こんにちは。
現役エンジニアの”はやぶさ”@Cpp_Learningです。仕事でもプライベートでも機械学習で色々やってます。
今回は機械学習のハイパーパラメータを自動調整できる tune-sklearn を使って、Pytorchモデルのパラメータ自動チューニングを実践したので、備忘録も兼ねて本記事を書きます。
Contents
Tune-sklearnとは
Tune-sklearn とは Ray Tune によるハイパーパラメータ自動チューニングを簡単に実現できるPythonパッケージです。
scikit-learn の機械学習モデルがメイン対象ですが、LightGBM や Pytorch (using Skorch) などもサポートしています。
パラメータを自動最適化できるという点で Optuna の仲間といえます(チューニング手法にベイズ最適化を選択できます)。

Skorchとは
skorch とは PyTorch を scikit-learn のような使い心地にするライブラリです。
今回は上記で紹介したソースコードにハイパーパラメータ自動チューニングを組み込んでみます。
実践!Tune-sklearnでハイパーパラメータの自動チューニング -Pytorch(using skorch)編-
Tune-sklearn(バックで動いている Ray Tune )は複数のチューニング手法(Search Algorithms)をサポートしています。
今回は以下の2手法を試してみます。
| Algorithm | search_optimization value | Summry | Wedsite | pip install |
| RandomListSearcher | “random” | Randomized Search |
built-in | |
| SkoptSearch | “bayesian” | Bayesian Optimization |
Scikit-Optimize | scikit-optimize |
インストール
以下のコマンドで必要なパッケージをインストールします。
pip install tune-sklearn ray[tune]
pip install scikit-optimize
pip install skorch
使用したい Search Algorithms 次第でインストールするパッケージが異なるので注意。今回は“bayesian”を使いたいので、scikit-optimize をインストールします。
以降からソースコードを書いていきます。
Import
最初はimportから
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import pickle import numpy as np import matplotlib.pyplot as plt import torch from torch import nn import torch.nn.functional as F from sklearn.manifold import TSNE from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report, accuracy_score from skorch import NeuralNetClassifier from skorch.callbacks import Callback, Checkpoint, EarlyStopping from skorch.dataset import CVSplit # from tune_sklearn import TuneGridSearchCV from tune_sklearn import TuneSearchCV torch.manual_seed(0); |
データセット作成
こちらの記事と同じデータセットを作成します。
|
1 2 3 4 5 6 7 8 9 10 |
# make dataset x, y = make_classification( n_samples=300, n_classes=2, n_features=5, random_state=0 ) # split dataset (train:test = 7:3) x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=42) |
可視化のコードは割愛しますが、下図のようなデータを生成できます。
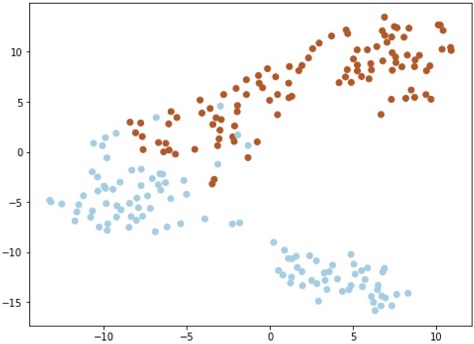
このデータを分類するモデルを生成します。
ニューラルネットワーク設計
skorch を使う場合でも、ピュアPytorchと同じコードでニューラルネットワーク設計ができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
class Net(nn.Module): def __init__(self, input=5, num_units1=100, num_units2=200): super(Net, self).__init__() self.layer1 = nn.Linear(input, num_units1) self.layer2 = nn.Linear(num_units1, num_units2, bias=True) self.layer3 = nn.Linear(num_units2, 10, bias=True) self.layer4 = nn.Linear(10, 2, bias=True) def forward(self, x): x = x.float() x = F.relu(self.layer1(x)) x = F.relu(self.layer2(x)) x = F.relu(self.layer3(x)) x = self.layer4(x) output = F.softmax(x, dim=-1) return output |
ハイパーパラメータの初期設定
以下のコードでハイパーパラメータをセットしたmodelを定義します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# set param(make trainer) model = NeuralNetClassifier( Net, max_epochs=10, lr=0.01, warm_start=True, # optimizer=torch.optim.Adam, optimizer=torch.optim.SGD, optimizer__momentum=0.9, iterator_train__shuffle=True, callbacks=[Checkpoint(), EarlyStopping()], # train_split=CVSplit(cv=10, stratified=True, random_state=0) ) |
※modelだけでなく、trainerのパラメータもセット
ハイパーパラメータ自動チューニング -Randomized Search-
まずは”Randomized Search”でパラメータチューニングしてみます。
以下コードでチューニング対象およびチューニング範囲(10 or 20を選択など)を設定します。
|
1 2 3 4 5 6 7 8 9 |
# target params params = { "lr": [0.01, 0.02, 0.03], # 0.01, 0.02 or 0.03 "max_epochs": [10, 20], # "optimizer": ['torch.optim.SGD', 'torch.optim.Adam'], "module__num_units1": [100, 200, 300], "module__num_units2": [100, 200, 300], "optimizer__momentum": [0.7, 0.8, 0.9] } |
以下のコードで自動チューニングを実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# tuner tune_search = TuneSearchCV( model, params, early_stopping=True, scoring="accuracy", search_optimization="bayesian" ) # tune params tune_search.fit(x, y) # check best params print(' Value: {}'.format(tune_search.best_score_)) print(' Params: ') for key, value in tune_search.best_params_.items(): print(' {}: {}'.format(key, value)) |
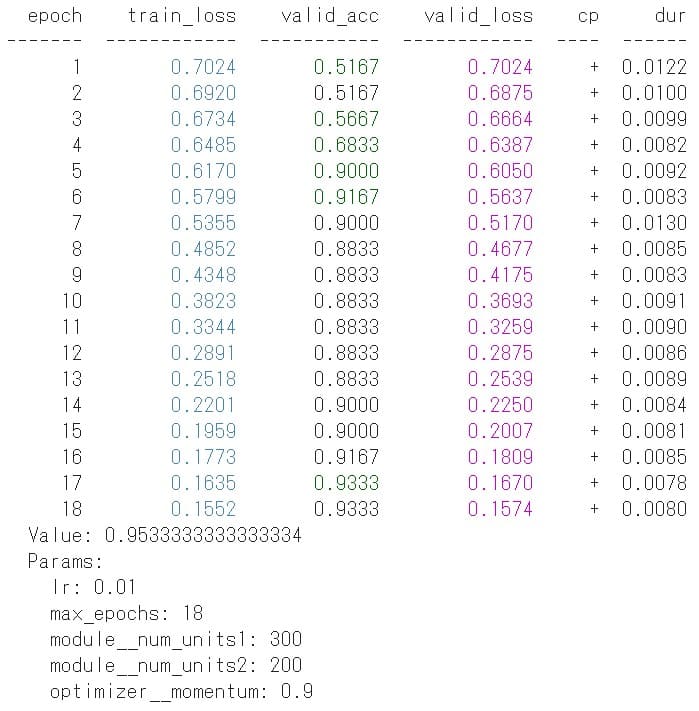
上図がチューニング結果です。
ハイパーパラメータ自動チューニング -Bayesian Optimization-
続いて”Bayesian Optimization”でパラメータチューニングしてみます。
”Randomized Search”と違い、0~0.9という範囲指定ができます。
|
1 2 3 4 5 6 7 8 9 10 |
# target params params = { "lr": [0, 0.03], "max_epochs": [0, 20], # "optimizer": ['torch.optim.SGD', 'torch.optim.Adam'], "module__num_units1": [0, 300], "module__num_units2": [0, 300], # "optimizer__momentum": [0, 0.9] # 0~0.9 "optimizer__momentum": [0.7, 0.8, 0.9] # 0.7, 0.8 or 0.9 } |
お先ほどと同じコード ”fit()” で自動チューニングを実行した結果が以下です。
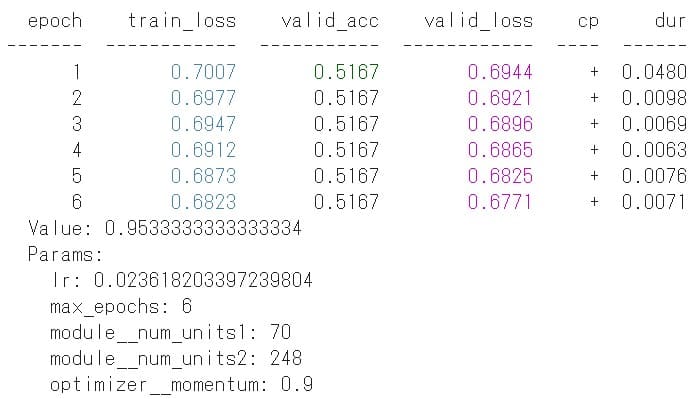
ベストパラメータで学習
チューニング結果を参考に、ベストパラメータで学習します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# set param(make trainer) best_model = NeuralNetClassifier( Net(num_units1=70, num_units2=248), max_epochs=10, lr=0.024, warm_start=True, # optimizer=torch.optim.Adam, optimizer=torch.optim.SGD, optimizer__momentum=0.9, iterator_train__shuffle=True, callbacks=[Checkpoint(), EarlyStopping()], ) # learn best_model.fit(x, y) |

