こんにちは。
現役エンジニアの”はやぶさ”@Cpp_Learningです。仕事でもプライベートでも機械学習で色々やってます。
今回は時系列データの前処理(ラグ特徴量)について勉強したので、備忘録も兼ねて本記事を書きます。
Contents
時系列データとは
時系列について、Wikipediaでは以下のように説明しています。
時系列(じけいれつ、英: time series)とは、ある現象の時間的な変化を、連続的に(または一定間隔をおいて不連続に)観測して得られた値の系列(一連の値)のこと。
引用元:Wikipedia
より直観的な説明をすると、データを可視化したとき横軸が時間なら、そのデータは時系列データといえます。
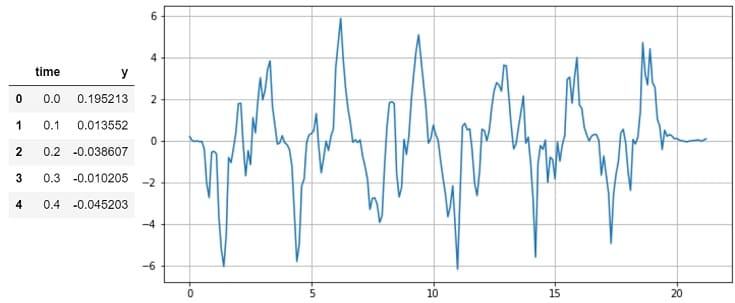
上図の縦軸が加速度センサの計測値、横軸が時間です。つまり、これも時系列データです。
センサ値の多くは時系列データです
機械学習のための前処理 -時系列データ編-
時系列データと機械学習を活用すれば、異常検出などを実現できます。
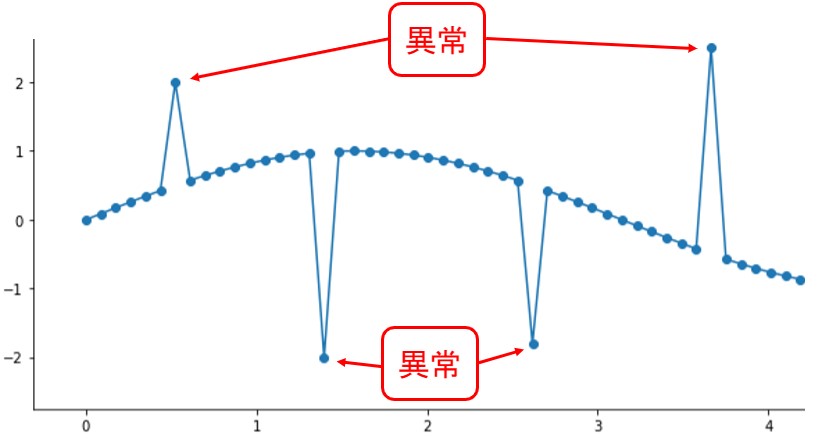
上図の例だと、データ1点で異常か否かを判断できそうですが、以下のような3/4の天気を予測するタスクの場合はどうでしょう?
| 日時 | 3/1 | 3/2 | 3/3 | 3/4 |
| 降水確率(%) | 30 | 65 | 80 | 90 |
| 天気(ラベル) | ☀ | ☁ | ☂ | ? |
これも3/4の降水確率のみで☂と予測できるかもしれませんが…
3/2から天気が崩れ始め、前日の3/3は降水確率80%で☂なので、3/4も高確率で☂になると予測できます。
今度は以下の例を考えてみます。
| 日時 | 3/5 | 3/6 | 3/7 | 3/8 |
| 降水確率(%) | 30 | 90 | 20 | 68 |
| 天気(ラベル) | ☀ | ☂ | ☀ | ? |
降水確率68%なので☂か☀か微妙なところですが、過去データの傾向から☀と☂が交互に続いているので、3/8も☂と予測するのが正解かもしれません。
このように、過去データから現在のパラメータを予測できることがあります。
現時点のデータ1点で予測するより、過去データを活用した方が予測精度を向上できるタスクもあります
ラグ特徴量とは
上記の天気予報の例で説明した通り、過去データを特徴量とすることで、機械学習モデルの予測精度を向上できる可能性があります。
このとき使う過去データの特徴量をラグ特徴量と呼びます。
実践!ラグ特徴量を生成する
様々なラグ特徴量があり、例えば以下のものが考えられます。
- 2日前のデータを特徴量とする
- 1~3日前のデータを特徴量とする
「2日ごとに(2日周期)で○○が発生しやすい」などの背景が既知なら、上記❶のラグ特徴量を作成するのが有効です。
「過去3日間の変化から○○が発生しやすい」などの背景が既知なら、上記❷のラグ特徴量を作成するのが有効です。
今回は「現在のデータ x と x のラグ(過去データ1~4)」を特徴量とした以下のデータセットを生成します(y はラベル)。
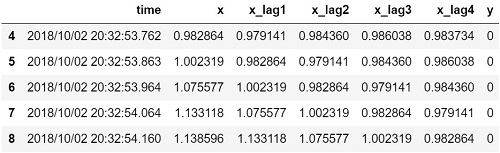
タスク応じて、どんなラグ特徴量を作成すべきか検討する必要があります
データ取得
まずは以下のコードでデータを取得します。
|
1 2 3 4 5 6 7 8 9 |
import pandas as pd import matplotlib.pyplot as plt import numpy as np # df = pd.read_csv('./test_data/x.csv') df = pd.read_csv('./test_data/x.csv', names=['time', 'x']) print(df.shape) df.head() |
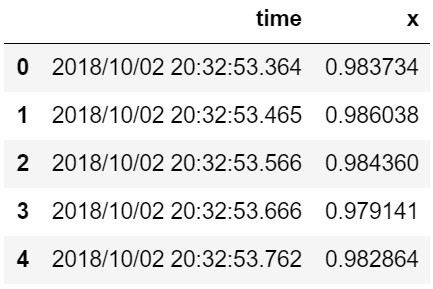
ちなみにxは筋トレ中の加速度です(詳細は以下の記事参照)。
可視化
以下のコードで可視化できます。
|
1 2 3 |
df.plot(figsize=(10, 5), grid=True) plt.title("Muscle training !!") plt.ylabel("[m/s^2]") |
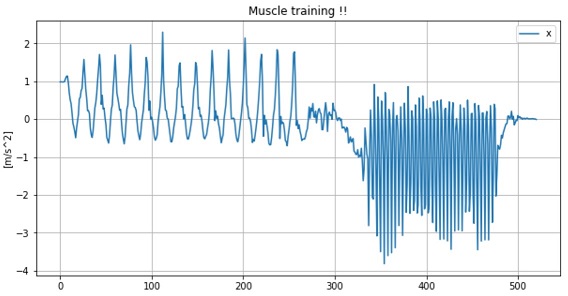
データの前半が腹筋中の加速度、後半が背筋中の加速度です。
【前知識】ラグ取得
