
こんにちは。
コンピュータビジョン(『ロボットの眼』開発)が専門の”はやぶさ”@Cpp_Learningです。
『深層学習による物体検出』が好きで色んな記事を書いてます↓


特に『リアルタイム物体検出』が好きです!だんだん欲が出てきて…

ということで、今回は『MobileNet SSD』で遊んでみます。
初めにPyTorchの環境構築について書きましたので、不要な人は飛ばして下さい。
Contents
PyTorchの環境構築
今までChainerCVで『物体検出』をしてきましたが、今回はPyTorchを使います。
Chainerの環境構築については、下記の記事で紹介しています。

↑と同じ手順でPyTorchの環境構築もできます。簡単に手順を説明すると…
- Anacondaインストール
- 仮想環境 生成
- PyTorchインストール
❶と❷については上記の記事で説明済みなので、本記事では➌から説明します。
PyTorchインストール
PyTorchの公式サイトに以下の項目があります。
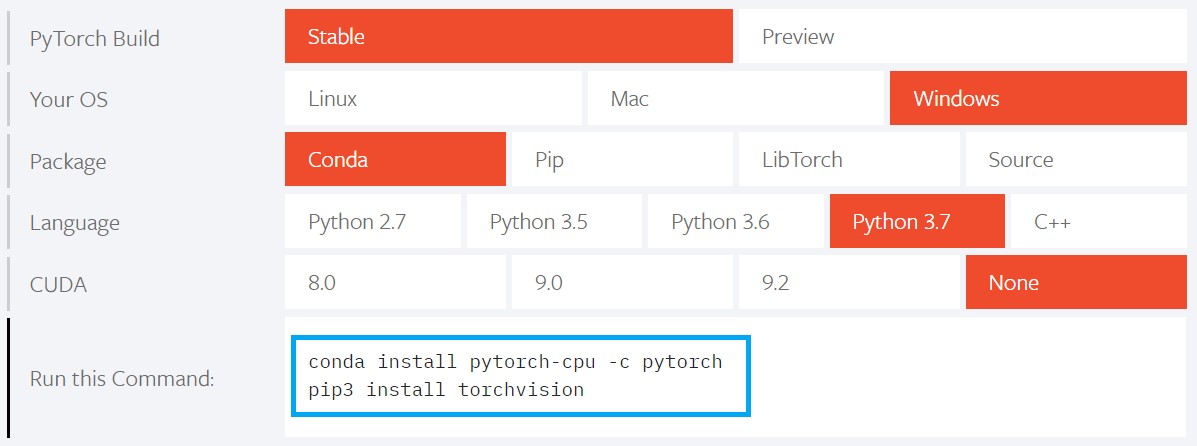
自分の使っているOSなどの環境に合わせて、各項目をクリックするとコマンドが表示されます。
例えば、上図はWindows/Anaconda/Python3.7/CPUの環境にPyTorchをインストールするときのコマンドです。
このコマンドをターミナルに打ち込めばインストール完了です(PyTorchのサポート手厚いなぁ)
以降から「MobileNet」と「SSD」について簡単に説明します。
MobileNetとは
CNN(畳み込みニューラルネットワーク)のモデルには様々な種類があり、例えばVGGと呼ばれるモデルがあります。
VGGや更に複雑なモデル構造の場合、計算量が多いため、リソースに制約のある「組込み機器」では高速処理できない!という問題があります。

というフクロウ@kururu_owl やエンジニアは多いと思います。
もちろんFPGAやGPUに加え、メモリもたっぷり搭載したディバイスを使えば、VGGでも高速処理が可能です。
っていう新しい問題が発生します。そこで…

と考え、GoogleがリリースしたのがMobileNetです!
MobileNetのスゴイところは、計算量が少ないのに精度が他のモデルと同等以上という点です。(精度については比較するモデル次第ですが…)
と思った人は、以下の参考資料を覗いてみて下さいな!
MobileNet(v1/2)、ShuffleNet等の高速なモデルの構成要素と何故高速なのかの解説|Qiita
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
SSDとは
SSDとはYoloと同じOne-stageの物体検出手法です(Two-stage detectorsもあるよ)
深層学習による物体検出の概要については以下の記事で説明しています↓

