こんにちは。
現役エンジニアの”はやぶさ”@Cpp_Learningです。最近、距離学習を楽しく勉強しています。
今回は、角度を用いた深層距離学習のSphereFace・CosFace・ArcFace・AdaCosについて勉強したので、備忘録も兼ねて本記事を書きます。
深層距離学習とは
深層距離学習については、以下の二つの記事で説明済みなので、本記事では簡単なイメージのみを説明します。
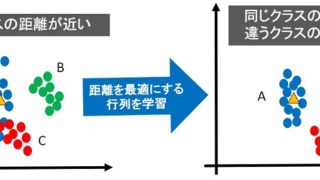
距離学習(深層距離学習含む)とは、空間に埋め込んだデータに対し、クラスが同じものは距離が近く・クラスが違うものは距離が遠くなるように学習する手法です。
最適な距離(最適な埋め込み空間の生成)により、精度の良い分類を実現するのが狙いです。
- 分類が難しいサンプル=距離が近い
- 分類が簡単なサンプル=距離が遠い
- 距離を最適化することで分類が簡単になる(分類精度が向上)
角度と距離学習
本記事のタイトルにも入っている「角度」が今回のキーワードです。ここでは角度と距離の関係について説明します。
角度を用いない距離学習の概要
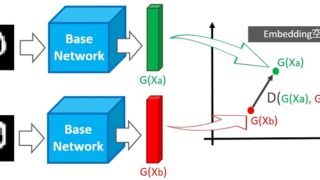
最初に角度を用いない距離学習の概要を説明します。下図の点A・点Bの距離を遠ざけたい場合、「距離Dを大きくすれば良い」というのは直観的にも理解しやすいと思います。
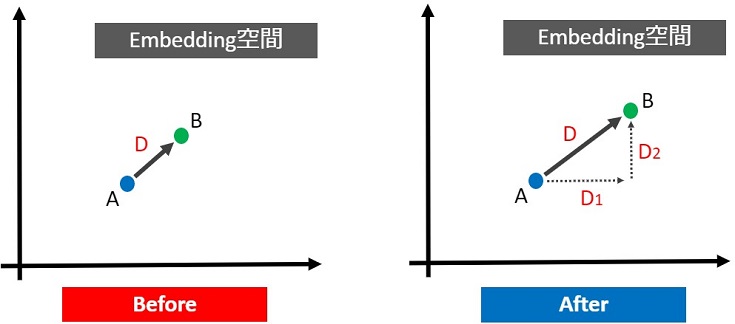
もし、Dがユークリッド距離ならば、D1・D2のどちらか、あるいは両方を大きくすれば、Dも大きくなります。
角度を用いない深層距離学習の多くはユークリッド距離関数を採用しており、最適な距離Dを実現するために距離学習用の損失関数(Center Lossなど)を使います。
角度を用いた距離学習の概要
次に角度を用いた距離学習の概要を説明します。下図の点A・点Bの距離を遠ざけたい場合、「角度θを大きくすれば良い」というのが基本的なアイデアです。
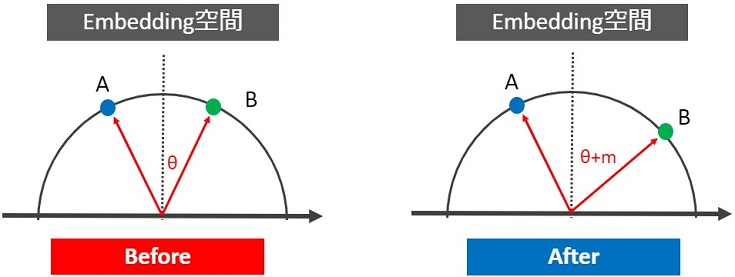
空間に埋め込んだデータ同士の角度が小さければ同じクラス、角度が大きければ違うクラスと分類できます。
角度を用いた深層距離学習の多くは角度の大小でデータ間距離を調整し、かつ最適な角度を実現するために距離学習用の損失関数(Arcfaceなど)を使います。
角度とSoftmax Loss
角度を用いた深層距離学習を理解するには、深層学習でお馴染みのSoftmax Loss関数の理解が必要不可欠です。
【Softmax Loss関数】
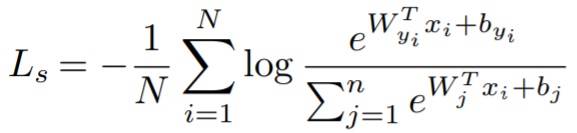
N:クラス数, W:重みベクトル, b:バイアス, Xi:CNNの出力特徴ベクトル
この式のWとXに注目します。
【内積】
b=0としたとき、この式は内積で表現できます。
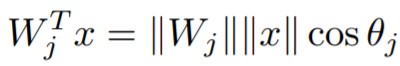
以上から、Softmax Lossにキーワードの「角度」が隠れていたことが分かります。この内積を図にしたものが以下です。
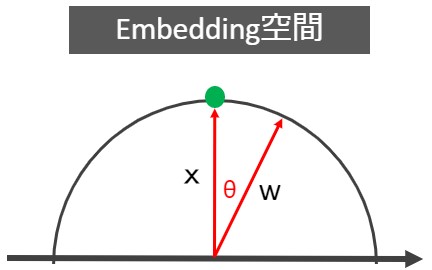
重みW はクラス数N と同じ数だけ存在し、なす角θ の大小でデータXi を分類することができます。例えば、二分類(N=2, X1~X6)なら下図のイメージです。
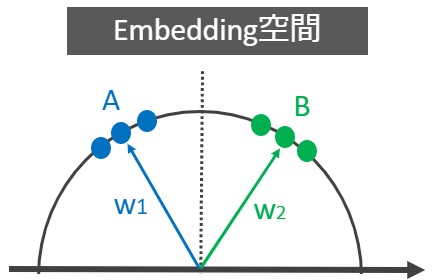
W1との角度が小さいデータをクラスA、W2との角度が小さいデータをクラスBと分類できます。
- Softmax Lossに角度(内積)が隠れていた
- データXi と重みWj とのなす角でクラスを分類
角度を用いた深層距離学習のアルゴリズム概要
ここまでの説明で、埋め込み空間に存在するデータが角度によって分類可能なことが分かると嬉しいです。続いて、角度を用いた深層距離学習のアルゴリズムを説明します。
深層距離学習の課題
まずは下図の埋め込み空間があるとします。
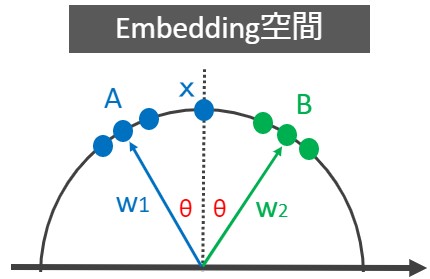 データXはW1,W2とのなす角θが等しい場所に埋め込まれています。これはクラスAとクラスBの境界線上にデータXが存在するということです。
データXはW1,W2とのなす角θが等しい場所に埋め込まれています。これはクラスAとクラスBの境界線上にデータXが存在するということです。
例えるなら、データXは「猫みたいなフクロウ or フクロウみたいな猫」という分類困難なデータということです。

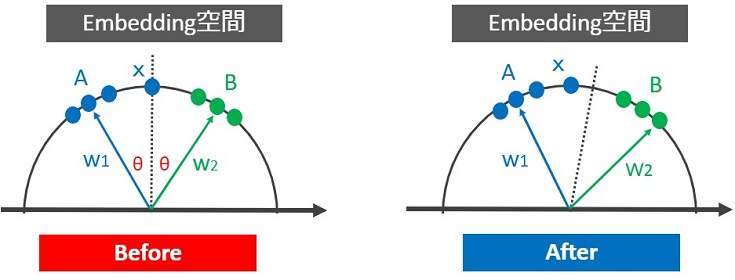
この問題を解決するのに距離学習を使います。
境界線を移動、あるいはデータXと重みW1とのなす角が小さく(W2とのなす角が大きく)なるような最適な角度を学習をすれば解決できそうです(「角度を用いた距離学習の概要」のところでアイデアの説明あり)。
