
こんばんは。
コンピュータビジョン(『ロボットの眼』開発)が専門の”はやぶさ”@Cpp_Learningです。
YoloやFCISによる『カメラ・動画対応!物体検出ソフト』を作って遊んだりしてます。


今回は、その第3弾!Light-Head R-CNNによる『カメラ・動画対応!物体検出ソフト』を作ってみたいと思います。
Light-Head R-CNNとは
『Light-Head R-CNN』について説明するには、先に『物体検出』そのものについて説明しておくと分かりやすいと思うので…
『物体検出』⇒『Light-Head R-CNN』の順に概要を説明します。
画像処理で物体検出というと『移動物体検出』や〇/□などの形状をした物体を検出する『幾何学模様検出』も物体検出と呼ぶ場合があります。全てを説明するのは大変なので、本記事では『深層学習による物体検出』のみ簡単に説明します。
移動物体検出(物体追跡)に興味がある人は、下記の記事が参考になるかも!

深層学習による物体検出の概要
深層学習による物体検出は大きく2つのフェーズで実現しています。
【第1フェーズ】:物体候補の抽出

【第1フェーズ】では、画像から物体候補(物体っでぽいもの)を抽出します。
ポイントは背景となる物体は無視している点です。
画像処理の基本的な考え方は『特徴を抽出すること』なので、壁・床・空・物体の一部分などの背景は特徴が少ないため抽出が難しい、あるいは抽出できても無視することが多いです。
このフェーズで注意すべき点は、抽出した物体候補の『名前』までは認識できていないことです。
- 背景を無視して物体候補を抽出する
- 第1フェーズでは抽出した物体候補の『名前』までは認識できない
【第2フェーズ】:物体認識

