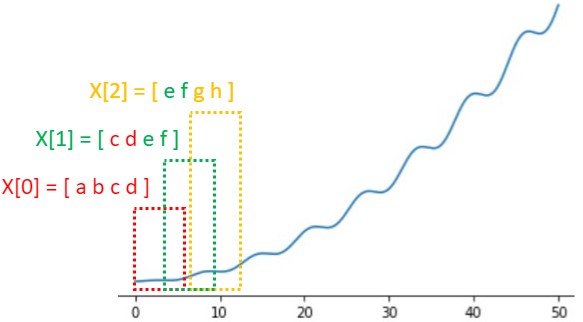
そんなときは、以下のコードを使います。
|
1 2 3 4 5 6 7 |
# segmentation segment = SegmentX(width=4, overlap=0.5) # overlapfloat range [0,1] X = segment.transform(xs) print(X[0][0]) # [0. 0.00035 0.00139993 0.00314966] print(X[0][1]) # [0.00139993 0.00314966 0.00559893 0.0087474 ] print(X[0][2]) # [0.00559893 0.0087474 0.0125946 0.01714 ] # print(X) |
- オーバーラップ(overlap)の範囲を任意に変更できる(コードp2参照)
- オーバーラップの範囲は0~1で設定
- overlap=0.5とすると1つ前のデータを50%オーバーラップ
XとYをペアでセグメントテーション
教師あり学習でデータ:Xを分類をするときは、ラベル:Y(教師データ)が必要です。
セグメンテーションしたデータ:Xに対し、後からラベル付けしても良いのですが、既にラベル付けが完了しているデータセットも存在します。
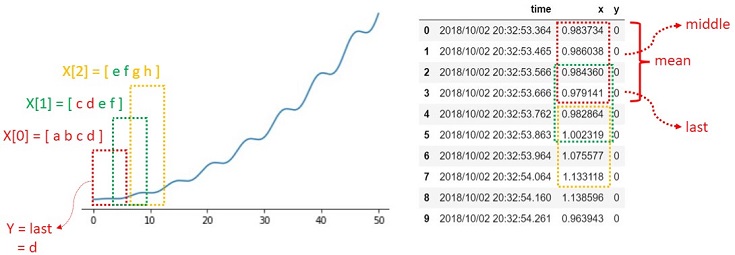
上図のように4点のデータをセグメンテーションした場合、ラベル:yも4点から1点にする必要があります。
タスク次第ですが、seglearではlast/middle/meanのどれかをラベルに設定します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from seglearn.transform import SegmentXY, last, middle, mean # remember for a single time series, we need to make a list xs = [x] # time series ys = [y] # label # segmentation seg_xy = SegmentXY(width=4, overlap=0.5, y_func=last) # y_func=last, middle or mean X, Y, _ = seg_xy.transform(xs, ys) print(X) print(Y) |
過去データ(ラグ特徴量)が現時点のデータに影響することが既知なら、y_func = last とすれば良いと思います。
- y_funcを任意に変更できる(コードp8参照)
- y_func = lastと設定するタスクが多いと思う
【前知識】特徴量抽出の基本
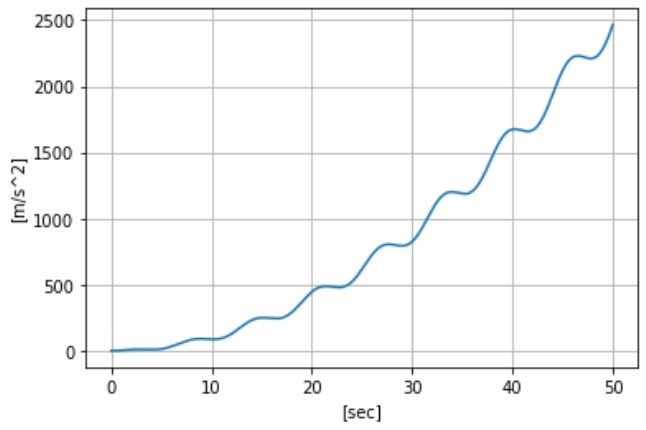
説明の都合上、以降からは ある運動時の加速度データ を対象とします(下図参照)。
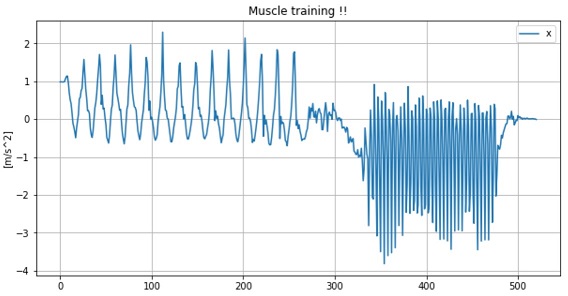
「どんな運動時のデータなのか?」については分からないと思いますが、前半と後半で明らかに違う運動をしていることは分かると思います。
ここで重要なのは「データのどの部分に着目して前半と後半を区別(クラス分け)したか?」です。


…と思った人いますか?