色んな物体検出の手法がありますが…
MobileNetベースSSDモデル
VGGやMobileNetなどのモデルをベースにSSD用のネットワークを追加…
つまり、物体認識+物体検出用の層を追加することで、SSDモデルが完成します。
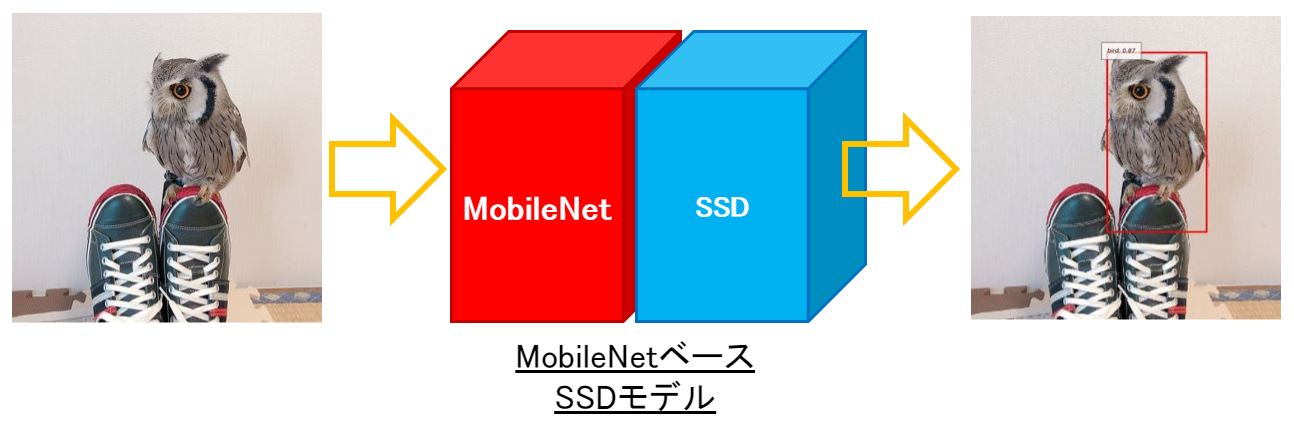
↑のように前半MobileNet/後半SSDと完全に分かれているわけではなく…VGGやMobileNetの層の間にも物体認識+物体検出用(SSD用)のネットワークを挿入することで、物体の大きさを考慮した検出を実現しています。
なのでレゴブロックのようにベースモデルを気軽に付け替えたい!という場合には、ベースモデルだけではなく『MobileNetベースSSDモデル/VGGベースSSDモデル』などSSDモデルを付け替える必要があります。
くるるちゃんは今日も賢い(*・ω・)ノ♪
【実践】リアルタイム物体検出リアルタイム物体検出
簡単にですが『MobileNet-SSDによるリアルタイム物体検出』の概要を説明したので、次からは実装をしていきます。
まずは参考になりそうなソースコードがないか調査します…pytorch-ssdというドンピシャなのがありますね!感謝!!
今回はpytorch-ssdをベースに自分好みにカスタムしていきます。
最初はChainerCVで参考になりそうなソースコードを調査したのですが、『VGGベースSSD』しか見つからなかったので、今回はPytorchを採用しました。
動作手順
いつもは静止画のみに対応しているソースコードを動画にも対応させたりするのですが…pytorch-ssdは既に動画対応しているので、いきなり動かしてみます。
pytorch-ssdのREADME通りにやれば問題ないですね。
まずは以下のコマンドで「学習済みモデル」と「ラベル」をダウンロードします。
wget -P models https://storage.googleapis.com/models-hao/mobilenet-v1-ssd-mp-0_675.pth
wget -P models https://storage.googleapis.com/models-hao/voc-model-labels.txt
次に以下のコマンドで実行すればOK!
python run_ssd_live_demo.py mb1-ssd models/mobilenet-v1-ssd-mp-0_675.pth models/voc-model-labels.txt
…と説明してあるけど、以下のようなエラーが出ました。
from torchvision import transforms
ModuleNotFoundError: No module named ‘torchvision’
少し調べてみましたが、推論(物体検出を実行)するだけなら、上記のモジュールが不要だったので「~/pytorch-ssd-master/vison/transforms.py」の5行目をコメントアウトしました↓
|
1 2 3 4 5 6 7 8 9 10 |
# from https://github.com/amdegroot/ssd.pytorch import torch # from torchvision import transforms import cv2 import numpy as np import types from numpy import random |
これで実行できるはずです!
カスタム例
run_ssd_live_demo.pyのままでも十分素晴らしいけど…以下の点が気になりました。
- 出力画面が大きい
- バウンディングボックスの色(水色)
- ラベルの表示位置(バウンディングボックスの内側)
- ラベルのフォントサイズが小さい
- ターミナルのみ処理速度を表示
好み問題ですが、以下のようにカスタムしたいと思います。
- 出力画面は入力画像と同じサイズ
- バウンディングボックスは緑色に変更
- ラベルはバウンディングボックスの外側(左上付近)に表示
- ラベルのフォントサイズを大きくする
- 出力画像の左上にFPSを表示
カスタムしたソースコードはこちら↓
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 |
from vision.ssd.vgg_ssd import create_vgg_ssd, create_vgg_ssd_predictor from vision.ssd.mobilenetv1_ssd import create_mobilenetv1_ssd, create_mobilenetv1_ssd_predictor from vision.ssd.mobilenetv1_ssd_lite import create_mobilenetv1_ssd_lite, create_mobilenetv1_ssd_lite_predictor from vision.utils.misc import Timer import cv2 import sys if len(sys.argv) < 4: print('Usage: python run_ssd_example.py <net type> <model path> [video file]') sys.exit(0) net_type = sys.argv[1] model_path = sys.argv[2] label_path = sys.argv[3] if len(sys.argv) >= 5: cap = cv2.VideoCapture(sys.argv[4]) # capture from file else: cap = cv2.VideoCapture(0) # capture from camera if not cap.isOpened(): raise ImportError("Couldn't open video file or webcam.") class_names = [name.strip() for