こんにちは。
現役エンジニアの”はやぶさ”@Cpp_Learningです。色んな深層学習フレームワークを触ってきましたが…
Chainer開発停止のニュースを聞いて以来、PyTorchをメインで使おうと考えています。
今回は、スッキリした学習コードを書けるpytorch-lightningについて勉強したので、備忘録および情報共有のために本記事を書きます。
Contents
PyTorch Lightningとは
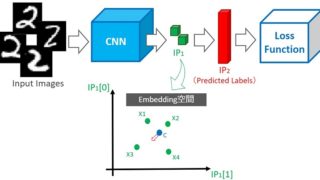
PyTorch Lightningの概要は下図の通りです。

PyTorch Lightningを活用すれば、ピュアPyTorchで書いていた学習用ループ処理などの大部分(上図の青:Trainer)を分離・自動化できるため、ユーザーは研究などで注力したい部分(上図の赤:Lightning Module)のコード作成に専念できます。
PyTorch Lightningのライバルたち
PyTorch Lightningの仲間(ライバル?)に catalyst・fastai・igniteがあり、いずれもEcosystem | PyTorch で紹介されています。

という人は、以下の資料が参考になると思います。
PyTorch 三国志(Ignite・Catalyst・Lightning)|Qiita
ChainerのMNISTのコードをPyTorch+Igniteで書き直してみた|Qiita
画像コンペの進め方を晒すのでアドバイスください!(Catalyst紹介)
今回、Pytorch Lightningを採用した理由は…

PyTorch Lightningを使うモチベーション
PyTorchは深層学習用のフレームワークなので、ある程度は同じ形式でコードを書けます。しかし、自由度が高いため、学習用のループ処理などがユニークになりがちです。
1人で使う書き捨てコードなら問題ありませんが、チームでコードを共有したり、過去に自作したコードを使いまわす場合は、フレームワークなどの力を借りてコードを形式化する方が効率的です。
(夜のテンションで可読性の悪いコードを書いてしまうことありますよね?)
PyTorch Lightningで研究に注力…みたいなカッコイイこと(公式もそう説明してる)を書きましたが…
個人的にはスッキリした学習コードを書きたいというのが本音です。
PyTorch Lightningの活用により、可読性の良い学習コードを書いて、チームで共有したり、過去に書いたコードを使い回したいと考えています。
公式チュートリアルでPyTorch Lightning入門
PyTorch Lightning公式ドキュメントや公式リポジトリのチュートリアルコードを見ると、以下の2Stepで学習できることが分かります。
- LightningModuleを継承したクラスを作成
- trainer.fit(model)で学習
Google Colaboratoryで直ぐに動かせるデモも用意してあるので、スッキリとしたコードで学習できることに感動してください。
Google Colab上でpytorch-lightningをインストールした時にRESTART RUTIMEという表示がでる場合は、それをクリックしないとデモが動かない可能性があります(2019/12/22時点)
実践!PyTorch Lightningと自前データセットで学習 -画像分類編-
上記の公式チュートリアルを動かしたら、次は自前データで実践してみましょう!今回は、フクロウの種類を分類するモデルの生成にPyTorch Lightningを活用してみます。
- 以降で紹介するソースコードは、Google Colabで動作確認済み
- 2019/12/22時点の最新バージョンをインストール
! pip install pytorch-lightning==’0.5.3.2′
課題とデータ収集
アナホリフクロウとアフリカオオコノハズクを分類するモデルを生成します。


本サイトのマスコットキャラクター”くるる”@kururu_owl もアフリカオオコノハズク 縮めてアフコノです。 可愛いフクロウ画像を集めたら、以下の場所に保存します。
可愛いフクロウ画像を集めたら、以下の場所に保存します。
|
1 2 3 4 5 6 7 8 9 10 |
C:. ├─owl_dataset ├─train │ ├─ahukono │ └─anahori └─val ├─ahukono └─anahori |