上図から最終的にどんなニューラルネットワークが生成されたのかが分かります。
また max_epochs=10 で学習しましたが、チューニング結果の max_epochs=6(early_stopping=True)で十分だったかもしれません。

以上で実践終了です。
【補足】モデルの推論・評価・保存
本記事では『ハイパーパラメータ自動チューニングからベストパラメータによる学習まで』を実践しました。
さらに先のモデルの推論・評価・保存まで実践したい人は、以下の記事を参照してください(本記事の前半で紹介済み)。
おまけ -Tune-sklearn(Ray Tune)とOptunaの比較-
今回紹介した Tune-sklearn と Optuna を簡単に比較してみました(個人の感想です)
【Tune-sklearn】
- scikit-learn のような手軽さでチューニングができる
- 複数のチューニング手法(検索アルゴリズム)を選択できる
- 数字以外のチューニング([‘SGD’, ‘Adam’]の選択など)はできない
- scikit-learn や skorch と相性が良い
- Ray Tuneの全機能はサポートしていない
【Optuna】
- ベイズ最適化によるハイパーパラメータ自動チューニングに特化
- 数字以外のチューニング([‘SGD’, ‘Adam’]の選択など)もできる
- チューニングレポートをPandasのDataFrame形式で出力できる
- トライアル数以外に、時間指定(Timeout)でチューニングの打ち切りができる
scikit-learn のような手軽さでパラメータチューニングしたいなら Tune-sklearn
各種設定を柔軟にやりたいなら Optuna
各種設定を柔軟にやりたいし、色んな検索アルゴリズムを試したいなら Ray Tune
こんな感じかな。
まとめ
tune-sklearn を使い、Pytorchモデルのハイパーパラメータ自動チューニングを実践しました。

tune-sklearn というだけあって、scikit-learnと相性が良いのですが、Pytorch (using skorch) とも相性が良くて使い易かったです。
機械学習モデルのハイパーパラメータ自動チューニングの初手にtune-sklearnが良さそうだと感じました。
以下 本記事と関連のある良書の紹介。