
こんにちは。
コンピュータビジョン(『ロボットの眼』開発)が専門の”はやぶさ”@Cpp_Learningです。
『深層学習による物体検出』が好きで色んな記事を書いてます。
Chainer・PyTorch・ONNX Runtimeによる物体検出ソフトについては、本サイトの”画像処理カテゴリー”で公開中です。
今回はAWS(Amazon Web Services)が公式サポートしているMXNetを使って物体検出ソフトを作りました。
Contents
MXNetとは
MXNetとは、AWSが公式サポートしている深層学習フレームワークです。
深層学習フレームワークという意味で、Tensorflow・Pytorch・Chainerなどの仲間です。
【MXNetの特徴】をリスト化したものが以下です。
- AWSが公式サポートしている深層学習フレームワーク
- 自然言語処理・物体検出などを簡単に扱えるGluon APIがある
- インストール簡単
- チュートリアル充実
- ONNXモデルのImort/Exportの両方をサポート
- C++、JavaScript、Python、R、Matlab、Julia、Scala、Clojure、Perl といった幅広いプログラミング言語をサポート
MXNetの魅力をもっと知りたい人は、AWS公式サイトを覗いてみて下さい。
Gluonとは
Gluonとは、MXNet用の柔軟で使い易いAPIのことです。
以下の充実したチュートリアルで勉強すると、Gluon APIが柔軟かつ直感的に扱えることが分かると思います。
To get started with Gluon, checkout the following resources and tutorials:
- 60-minute Gluon Crash Course – six 10-minute lessons on using Gluon
- GluonCV Toolkit – implementations of state of the art deep learning algorithms in Computer Vision (CV)
- GluonNLP Toolkit – implementations of state of the art deep learning algorithms in Natural Language Processing (NLP)
- Dive into Deep Learning – notebooks designed to teach deep learning from the ground up, all using the Gluon API
引用元:MXNet/Gluon|公式
本記事では、物体検出を実践するので、GluonCVを使います。
環境構築
MXNetおよびGluonは、pipで簡単にインストールできます。
Gluon公式サイトの”インストール”ページに飛ぶと以下の画面が表示されます。
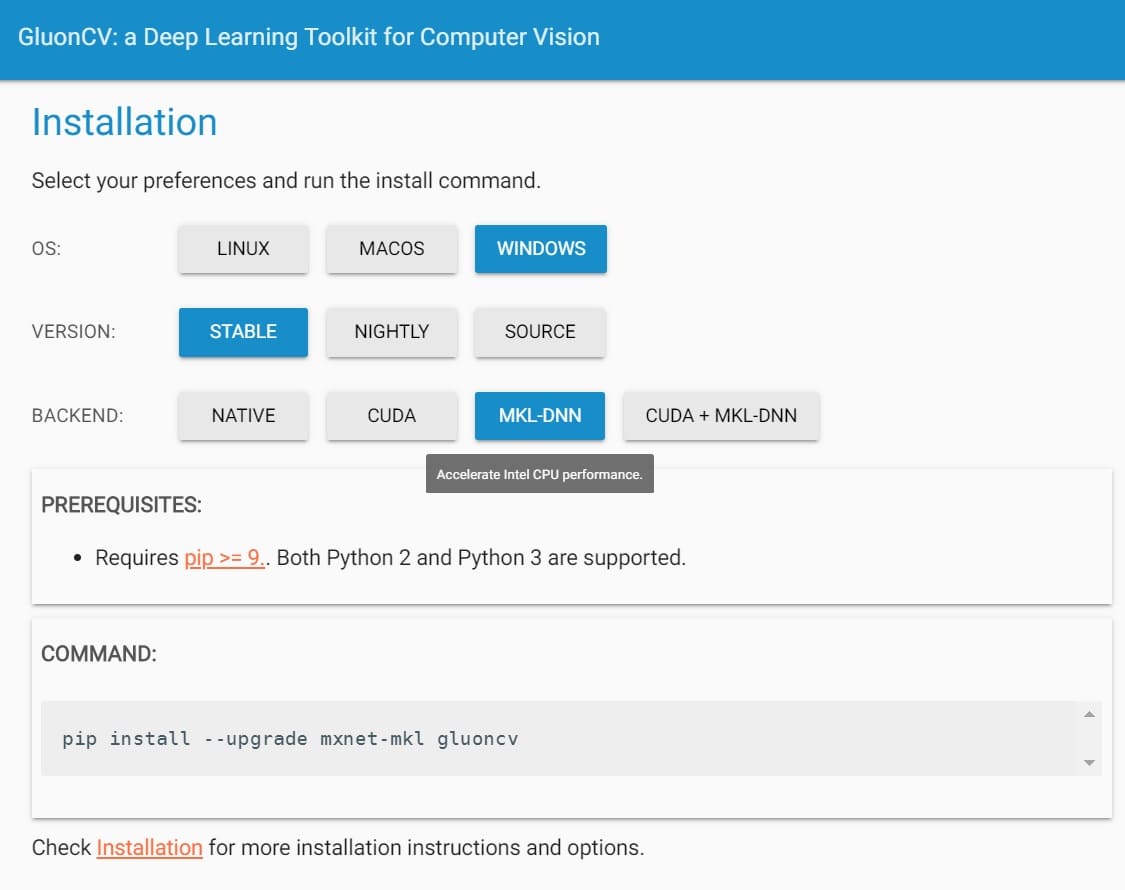
環境に応じた選択を行い、表示された「インストールコマンド(COMMAND)」をコピペして実行すれば、インストールが始まります。
上図は、Windowsにインストールする場合の例です。
Intel CPU搭載マシンなら、MKL-DNNを選択した方がパフォーマンスが向上します
また、動画を扱うときにOpenCVを使いたいので、以下のコマンドでインストールします。
pip install opencv-python
以降で説明するソースコードは以下のバージョンで動作確認しました。
- Python==3.7.3
- mxnet==1.4.1
- gluoncv==0.4.0
- opencv-python==4.1.0
- matplotlib==3.1.0
Model Zoo for GluonCV
GluonCVには、Model Zoo(モデルの動物園)があります。Model ZooのObject Detectionを覗いてみると…
GluonCVで直ぐに試せる、以下の物体検出モデルが用意してあります。
- SSD
- Faster-RCNN
- YOLO-v3
下図はデータセット:Pascal VOCで学習されたSSDモデルのリストです。