データ収集が完了したら、学習用ソースコードを作成します。
import
まずはimportから
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import os from glob import glob import torch import torch.nn as nn from torch.nn import functional as F from torch.utils.data import DataLoader import torch.utils.data as data from torchvision.datasets import MNIST from torchvision import transforms from torchvision import datasets, models, transforms import pytorch_lightning as pl from pytorch_lightning import Trainer from PIL import Image import matplotlib.pyplot as plt |
GPU/CPU設定
PyTorchでは、GPU/CPUどちらを使用するかの設定が必要です。以下のコードでGPUが使用可能な環境ならGPUを使用し、そうでない場合はCPUを使用するようにします。
|
1 2 3 4 |
use_cuda = torch.cuda.is_available() and True device = torch.device("cuda" if use_cuda else "cpu") |
transforms/Dataset/DataLoaderについて
PyTorchで自前データを学習する場合、transforms/Dataset/DataLoaderモジュールをカスタムして使うことが多いです。各モジュールの役割は以下の通り。
- transforms
- データの前処理を担当するモジュール
- Dataset
- データとそれに対応するラベルを1組返すモジュール
- データを返すときにtransformsを使って前処理したものを返す。
- DataLoader
- データセットからデータをバッチサイズに固めて返すモジュール
各モジュールのカスタム方法についてはPyTorch公式チュートリアルや以下の本が参考になります。