【第2フェーズ】では「抽出した物体候補が何の物体だったのか?」の物体認識を行います。
【第1フェーズ】で抽出した物体候補をCNN(畳み込みニューラルネットワーク)に入力して、認識率を算出します。
認識結果は学習済みラベル(物体の名称)に依存するため、”フクロウ”というラベルを事前に学習させていない場合は、そのラベルとの一致度(認識率)は算出されません。
学習済みラベルとの一致度が最も高いものを物体検出の最終出力結果としてラベルおよびバウンディングボックス(矩形の□)が描画されます。
また、一致度(認識率)に閾値を設定でき「50%以下の場合は学習済みのラベルと一致する物体はなかった!」としてバウンディングボックスを描画しないこともできます。
なお、一致度(認識率)の精度は採用する物体検出手法(CNN含む)に依存します。
- 学習していないラベルとの一致度(認識率)は算出できない
- 一致度(認識率)に閾値を設定することができる
- 一致度(認識率)の精度は採用する物体検出手法に依存する
物体検出手法の種類 -One-stage/Two-stage detectors-
ここまでの説明で、物体検出は以下のフェーズで実現していることが分かると嬉しい!
- 【第1フェーズ(ステージ)】:物体候補の抽出
- 【第2フェーズ(ステージ)】:物体認識
(より詳細にフェーズ分けして説明している良質な本や記事もあります。あとで参考資料の説明もします。)
英語論文だと”Phase(フェーズ)”ではなく”Stage(ステージ)”と説明する場合があるので覚えておくと良いと思います(*・ω・)ノ♪
Two-stageで物体検出を行う代表的な手法は『R-CNN系』で、その中でもリアルタイム物体検出のFaster R-CNNは名前を聞いたことがある人も多いかも(?)
Two-stageの物体検出は、処理速度を改善したFaster R-CNNでも、まだ処理速度が遅いと言われていました。
そこで、第1ステージと第2ステージを一気にやるOne-stageの物体検出手法が誕生しました。その代表が『Yolo系』と『SSD系』です。
One-stageなので処理速度の問題は解消され、かつFaster R-CNNと同等程度の高い精度を実現する手法もあります。
各物体検出手法をもっと勉強したい!という人は、以下の記事を参考にすると良いと思います。
Light-Head R-CNNの概要
上記した通り、Two-stageの物体検出は処理速度が遅いという問題があり、高性能なGPUを使えない環境だと、リアルタイム物体検出が可能なYoloなどのOne-stageの物体検出を採用するしかありませんでした。
しかし、Faster R-CNNを改良し、演算コストを抑えたLight-Head R-CNNというTwo-stageの物体検出が考案されました。
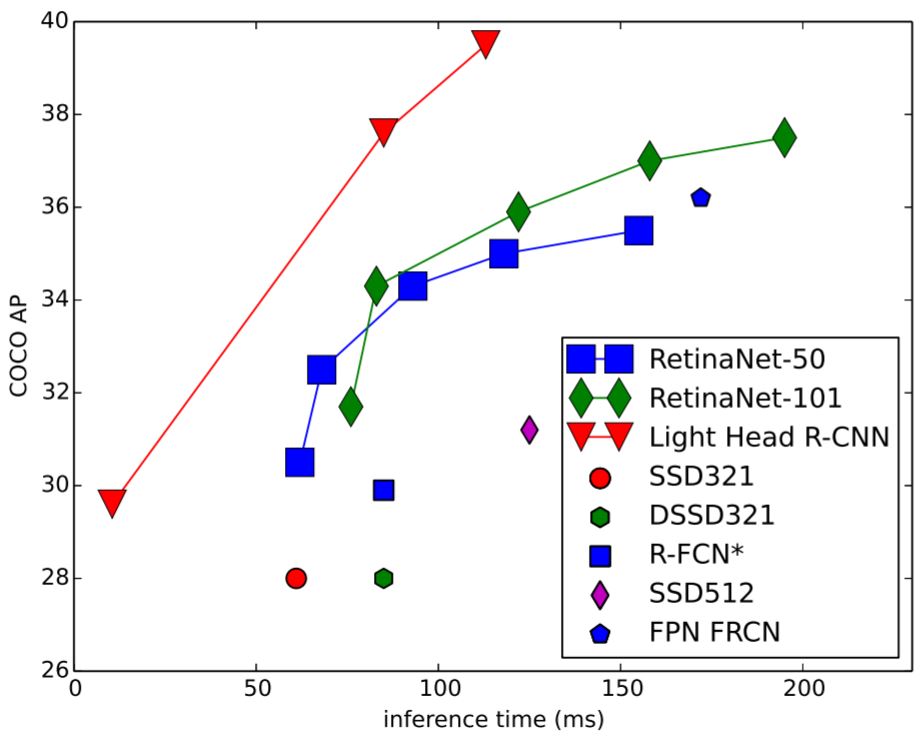
出展:Light-Head R-CNN: In Defense of Two-Stage Object Detector
Light-Head R-CNNはTwo-stageの物体検出ですが、YoloやSSDなどのOne-stageの物体検出と同等以上の高速性と精度を実現したとのことです。
Light-Head R-CNNの詳細を知りたい!という人は上図の出展を覗いてみて下さい。
Light-Head R-CNNによる物体検出ソフトの開発手順
環境構築から開発手順まで冒頭で紹介した以下の記事で説明済みなので…
まだ環境構築が済んでいない人は、↑の記事を一読して頂けると嬉しいです。
LH_R-CNN_Chainer_Video.py開発
今回ベースとなるソフトはchainer-light-head-rcnnから取得できます。
exampleフォルダ内の”demo.py”とYoloの記事で作った『物体検出ソフト』を組み合わせて、以下のソースコード”LH_R-CNN_Chainer_Video.py”を作りました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 |
import argparse import matplotlib.pyplot as plt import cv2 import numpy as np from timeit import default_timer as timer import chainer from chainercv import utils # from chainercv.datasets import coco_bbox_label_names from light_head_rcnn.links import LightHeadRCNNResNet101 from light_head_rcnn.visualizations import vis_bbox coco_bbox_label_names = ( 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush') def main(): parser = argparse.ArgumentParser() parser.add_argument('--gpu', type=int, default=-1) parser.add_argument('--pretrained-model', default='coco') parser.add_argument('video') args = parser.parse_args() model = LightHeadRCNNResNet101( n_fg_class=len(coco_bbox_label_names), pretrained_model=args.pretrained_model) if args.gpu >= 0: chainer.cuda.get_device_from_id(args.gpu).use() model.to_gpu() if args.video == "0": vid = cv2.VideoCapture(0) else: vid = cv2.VideoCapture(args.video) if not vid.isOpened(): raise ImportError("Couldn't open video file or webcam.") # Define the Codec and File Name fourcc = cv2.VideoWriter_fourcc(*'DIVX') out = cv2.VideoWriter('Light-Head-RCNN_Kururu.mp4', fourcc, 10, (640,640)) # 640,360 # Compute aspect ratio of video vidw = vid.get(cv2.CAP_PROP_FRAME_WIDTH) vidh = vid.get(cv2.CAP_PROP_FRAME_HEIGHT) # vidar = vidw / vidh print(vidw) print(vidh) accum_time = 0 curr_fps = 0 fps = "FPS: ??" prev_time = timer() frame_count = 1 while True: ret, frame = vid.read() if ret == False: print("Done!") return # BGR -> RGB rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # Result image result = frame.copy() # (H, W, C) -> (C, H, W) img = np.asarray(rgb, dtype = np.float32).transpose((2, 0, 1)) # Object Detection bboxes, labels, scores = model.predict([img]) bbox, label, score = bboxes[0], labels[0], scores[0] if len(bbox) != 0: for i, bb in enumerate(bbox): # print(i) lb = label[i] conf = score[i].tolist() ymin = int(bb[0]) xmin = int(bb[1]) ymax = int(bb[2]) xmax = int(bb[3]) class_num = int(lb) # Draw box cv2.rectangle(result, (xmin, ymin), (xmax, ymax), (0,255,0), 2) text = coco_bbox_label_names[class_num] + " " + ('%.2f' % conf) print(text) text_top = (xmin, ymin - 10) text_bot = (xmin + 80, ymin + 5) text_pos = (xmin + 5, ymin) # Draw label cv2.rectangle(result, text_top, text_bot, (255,255,255), -1) cv2.putText(result, text, text_pos, cv2.FONT_HERSHEY_SIMPLEX, 0.35, (0, 0, 0), 1) # Calculate FPS curr_time = timer() exec_time = curr_time - prev_time prev_time = curr_time accum_time = accum_time + exec_time curr_fps = curr_fps + 1 if accum_time > 1: accum_time = accum_time - 1 fps = "FPS:" + str(curr_fps) curr_fps = 0 # Draw FPS in top right corner cv2.rectangle(result, (590, 0), (640, 17), (0, 0, 0), -1) cv2.putText(result, fps, (595, 10), cv2.FONT_HERSHEY_SIMPLEX, 0.35, (255, 255, 255), 1) # Draw Frame Number cv2.rectangle(result, (0, 0), (50, 17), (0, 0, 0), -1) cv2.putText(result, str(frame_count), (0, 10), cv2.FONT_HERSHEY_SIMPLEX, 0.35, (255, 255, 255), 1) # Output Result cv2.imshow("Light Head RCNN Result", result) # Stop Processing if cv2.waitKey(1) & 0xFF == ord('q'): break frame_count += 1 if __name__ == '__main__': main() |
※LH_R-CNN_Chainer_Video.pyはexampleフォルダに保存しました。
LH_R-CNN_Chainer_Video.pyのポイント解説
Yoloの記事で作った『物体検出ソフト』と↑のソースコードの構造がほとんど同じなので…異なる点のみ説明します。
Yoloの記事で作った『物体検出ソフト』の場合はVOCデータセットによる学習済みモデルをロードして物体検出を行ったので、ラベル数が20種でした。
一方、今回作ったソフトがCOCOデータセットによる学習済みモデルをロードして物体検出を行うので、ラベル数を80種に変更する必要があります。
ChainerCVは、VOC/COCO両方のラベル定義を用意しているので、それをimportするだけで、VOC/COCO用のラベルを使うことができます。
コードの9行目のimportでCOCO用ラベルを使うことができます
ただし、ChainerCVのバージョン次第では、importできない可能性があります。そんなときは、COCO用のラベル定義を手書きします。
コードの14~94行目がCOCO用ラベルの定義を手書きしたものです。別のデータセット(オリジナル含む)を使う場合にも、このやり方で対応できます。
あとchainer-light-head-rcnnを取得したときに”light_head_rcnn”というフォルダがあると思うので、それを”example”フォルダに移動してください。
要するに、”light_head_rcnn”フォルダとLH_R-CNN_Chainer_Video.pyの階層を揃えてほしい。理由は以下のコードの”light_head_rcnn”パス設定の都合です。
コードの11~12行目がlight_head_rcnnのimport
LH_R-CNN_Chainer_Video.pyの使い方
”LH_R-CNN_Chainer_Video.py”の使い方もYoloの記事で作った『物体検出ソフト』とほとんど同じですが、一応デフォルト設定時での起動は以下の通りです。
デフォルト設定での起動例
python LH_R-CNN_Chainer_Video.py 動画ファイルパス
動画ファイルパスのところを”0”にするとUSBカメラやノートPC内蔵カメラの映像を使って『物体検出』を実行します。
デフォルト以外の学習済みモデルやラベル定義を変更することも可能ですが、コードの修正が必要になります。
動作確認
LH_R-CNN_Chainer_Video.pyを動作確認した映像が以下です。
※この映像は10fpsで再生しています。
第8世代となるインテルCoreプロセッサ(Core i5–
リアルタイム感はないですね…GPUマシンで動かさないと本領発揮しないのかもなぁ
(GPUマシンほしい…)
まとめ
本サイトでChianerCVで『カメラ・動画対応!物体検出ソフト』を作るシリーズを紹介しており
本記事が、その第3弾!Light-Head R-CNNによる『カメラ・動画対応!物体検出ソフト』の開発手順を説明しました。
本サイトでは、このシリーズ以外にも画像処理に関する記事(チュートリアル多め)が多数あるので、本サイトの記事を読んで…