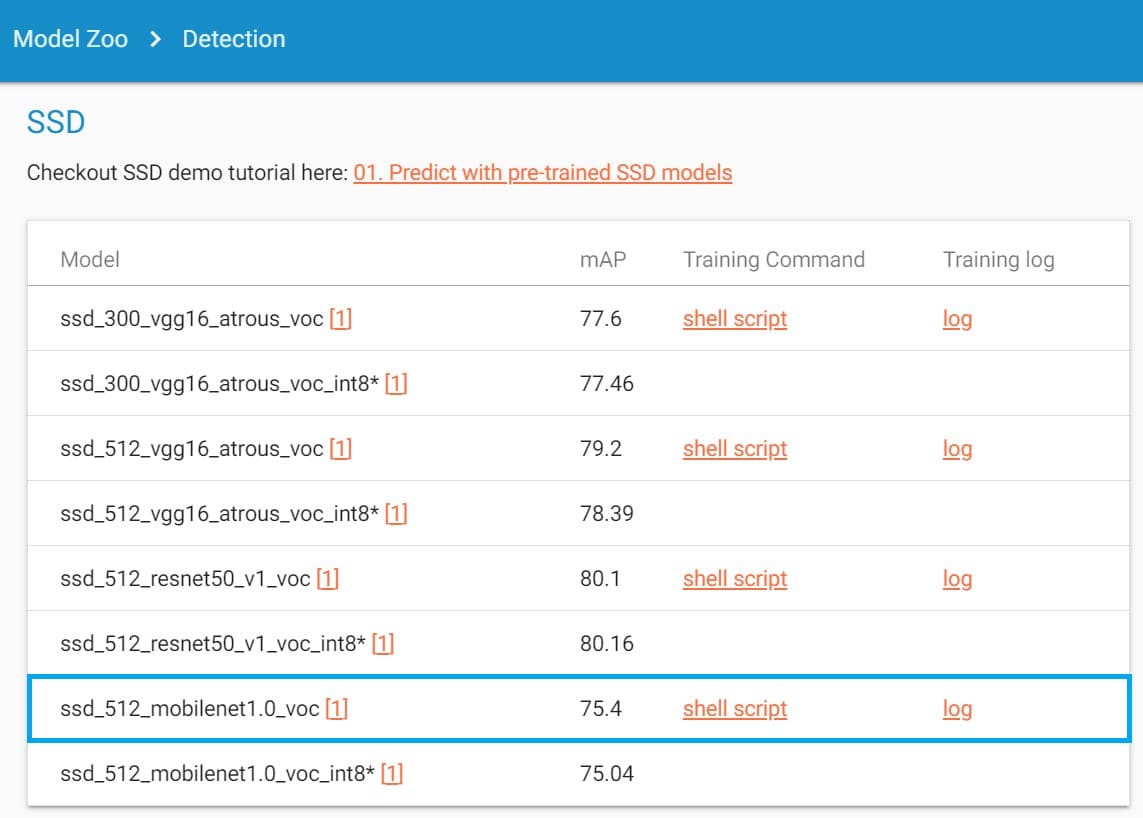
例えば、上図の青枠は「MobileNetV1ベースSSDモデル(入力サイズ512×512)」です。
MobileNet SSDについては、以下の記事でも扱っているので、良ければ参考にして下さい。

物体検出ソフト『MXNetCV_Cam.py』の開発
【MXNetの特徴】で説明した通り、チュートリアルが充実しているため、SSDモデルのチュートリアルも用意してあります。
このチュートリアルのコードを使えば簡単に静止画の物体検出を実現できます。
ただし、今回やりたいのは「カメラ・動画対応の物体検出」だったので、新規でソースコード”MXNetCV_Cam.py”を作成しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 |
import argparse import matplotlib.pyplot as plt from timeit import default_timer as timer import cv2 import gluoncv as gcv import mxnet as mx def main(): parser = argparse.ArgumentParser() parser.add_argument('-model', default='ssd_512_mobilenet1.0_voc') parser.add_argument('-threshold', type=float, default=0.5) parser.add_argument('video') args = parser.parse_args() # Set threshold th = args.threshold # Load the webcam handler if args.video == "0": cap = cv2.VideoCapture(0) else: cap = cv2.VideoCapture(args.video) if not cap.isOpened(): raise ImportError("Couldn't open video file or webcam.") # Compute aspect ratio of video vidw = cap.get(cv2.CAP_PROP_FRAME_WIDTH) vidh = cap.get(cv2.CAP_PROP_FRAME_HEIGHT) vidw = int(vidw) vidh = int(vidh) print(vidw) print(vidh) # Load the model net = gcv.model_zoo.get_model(args.model, pretrained=True) # net = gcv.model_zoo.get_model('yolo3_mobilenet1.0_coco', pretrained=True) # net = gcv.model_zoo.get_model('ssd_512_mobilenet1.0_voc', pretrained=True) # Time parameter accum_time = 0 curr_fps = 0 fps = "FPS: ??" prev_time = timer() frame_count = 1 while True: # Load frame from the camera ret, frame = cap.read() if ret == False: print("Done!") return # Result image result_img = frame.copy() # Image pre-processing frame = mx.nd.array(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)).astype('uint8') rgb_nd, scaled_frame = gcv.data.transforms.presets.ssd.transform_test(frame, short=512, max_size=700) # Run frame