参考書やサイトの情報を吸収し、自分が扱いやすいコードを設計できると良いですね(*・ω・)ノ♪
transforms実装
今回は画像用の前処理クラス MyTransforms を自作します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
class MyTransform(): def __init__(self, resize, mean, std): self.resize = resize self.mean = mean self.std = std def __call__(self, img, key='train'): data_transform = { 'train': transforms.Compose([ transforms.RandomResizedCrop(self.resize, scale=(0.5, 1.0)), # リサイズ transforms.RandomHorizontalFlip(), # データオーギュメンテーション transforms.ToTensor(), # テンソルに変換 transforms.Normalize(self.mean, self.std) # 標準化 ]), 'val': transforms.Compose([ transforms.Resize(self.resize), # リサイズ transforms.CenterCrop(self.resize), # 画像中央をresize×resizeで切り取り transforms.ToTensor(), # テンソルに変換 transforms.Normalize(self.mean, self.std) # 標準化 ]) } return data_transform[key](img) |
trainデータとvalデータ両方の前処理をサポートする設計にしました。
他に入れた方が良い前処理があれば教えて下さい!
Dataset実装
次にDateset生成クラス MyDataset を自作します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
class MyDataset(data.Dataset): def __init__(self, path=None, key='train', transform = None): self.transform = transform self.key = key self.path = path self.data = [] self.labels = [] # データセットpathリスト生成 target_path = os.path.join(self.path + self.key + '/**/*.jpg') for i in glob(target_path): # データリスト生成 self.data.append(i) # ラベルリスト生成 label = os.path.basename(os.path.dirname(i)) if label == "ahukono": label = 0 elif label == "anahori": label = 1 self.labels.append(label) def __len__(self): # データ数確認 return len(self.data) def __getitem__(self, index): # index番目の画像をロード img_path = self.data[index] img = Image.open(img_path) # 前処理 img_transformed = self.transform(img, self.key) # index番目のラベルをロード label = self.labels[index] return img_transformed, label |
MyDatasetをゼロからつくることも可能ですが、Datasetを継承し、課題に合わせてカスタムするのが良いと思います。
今回は「path=データセットの保存場所」・「key=train/val」をセットすれば、trainデータセット/valデータセットを生成できる設計にしました。
2分類なので16~22行目をべた書きしましたが、ラベルを定義したJSONファイルなどを活用すればもっとスマートに書けたかも。。
DataLoader実装
DataLoaderは用意してあるものを活用するので、自作しません。以下のコード1行書くだけでOKです(既にソースコード冒頭でimport済み)
|
1 2 3 |
from torch.utils.data import DataLoader |
ここまでは、ピュアPyTorchでも自作するコード です。以降からが PyTorch Lightning特有のコード になります。
システム設計 -PyTorch Lightning編-
PyTorch Lightningでは、ニューラルネットワーク・損失関数・オプティマイザ・train/valデータローダを1つのクラス(LightningModuleを継承したクラス)にまとめて定義します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
class CoolSystem(pl.LightningModule): def __init__(self, dataset_path, num_class): super(CoolSystem, self).__init__() self.dataset_path = dataset_path # resnet self.model = models.resnet18(pretrained=True) num_features = self.model.fc.in_features self.model.fc = nn.Linear(num_features, num_class) # 出力を1000からnum_classに付替え def forward(self, x): x = self.model(x) return x def training_step(self, batch, batch_idx): # REQUIRED x, y = batch y_hat = self.forward(x) loss = F.cross_entropy(y_hat, y) tensorboard_logs = {'train_loss': loss} return {'loss': loss, 'log': tensorboard_logs} def validation_step(self, batch, batch_idx): # OPTIONAL x, y = batch out = self.forward(x) return {'val_loss': F.cross_entropy(out, y)} def validation_end(self, outputs): # OPTIONAL avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean() tensorboard_logs = {'val_loss': avg_loss} return {'avg_val_loss': avg_loss, 'log': tensorboard_logs} def configure_optimizers(self): # REQUIRED optimizer = torch.optim.SGD(self.parameters(), lr=0.001, momentum=0.9) # optimizer = torch.optim.Adam(self.parameters(), lr=0.02) return