正解!くるるちゃんのように着目したパラメータを言語化できれば、そのパラメータを学習に使う特徴量とすればOKです。
実践!時系列データの特徴量抽出
seglearn の feature_functions を活用すれば、簡単に時系列データの特徴量を抽出できます。
例えば、セグメンテーションしたデータから最小値/最大値/平均値/標準偏差を抽出する場合、以下のようなパイプラインを作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from seglearn.feature_functions import all_features from seglearn.transform import FeatureRep from seglearn.feature_functions import mean, var, std, minimum, maximum from seglearn.pipe import Pype # remember for a single time series, we need to make a list xs = [x] # time series ys = [y] # label # set features fts = {'min': minimum, 'max': maximum, 'mean': mean, 'std': std} # create a pipeline pipe = Pype([ ('seg', SegmentXY(width=4, overlap=0.5, y_func=last)), ('ftr', FeatureRep(features=fts)) # extracts features ]) pipe.fit(xs, ys) print(pipe) |

以下のコードでパイプラインにデータを流し込めば、時系列データのセグメンテーションから特徴量(最小値/最大値/平均値/標準偏差)抽出まで実現できます。
|
1 2 3 |
X, Y = pipe.transform(xs, ys) |
出力Xには特徴量, Yにはラベルが格納されます。以下のコードでセグメンテーションしたデータ(n番目)の特徴量とラベルを確認できます。
|
1 2 3 4 |
print("X[0] =", X[0]) print("Y[0] =", Y[0]) # print("X[1] =", X[1]) # print("Y[1] =", Y[1]) |
X[n] = [min, max, mean, std]
Y[n] = label # 二値分類なら ”0” or ”1” など
実践!時系列データの特徴量抽出 -デフォルト編-
時系列データから、どんな特徴量を抽出するかで悩むときは、デフォルト設定がオススメです。
|
1 2 3 4 5 |
# create a pipeline pipe = Pype([ ('seg', SegmentXY(width=4, overlap=0.5, y_func=last)), ('ftr', FeatureRep()) # default ]) |
実践!時系列データの特徴量抽出 -all_features編-
all_features を使えば、より細かい特徴量を抽出することができます。
|
1 2 3 4 5 |
# create a pipeline pipe = Pype([ ('seg', SegmentXY(width=4, overlap=0.5, y_func=last)), ('ftr', FeatureRep(features=all_features())) # all ]) |
学習もパイプラインに組み込む
パイプラインに sklearn の機械学習アルゴリズムを組み込むこともできます。
以下のコードは 線形判別分析(LDA:Linear Discriminant Analysis) を組み込んだ例です。
|
1 2 3 4 5 6 7 8 9 10 |
from sklearn.ensemble import RandomForestClassifier clf = Pype([ ('segment', SegmentXY(width=4, overlap=0.5, y_func=last)), ('features', FeatureRep()), ('lda', LinearDiscriminantAnalysis(n_components=2)) ]) # learn clf.fit(xs, ys) |
フローは以下の通りです。
- 入力データ:xsをセグメンテーション
- 特徴量抽出(デフォルト設定)
- fitで学習(LDA採用)
推論
以下のコードでパイプラインにデータを流し込めば、推論結果を得ることができます。
|
1 2 3 |
Y, y_p = clf.transform_predict(xs, ys) |
出力Yがtransformしたラベル(y_func=lastを採用), y_pが推論結果です。
以上までが『時系列データと機械学習 -入門編-』でした。
(入門編 完)
実践!時系列データと機械学習 -自前データ分類-
入門編で説明した内容を踏まえ、自前の時系列データを機械学習で分類してみます。
まずは以下の記事を参考に筋トレ時の加速度データを収集してください。
※腹筋 ⇒ 背筋をnセットやること
筋トレ(データ収集)が終わったら、今度は手を動かしてソースコードを書きましょう(*・ω・)ノ♪
Jupyter Notebookで動作確認しました
Import
まずはimportから
|
1 2 3 4 5 6 7 8 9 10 11 |
import pickle import pandas as pd import matplotlib.pyplot as plt import numpy as np from sklearn.ensemble import RandomForestClassifier from seglearn.pipe import Pype from seglearn.split import temporal_split from seglearn.transform import FeatureRep from seglearn.transform import SegmentXY, last |
データ取得と可視化
以下のコードで筋トレ時の加速度データ(時系列データ)を取得します。
|
1 2 3 4 5 |
# df = pd.read_csv('./test_data/x.csv') df = pd.read_csv('./test_data/x.csv', names=['time', 'x']) # print(df.shape) # df.head() |
以下のコードで可視化します。
|
1 2 3 4 |