through network class_IDs, scores, bounding_boxes = net(rgb_nd) # Convert NDArray to numpy.ndarray bounding_boxes = bounding_boxes.asnumpy() scores = scores.asnumpy() class_IDs = class_IDs.asnumpy() # Class name list class_names = net.classes # Display the result for i, bbox in enumerate(bounding_boxes[0]): if th < scores[0][i]: score = scores[0][i] class_id = class_IDs[0][i] class_name = class_names[int(class_id)] xmin = int(bbox[0]) ymin = int(bbox[1]) xmax = int(bbox[2]) ymax = int(bbox[3]) # Draw box cv2.rectangle(result_img, (xmin, ymin), (xmax, ymax), (0,255,0), 2) text = class_name + " " + ('%.2f' % score) print(text) text_top = (xmin, ymin - 10) text_bot = (xmin + 80, ymin + 5) text_pos = (xmin + 5, ymin) # Draw class and score cv2.rectangle(result_img, text_top, text_bot, (255,255,255), -1) cv2.putText(result_img, text, text_pos, cv2.FONT_HERSHEY_SIMPLEX, 0.35, (0, 0, 0), 1) else: # Cut low score break # Calculate FPS curr_time = timer() exec_time = curr_time - prev_time prev_time = curr_time accum_time = accum_time + exec_time curr_fps = curr_fps + 1 if accum_time > 1: accum_time = accum_time - 1 fps = "FPS: " + str(curr_fps) curr_fps = 0 # Draw FPS in top right corner cv2.rectangle(result_img, (vidw-50, 0), (vidw, 17), (0, 0, 0), -1) cv2.putText(result_img, fps, (vidw-45, 10), cv2.FONT_HERSHEY_SIMPLEX, 0.35, (255, 255, 255), 1) # Draw Frame Number in top left corner cv2.rectangle(result_img, (0, 0), (50, 17), (0, 0, 0), -1) cv2.putText(result_img, str(frame_count), (0, 10), cv2.FONT_HERSHEY_SIMPLEX, 0.35, (255, 255, 255), 1) # Output Result title = args.model + " Result" cv2.imshow(title, result_img) # Stop Processing if cv2.waitKey(1) & 0xFF == ord('q'): break frame_count += 1 if __name__ == '__main__': main() |
実験や研究などで使い易いように、以下のポイントを考慮して作成しました。
- 複数モデル対応
- スコア閾値の変更が簡単
- カメラ・ビデオ対応
- フレーム数・FPSの表示
『MXNetCV_Cam.py』の使い方