optimizer @pl.data_loader def train_dataloader(self): # REQUIRED size = 224 mean = (0.485, 0.456, 0.406) std = (0.229, 0.224, 0.225) train_dataset = MyDataset(self.dataset_path, key="train", transform=MyTransform(size, mean, std)) train_loader = DataLoader(train_dataset, shuffle=True, batch_size=32) return train_loader @pl.data_loader def val_dataloader(self): # OPTIONAL size = 224 mean = (0.485, 0.456, 0.406) std = (0.229, 0.224, 0.225) val_dataset = MyDataset(self.dataset_path, key="val", transform=MyTransform(size, mean, std)) val_loader = DataLoader(val_dataset, batch_size=32) return val_loader ''' @pl.data_loader def test_dataloader(self): # OPTIONAL return DataLoader(MNIST(os.getcwd(), train=False, download=True, transform=transforms.ToTensor()), batch_size=32) ''' |
今回は、ニューラルネットワーク(CNN)を自作せず、学習済みモデル(Resnet)をファインチューニングします。
また、課題が画像分類なので、損失関数にはcross_entropy・オプティマイザにはSGDを採用しました(定番ですね)。
transforms/Datasetは自作した My○○ を呼ぶだけです。スッキリしたコードですね!
CNN・損失関数を自作する場合は、transforms/Dataset同様に外で定義したクラスや関数を呼ぶ方がスッキリしそうです。
学習
最後に「CoolSystemのインスタンスを生成⇒Trainerを定義⇒fitで学習」します。
|
1 2 3 4 5 6 7 8 |
dataset_path = "/content/drive/My Drive/owl_dataset/" num_classes = 2 # ["ahukono", "anahori"] cool_model = CoolSystem(dataset_path, num_classes) # most basic trainer, uses good defaults trainer = pl.Trainer(gpus=1) trainer.fit(cool_model) |
Trainer関連の公式ドキュメントを参照し、細かい設定も可能でしたが…今回は公式チュートリアルのコードに書かれた以下のコメントを信じて、デフォルトにしました。
# most basic trainer, uses good defaults (1 gpu)
- デフォルトのこの部分がイマイチだよ
- ○○の意図で△△な設定してます
などの情報があれば共有して頂けると嬉しいです(*・ω・)ノ♪
PyTorch Lightningと推論
今回のモチベーションがスッキリした学習コードを書きたいなので、以上の内容で終了しても良かったのですが…アドバイスもらえたら嬉しいので、推論用ソースコードも公開します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# 重み(チェックポイント)ロード checkpoint = torch.load('/content/lightning_logs/version_0/checkpoints/_ckpt_epoch_6.ckpt') # インスタンス生成(データセット不要) num_classes = 2 owl_classification_model = CoolSystem(None, num_classes) owl_classification_model.load_state_dict(checkpoint['state_dict']) # 推論モード owl_classification_model.eval() owl_classification_model.freeze() # 入力画像を読み込む image_file_path = "/content/drive/My Drive/owl_dataset/test/ahukono/kururu_001.jpg" img = Image.open(image_file_path) # [h, w, c] # 入力画像を表示 plt.imshow(img) plt.show() # 画像の前処理 size = 224 mean = (0.485, 0.456, 0.406) std = (0.229, 0.224, 0.225) transform = MyTransform(size, mean, std) # 前処理インスタンス img_transformed = transform(img, key="val") # torch.Size([3, 224, 224]) = [c,h,w] inputs = img_transformed.unsqueeze_(0) # torch.Size([1, 3, 224, 224]) = [mb,c,h,w] device = 'cpu' inputs = inputs.to(device) # 推論結果出力 outputs = owl_classification_model(inputs) # torch.Size([1, 2]) _, result = torch.max(outputs, 1) class_names = ['ahukono', 'anahori'] # 予測結果を出力する print("推論値:", outputs) print("入力画像の推論結果:", class_names[result]) |
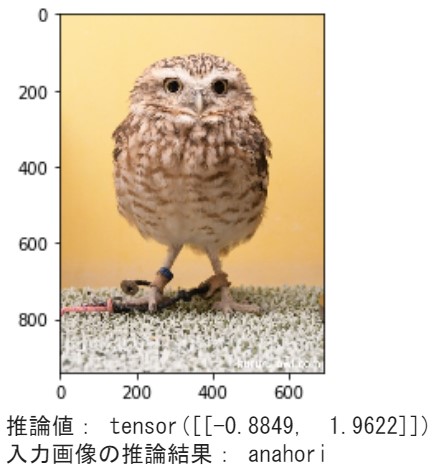
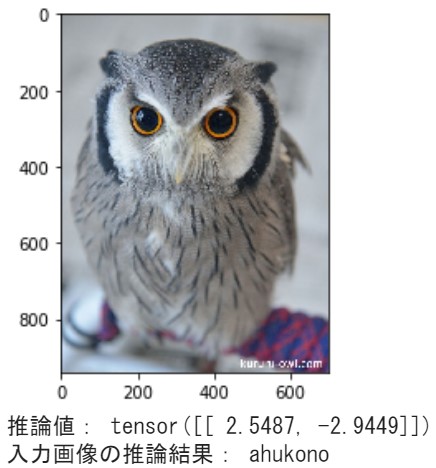
推論コードの補足説明
PyTorch Lightningで学習すると、checkpoint(重み)が以下の場所に保存されます。
|
1 2 3 4 5 6 7 |
lightning └── lightning_logs ├── version_0 └── checkpoints └── _ckpt_epoch_6.ckpt |
※Trainerがデフォルト設定のとき
この重み(*.ckpt)をロードし、‘state_dict’ を model.load_state_dict の引数に渡せば、モデル(CNN)に重みがセットされます。
あとは、ピュアPyTorchと同じです。
おわりに
今まで、ごちゃごちゃしたコードを書いてたので…PyTorch Lightningを活用し、スッキリした学習コードを設計してみました。
と思う一方で、catalyst・ignite も良さそうなので、何をメインで使うか未だに悩んでいます。

など情報共有して頂けたら嬉しいです。ブログやGitHubなどでコードを公開している人は、Twitterでこっそり教えて下さい ⇒ アカウント:@Cpp_Learning
また、本記事をきかっけに…

という人が現れたら、とても嬉しいです。