ここで改めてSoftmax Loss関数と内積の式を確認します。
【Softmax Loss関数】
【内積】
このSoftmax Lossをベースに内積を組み合わせ、かつ||Wj||=1, θを大きくしたい(θ+mなど)と考えながら式変形すると SphereFace, CosFace, ArcFace を作ることができます。
【SphereFace】
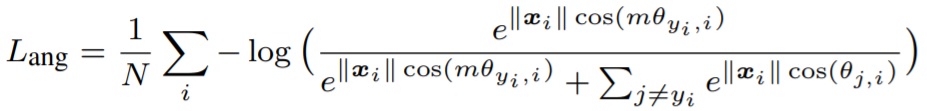
【CosFace】
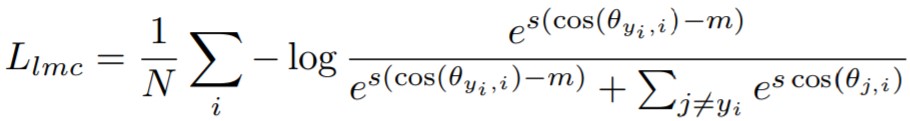
【Arcface】
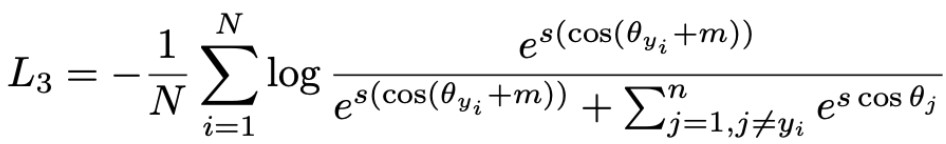
もっと詳しく知りたい人のために、以下の資料をオススメしておきます。
AdaCosとは
ArcFaceやCosFaceなどには、スケール:s, マージン:mといったハイパーパラメータがあります。
AdaCosでは、それらのハイパーパラメータを自動で設定してくれます。詳細なアルゴリズムを知りたい人は、以下の記事を参考にすると良いです。
実践!深層距離学習で画像分類 -AdaCos編-
理論の説明はここまでにして、次は実践しましょう!”ググると”角度を用いた深層距離学習に関するソースコードを見つけることができました。
Pytorchを使いたかったので、pytorch-adacos をベースにソースコードを改良し、AdaCosを実践しました。以降で解説します。
以降で解説するソースコードはGoogle Colaboratoryで動作確認しました。
Import
最初はimportから
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import os # import argparse import numpy as np import pandas as pd import math from tqdm import tqdm import joblib from collections import OrderedDict import torch import torch.nn as nn import torch.nn.functional as F from torch.nn import Parameter import torch.backends.cudnn as cudnn import torch.optim as optim from torch.optim import lr_scheduler from torchvision import datasets, models, transforms # from utils import * # from mnist import archs # import metrics |
いくつかのコードをコメントアウトしているのは、本記事のコードをGoogle Colaboratoryにコピペすれば簡単に実践できる形に修正したためです。
GPU/CPU設定
GPUが使用可能な環境ならGPUを使用し、そうでない場合はCPUを使用するように設定します。
|
1 2 3 4 |
use_cuda = torch.cuda.is_available() and True device = torch.device("cuda" if use_cuda else "cpu") |
前処理
以下の処理を行うコードを作成します。
- データセット(MNIST)のダウンロード
- transforms(画像の前処理)
- データセット作成(train_set/val_set)
- データローダ生成(train_loader/val_loader)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
train_set = datasets.MNIST( root='MNIST', train=True, download=True, transform=transforms.ToTensor()) val_set = datasets.MNIST( root='MNIST', train=False, download=True, transform=transforms.ToTensor()) train_loader = torch.utils.data.DataLoader( train_set, batch_size=128, shuffle=True, num_workers=8) val_loader = torch.utils.data.DataLoader( val_set, batch_size=128, shuffle=False, num_workers=8) |
CNN設計