と思ってくれる人が少しでもいると最高に嬉しい(*・ω・)ノ♪
(完)
おまけ -くるるとはやぶさの”ほのぼの劇場”-
以降は技術的な内容が少ない”ただの茶番”なので、お時間ある人だけ読んで頂ければと思います。
にゃーん
小さな笑い声が聞こえる。まるで笑いを堪えているようだ。
その声の正体は、最近LINEスタンプを作った人気フクロウの”くるる”@kururu_owl です。

(スタンプで得た収入は参考書代など、本サイトの運営に役立てますので、投げ銭感覚でスタンプを購入してくれると嬉しいです!)

すごいニコニコしながら声をかけてくれた!今にも笑いが吹き出しそうである。

私もニコニコが止まらない!
この後10分ほど1人と1羽で大爆笑!今日も平和だ。
誤認識の考察
動作確認の動画を見た人は気づいたと思うが”くるる”の写真やイラストが”猫”と認識されたのだ。
AIの気持ちになって考えてみると、
- 猫のような耳(実際には羽角と呼ばれる羽)
- 猫のようなヒゲ
- 猫のようなサイズ
- 猫のような毛色
正面から見たフクロウ…より正確にはアフリカオオコノハズクの”くるる”を正面から見ると、猫と同じ特徴を抽出できるため『猫に違いない!』と誤認識したのだろう。
一方、横から見た本人は常に『鳥』と認識していた。おそらく、羽/翼/嘴といった鳥の特徴を抽出できたため、誤認識しなかったと考えている。
深層学習による演算はブラックボックスと言われているが、AIの気持ちになって
- どんな特徴を抽出しているか?
- 何故その特徴を抽出したのか?
などを考えてみると…少しは誤認識の理由が分かるかもしれませんね(*・ω・)ノ♪
ラベルの色分け と 研究者の仕事
ようやく笑いが収まった”くるる”が喋りだした。
ChianerCVで『カメラ・動画対応!物体検出ソフト』を作るシリーズ第1弾・第2弾のときはラベル毎にバウンディングボックスの色変更するモードを実装していた。
しかし、今回は単色モードのみにしている。実は今回、Light-Head R-CNNを採用したのは…
「YoloやSSD並みにリアルタイム物体検出が本当にできるのか?」を確認したい!という好奇心があったからです。
まぁ結果は上記した通りでしたが…(GPUだと、どんな結果になるのか気になる!)
なので、確認したかった処理速度と精度を確認できれば、ラベル毎の色分けは後回しでも良いかなぁと思い…結局やりませんでした。
少し気になりますが、本質から遠い部分は後回しにして、私は次のリサーチを開始します。
私の普段の仕事もこんな感じです。あまり品質の高いソフトを作り込まず、必要事項が確認できるコードを仕上げ、脈無しと判断したら、すぐに次に進む。
品質の高いソフトを開発するのは、最後の最後です。
仕事の進め方も少しは参考になるのかな?
さてと…次は何の記事を書こうかなぁ~
(おまけ 完)
