パーサーで以下の項目を設定してから、”MXNetCV_Cam.py”を実行します。
| 設定項目 | 記号 | 選択候補 |
| モデル | –model | Model Zooにある好きなモデル |
| スコア閾値 | –threshold | ボックス描画したいスコアの下限値 |
| カメラ・動画モード選択 | 末尾に設定 | カメラなら”0” 動画ならファイルパス |
いくつか例を示します。
【使用例1】 YoloV3で物体検出(カメラモード)
COCOデータセットで学習した「MobileNetV1-YoloV3モデル」使用、スコア閾値=0.6に設定して、カメラモードで実行
python MXNetCV_Cam.py -model yolo3_mobilenet1.0_coco -threshold 0.6 0
【使用例2】 Faster-RCNNで物体検出(動画モード)
COCOデータセットで学習した「ResNet50-Faster-RCNNモデル」使用、スコア閾値=0.7に設定して、動画モードで実行
python MXNetCV_Cam.py -model faster_rcnn_resnet50_v1b_coco -threshold 0.7 [VideoPath]
【使用例3】 SSDで物体検出(デフォルト設定・カメラモード)
モデルや閾値に何も設定せず、カメラ・動画モードのみを設定して実行もできる。
python MXNetCV_Cam.py 0
※Pascal VOCで学習された「MobileNetV1-SSDモデル」、スコア閾値=0.5がデフォルト設定
キーボードの”q”を押すと停止し、動画の場合は、動画が終れば自動停止します。
モデルのダウンロードが必要なので、インターネットに接続されたPCを使って下さい(ダウンロード済みのモデルを使う場合は、インターネット不要です)
動作確認
任意の設定で”MXNetCV_Cam.py”を実行すると以下のような映像が出力されます。
※この映像は20fpsで再生しています。
『MXNetCV_Cam.py』公開のモチベーション
本記事で紹介した”MXNetCV_Cam.py”を公開したモチベーションについて少しだけ説明すると…
「深層学習と画像処理」をメインで研究・開発している人だけでなく、以下のような人が手軽に使えるソフトを提供したかった。
【対象読者】
- これから深層学習や画像処理を勉強したいと考えている人
- 物体検出がどんなものか直観的に理解したい人
- ロボットやアクチュエータ制御でイメージセンシングを活用したい人(ただし、画像処理を勉強する時間がとれない)
以下の記事で紹介している”⼭下り⽅式”の勉強方法に貢献するサンプルコードとして、”MXNetCV_Cam.py”を活用して頂ければ嬉しいです(*・ω・)ノ♪

まとめ
本サイトで様々なフレームワークを使用した「物体検出ソフト」を公開しており、今回はMXNetによる物体検出ソフトを公開しました。
1つのコードで色んな物体検出モデルを試せるので…
- 出力結果から各モデルの特徴を考察
- 用途に応じたモデルを見つける
- MXNetCV_Cam.pyの出力結果(座標やスコア情報)を使って何かを制御
などアイデア次第で面白いことができると思います。

という人が現れたら最高に嬉しいです(*・ω・)ノ♪

本編(完)
おまけ -本の紹介-
技術書展6で入手した書籍:機械学習の炊いたん。|技術書典6はCHAPTER1~5まであり、各CHAPTERを別の著者が執筆した本です。

(突然でてきたフクロウの”くるる”@kururu_owl が今日も可愛い)
この本の「CHAPTER 2 AWS SageMakerではじめるモデルの学習とデプロイ」にMXNetの魅力がたっぷり詰まっていました!
「MXNetとAWS SageMakerを⽤いてDeep Learningモデルの学習からデプロイまで⾏う⽅法」をコード付きで説明しており、大変勉強になりました。
機械学習の炊いたん。|技術書典6(無料サンプルあり)
また、本記事をきっかけに「機械学習を勉強したい!」と思った人には以下の記事をオススメしておきます。
本サイトの記事が勉強の参考になると嬉しいです。勉強を楽しも―(*・ω・)ノ♪
おまけ(完)


