Optunaでパイパーパラメータの自動チューニングしたときに結果を参考に、CNNを設計します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
class Net(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(1, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 4 * 4, 115) self.fc2 = nn.Linear(115, 84) self.fc3 = nn.Linear(84, 100) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 4 * 4) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x |
FC3層の出力ベクトルがAdaCosに入力されます(後述します)。
深層距離学習(AdaCos)クラス
本来は、metrics.pyをimportするだけで、SphereFace・CosFace・ArcFace・AdaCosを利用できますが、Google Colab上で”サクッ”と動かすために、AdaCosクラスを写経します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
class AdaCos(nn.Module): def __init__(self, num_features, num_classes, m=0.50): super(AdaCos, self).__init__() self.num_features = num_features # self.n_classes = num_classes self.s = math.sqrt(2) * math.log(num_classes - 1) self.m = m self.W = Parameter(torch.FloatTensor(num_classes, num_features)) nn.init.xavier_uniform_(self.W) def forward(self, input, label): # normalize features x = F.normalize(input) # normalize weights W = F.normalize(self.W) # dot product logits = F.linear(x, W) # add margin theta = torch.acos(torch.clamp(logits, -1.0 + 1e-7, 1.0 - 1e-7)) target_logits = torch.cos(theta + self.m) one_hot = torch.zeros_like(logits) one_hot.scatter_(1, label.view(-1, 1).long(), 1) output = logits * (1 - one_hot) + target_logits * one_hot # feature re-scale with torch.no_grad(): B_avg = torch.where(one_hot < 1, self.s * torch.exp(logits), torch.zeros_like(logits)) B_avg = torch.sum(B_avg) / input.size(0) # print(B_avg) theta_med = torch.median(theta) self.s = torch.log(B_avg) / torch.cos(torch.min(math.pi/4 * torch.ones_like(theta_med), theta_med)) # print(self.s) output *= self.s return output |
平均値算出クラス(ログ用)とaccuracy関数
同様に、utils.pyををimportするだけで、平均値算出クラスやaccuracy関数を利用できるのですが、今回は写経します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