name in open(label_path).readlines()] num_classes = len(class_names) if net_type == 'vgg16-ssd': net = create_vgg_ssd(len(class_names), is_test=True) elif net_type == 'mb1-ssd': net = create_mobilenetv1_ssd(len(class_names), is_test=True) elif net_type == 'mb1-ssd-lite': net = create_mobilenetv1_ssd_lite(len(class_names), is_test=True) else: print("The net type is wrong. It should be one of vgg16-ssd, mb1-ssd and mb1-ssd-lite.") sys.exit(1) net.load(model_path) if net_type == 'vgg16-ssd': predictor = create_vgg_ssd_predictor(net, candidate_size=200) elif net_type == 'mb1-ssd': predictor = create_mobilenetv1_ssd_predictor(net, candidate_size=200) elif net_type == 'mb1-ssd-lite': predictor = create_mobilenetv1_ssd_lite_predictor(net, candidate_size=200) else: print("The net type is wrong. It should be one of vgg16-ssd, mb1-ssd and mb1-ssd-lite.") sys.exit(1) timer = Timer() while True: ret, orig_image = cap.read() if orig_image is None: continue image = cv2.cvtColor(orig_image, cv2.COLOR_BGR2RGB) timer.start() boxes, labels, probs = predictor.predict(image, 10, 0.4) interval = timer.end() print('Time: {:.2f}s, Detect Objects: {:d}.'.format(interval, labels.size(0))) # Draw FPS fps = "FPS:" + str(int(1/interval)) cv2.rectangle(orig_image, (0, 0), (50, 17), (0, 0, 0), -1) cv2.putText(orig_image, fps, (0, 10), cv2.FONT_HERSHEY_SIMPLEX, 0.35, (255, 255, 255), 1) for i in range(boxes.size(0)): box = boxes[i, :] label = f"{class_names[labels[i]]}: {probs[i]:.2f}" ''' # original cv2.rectangle(orig_image, (box[0], box[1]), (box[2], box[3]), (255, 255, 0), 4) cv2.putText(orig_image, label, (box[0]+20, box[1]+40), cv2.FONT_HERSHEY_SIMPLEX, 1, # font scale (255, 0, 255), 2) # line type ''' # change cv2.rectangle(orig_image, (box[0], box[1]), (box[2], box[3]), (0, 255, 0), 4) cv2.putText(orig_image, label, (box[0]+10, box[1]-10), cv2.FONT_HERSHEY_SIMPLEX, 1, # font scale (255, 0, 255), 2) # line type cv2.imshow("SSD Result", orig_image) if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows() |
run_ssd_live_demo.pyをベースにカスタムしたので、run_ssd_live_demo_V2.pyという名前にしました。
動作確認
ファイル名が変わったので、以下のコマンドで実行します。
python run_ssd_live_demo_V2.py mb1-ssd models/mobilenet-v1-ssd-mp-0_675.pth models/voc-model-labels.txt
第8世代となるインテルCoreプロセッサ(Core i5-8250U)を使うと3~4fpsで動きました。GPU使えば、もっと高速に動くので『ロボットの眼』として使えそうです!!
くるるちゃんは今日も可愛い(*・ω・)ノ♪
まとめ
本サイトで『深層学習による物体検出』の記事を公開しており、本記事が第4弾になります。
今までChainerCVを使ってきましたが、今回はPytorchを使いました。ChainerよりPytorchの方が参考資料が多いので助かりますね。(Chainer好きなんだけど、参考資料が少ない…)
リアルタイム物体検出するならYoloも良いけど、SSDも精度が良いですよ!『MobileNetベースSSD』なら処理速度も速い!!
本記事で紹介したソフト『run_ssd_live_demo_V2.py』をロボットや電子工作に組み込みました!って人が現れたらエンジニアとしては最高に嬉しい!!
