shift(n)を使えば、簡単にn周期前のデータを取得できます。
|
1 2 3 4 |
# n周期前のlagを取得 x_lag1 = df["x"].shift(1) x_lag2 = df["x"].shift(2) x_lag3 = df["x"].shift(3) |
ラグ特徴量生成
以下のコードでlag1~nをまとめて取得できます(以下のコードは n=5 )。
|
1 2 3 4 5 6 7 |
n = 5 # 任意に変更 df_lag = pd.DataFrame() for i in range(1,n): df_lag['x_lag{}'.format(i)] = df['x'].shift(i) print(df_lag.shape) df_lag.head(10) |
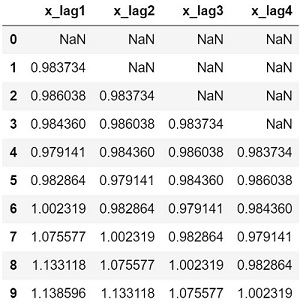
データフレーム連結
最初に取得したデータとラグ特徴量を連結します。
|
1 2 3 |
# データフレーム連結 df_tmp = pd.concat([df, df_lag], axis=1) df_tmp.head(10) |
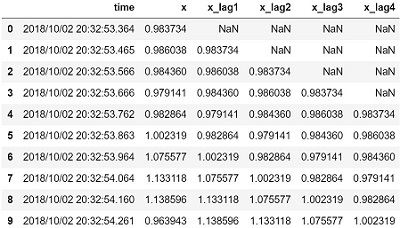
ラベル付け
全データの内、腹筋データ(0~300行)はラベル”0”、背筋データ(300~最後まで)はラベル”1”とします。色んな方法がありますが、今回は NumPy を使います。
|
1 2 3 4 5 6 |
row = len(df_tmp) y = np.zeros(row, dtype=np.int16) # 全要素が"0" y[301:] = 1 # 要素300~を"1"にする # print(len(y)) print(y) |
次にnumpyをdataframeに変換して、結合します。
|
1 2 3 |
label = pd.DataFrame(y, columns=['y']) df_tmp = pd.concat([df_tmp, label], axis=1) df_tmp.head(10) |
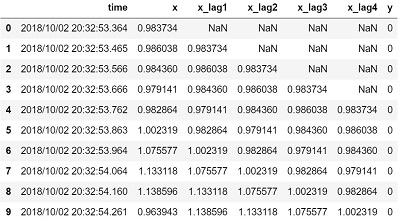
欠損データ削除
今回は欠損データ(NaN)がある最初の4行を削除します。
|
1 2 3 |
df_train = df_tmp.iloc[n-1:,:] # n = 5 # print(df_train.shape) df_train |
以上でラグ特徴量をもつデータセットの完成です。
【補足】rolling関数で移動平均・最大・最初値を算出
rolling関数を活用することで、windowサイズの移動平均・最大値・最小値などを簡単に算出できます。
|
1 2 3 |
x_ave = df["x"].rolling(window=4).mean() x_max = df["x"].rolling(window=4).max() x_min = df["x"].rolling(window=4).min() |
shift関数と組み合わせれば、n周期前のデータに対するwindowサイズの移動平均・最大値・最小値などの特徴量を作成できます(以下のコードは n=1, window=4)
|
1 2 3 |
x_ave = df["x"].shift(1).rolling(window=4).mean() x_max = df["x"].shift(1).rolling(window=4).max() x_min = df["x"].shift(1).rolling(window=4).min() |
これらの特徴量もタスク次第では有効です。
rolling関数を活用することで、手軽にフィルタ処理ができます。
まとめ -ラグ特徴量作成-
時系列データの前処理(ラグ特徴量)についてソースコード付きで説明しました。
機械学習は前処理が重要なので、タスクに応じて適切な前処理(特徴量作成含む)を実施したいですね。
本記事の内容が少しでも参考になれば嬉しいです。

おまけ -参考資料-
時系列データ解析について、タスク次第では機械学習ではなく、振動解析や信号処理が有効な場合もあります。
振動解析入門・信号処理入門の記事も書いてるので、良ければ参考にしてください。
深層学習による時系列データ異常検知の概要を知りたい人は、以下の資料をオススメします(イラスト多めで分かりやすい)。
時系列データ含め多様なデータの分析技術を学びたい人には、以下の書籍をオススメします。


