class AverageMeter(object): """Computes and stores the average and current value""" def __init__(self): self.reset() def reset(self): self.val = 0 self.avg = 0 self.sum = 0 self.count = 0 def update(self, val, n=1): self.val = val self.sum += val * n self.count += n self.avg = self.sum / self.count def accuracy(output, target, topk=(1,)): """Computes the accuracy over the k top predictions for the specified values of k""" with torch.no_grad(): maxk = max(topk) batch_size = target.size(0) _, pred = output.topk(maxk, 1, True, True) pred = pred.t() correct = pred.eq(target.view(1, -1).expand_as(pred)) res = [] for k in topk: correct_k = correct[:k].view(-1).float().sum(0, keepdim=True) res.append(correct_k.mul_(100.0 / batch_size)) return res |
train関数
train関数を作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
def train(train_loader, model, metric_fc, criterion, optimizer): losses = AverageMeter() acc1s = AverageMeter() # switch to train mode model.train() metric_fc.train() for i, (input, target) in tqdm(enumerate(train_loader), total=len(train_loader)): input = input.to(device) target = target.to(device) feature = model(input) output = metric_fc(feature, target) loss = criterion(output, target) acc1, = accuracy(output, target, topk=(1,)) losses.update(loss.item(), input.size(0)) acc1s.update(acc1.item(), input.size(0)) # compute gradient and do optimizing step optimizer.zero_grad() loss.backward() optimizer.step() log = OrderedDict([ ('loss', losses.avg), ('acc1', acc1s.avg), ]) return log |
validate関数
validate関数を作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
def validate(val_loader, model, metric_fc, criterion): losses = AverageMeter() acc1s = AverageMeter() # switch to evaluate mode model.eval() metric_fc.eval() with torch.no_grad(): for i, (input, target) in tqdm(enumerate(val_loader), total=len(val_loader)): input = input.to(device) target = target.to(device) feature = model(input) output = metric_fc(feature, target) loss = criterion(output, target) acc1, = accuracy(output, target, topk=(1,)) losses.update(loss.item(), input.size(0)) acc1s.update(acc1.item(), input.size(0)) log = OrderedDict([ ('loss', losses.avg), ('acc1', acc1s.avg), ]) return log |
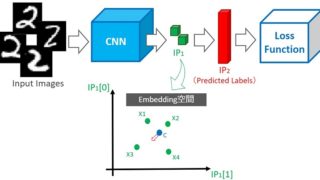
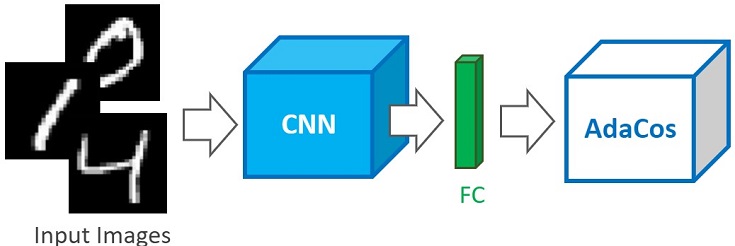
モデルのインスタンス生成
先ほど作成したNetクラスとAdaCosクラスのインスタンスを生成し、接続します。
|
1 2 3 4 5 |