df.plot(figsize=(10, 5), grid=True) plt.title("Muscle training !!") # plt.xlabel("[ms]") plt.ylabel("[m/s^2]") |
上図は1セットしか筋トレできなかった私のデータです(入門編でも使った図です)
ラベル付け
腹筋データには”0”, 背筋データには”1”をラベル付けします。1セットしか筋トレしてない人は、以下のコードでラベル付けできます。
|
1 2 3 4 5 6 |
row = len(df) y = np.zeros(row, dtype=np.int16) # 全要素が"0" y[301:] = 1 # 要素300~を"1"にする # print(len(y)) # print(y) |
連続でnセット筋トレした人はエクセルなどを使って手作業でラベル付けするか、ソースコードを自作してみて下さい。
データセット作成
入門編を参考にデータを変換後、データをtrain用とtest用に分割します。
|
1 2 3 4 5 6 7 8 9 |
# dfからnumpyに変換 x = df["x"].values # seglearn用に変換 X = [x] Y = [y] # split the data along the time axis (our only option since we have only 1 time series) X_train, X_test, y_train, y_test = temporal_split(X, Y, test_size=0.3) |
testデータについて、以下の注意点があります。
- 腹筋・背筋の両データが含まれていることを確認してください
- 1セットしか筋トレしていない人は、testデータに背筋データしか含まれていない可能性があります
連続で筋トレが困難な人は、1セット目のデータをtrainデータとし、少し休んで2セット目のデータをtestデータとすると良いですよ(無理なく楽しく勉強しましょう)
パイプライン作成
以下のパイプラインを作成します。
|
1 2 3 4 5 6 7 8 |
# create a pipeline clf = Pype([ ('segment', SegmentXY(width=10, overlap=0.5, y_func=last)), # segmentation ('features', FeatureRep()), # extracts features ('rf', RandomForestClassifier(n_estimators=20)) # ML algorithm of sklearn ]) print(clf) |
- LDAではなく ランダムフォレスト(RandomForestClassifier) を採用
- 様々な機械学習アルゴリズムを試して”ベストスコア”を目指そう
- セグメンテーションの設定(width, overlapなど)も変更してOK
学習とスコア確認
以下のコードで学習とスコア確認をします。
|
1 2 3 4 5 6 7 8 |
# fit and score clf.fit(X_train, y_train) score = clf.score(X_test, y_test) print("score of test data:", score) score = clf.score(X, Y) print("score of all data:", score) |
参考までに私のベストスコアは以下でした。
score of test data: 0.9666666666666667
※筋トレ1セット目がtrainデータ、2セット目がtestデータです
推論
以下のコードで入力データに対する推論結果を得られます。
|
1 2 3 4 |
# predict y, y_p = clf.transform_predict(X, Y) print("transform Y into y(label):", y) print("predict result:", y_p) |
モデルの保存と読込み
以下のコードでモデル(パイプライン含む)の保存と読込みができます。
|
1 2 3 4 5 6 7 8 |
# save model model_file = "./seglearn_model.pkl" with open(model_file, 'wb') as f: pickle.dump(clf, f) # load model with open(model_file, mode='rb') as f: best_model = pickle.load(f) |
モデルを生成しておけば、次回からは学習せずにいきなり推論から実行できます。
ロードしたモデルで推論
本番を想定して、学習にも評価にも未使用なデータ(3セット目の筋トレデータ)に対し、ロードしたモデルによる分類をしてみます。
|
1 2 3 4 |
# predict with load model y, y_p = best_model.transform_predict(my_x, my_y) print("transform Y into y(label):", y) print("predict result:", y_p) |
以上で『時系列データと機械学習 -実践編-』も終了です。
(実践編 完)
まとめ -時系列データと機械学習-
筋トレからプログラミングまでお疲れ様でした。
大変だったと思うけど本記事で『時系列データと機械学習』を楽しく学んでくれたら嬉しいです。
くるるちゃんと同じ感想の人が沢山いると嬉しいです。
(本編 完)
おまけ -本ブログのサポートについて-
本記事の内容なら有料でも良い気がしたけど、無料公開にして多くの人に読んでもらうことを優先しました(無料でも手は抜かず、むしろ多くの手間と時間をかけて書き上げました)。
フクロウの”くるる”が丁寧にお辞儀してる姿がすごく可愛い。
もし本記事が参考になり、ブログ『はやぶさの技術ノート』をサポートしたいという人がいれば、以下の方法でサポートして頂けると嬉しいです!
- 本ブログの記事をSNS(Twitterやfacebookなど)でシェア
- ブログをやっている人ならリンクを張ってシェア
- 本ブログで紹介した本などを購入
- LINEスタンプ 購入
- 【くるるの野望ショップ】でフクロウグッズ購入
私のプロフィールにも書いていますが、学生さんや勉強したい人の”学び”を支援したいと考えています。
ブログ『はやぶさの技術ノート』では本記事も含め、多くのチュートリアル記事を無料で公開しています。SNSなどで友達にも教えてあげてほしいです!
また応援メッセージなどを頂けると、次も良い記事書きたいな!というモチベーションに繋がります。Twitterなどで気軽にコメントして頂けると嬉しいです。
(完)