model = Net().to(device) num_features = model.fc3.out_features metric_fc = AdaCos(num_features, num_classes=10).to(device) |
下図がイメージです。
epocs/オプティマイザ/スケジューラ/クロスエントロピー定義
epocs/オプティマイザ(今回はMomentum SGD)/スケジューラ(必須ではない)/CrossEntropyLossを設定します。
|
1 2 3 4 5 6 7 8 |
epochs = 100 optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.9, weight_decay=1e-4) # optimizer = optim.Adam(model.parameters(), lr=0.02) scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs, eta_min=1e-3) criterion = nn.CrossEntropyLoss().to(device) |
学習
以下のコードで学習します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
log = pd.DataFrame(index=[], columns=[ 'epoch', 'lr', 'loss', 'acc1', 'val_loss', 'val_acc1']) best_loss = float('inf') for epoch in range(epochs): print('Epoch [%d/%d]' %(epoch+1, epochs)) scheduler.step() # train for one epoch train_log = train(train_loader, model, metric_fc, criterion, optimizer) # evaluate on validation set val_log = validate(val_loader, model, metric_fc, criterion) print('loss %.4f - acc1 %.4f - val_loss %.4f - val_acc %.4f' %(train_log['loss'], train_log['acc1'], val_log['loss'], val_log['acc1'])) tmp = pd.Series([ epoch, scheduler.get_lr()[0], train_log['loss'], train_log['acc1'], val_log['loss'], val_log['acc1'], ], index=['epoch', 'lr', 'loss', 'acc1', 'val_loss', 'val_acc1']) log = log.append(tmp, ignore_index=True) log.to_csv('models_log.csv', index=False) if val_log['loss'] < best_loss: torch.save(model.state_dict(), 'model.pth') best_loss = val_log['loss'] print("=> saved best model") |
val_lossが最も小さかったモデルを保存します。
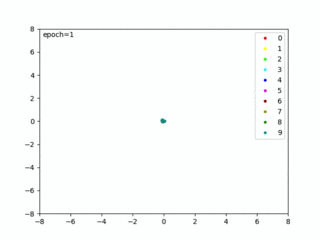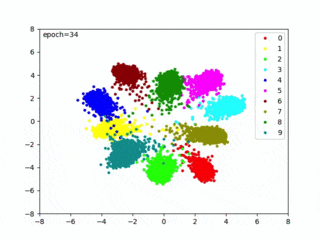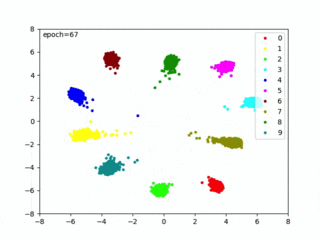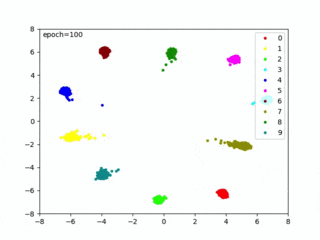
私が試したときは、71epocsでベストモデルを生成できました(下記のように表示されます)。
loss 0.0892 – acc1 99.8300 – val_loss 0.1400 – val_acc 98.7700 => saved best model Epoch [71/100]
以上で実践も完了です。
まとめ
角度を用いた深層距離学習の理論から実践まで徹底解説してみました。
理論については、既に良い資料があったのですが、本記事を読んでから各資料や論文を読むと、よりスッキリ理解できると思います。
また、PytorchでAdaCosを実践している記事は少ないと思いますので、本記事が参考になれば嬉しいです。
最後にAdaCosの良かった点をまとめます。
- CNNの最終層(FC層)を改良するだけで使える
- ArcFaceと違いハイパーパラメータを自動で設定してくれる
扱い易くて精度も良い、とても優秀な手法だと感じました。

よろしくお願いします。