こんにちは。
ディープラーニングお兄さんの”はやぶさ”@Cpp_Learningだよー
前回『MXNetで物体検出』に関する記事を書きました。

最近、深層学習フレームワークのMXNetを使うのがマイブームです。
今回は『MXNetとLSTMによる行動予測』を実践してみます。
勉強した内容の備忘録として、本記事を書きます。
LSTMとは
LSTMの詳細な説明については、”ググる”と良質な記事が大量に出てきます。
例えば、Long Short Term Memory (LSTM)|MXNet公式の記事は、図解あり・数式あり・コードありで大変勉強になりました。
本記事では、LSTMの概要を直観的に理解できるような説明をしたいと思います。
LSTMによる予測のイメージ
LSTMとは、過去の情報を保持した状態で学習できるモデルのことです。
Recurrent Neural Network (RNN)でも同様の説明ができますが、RNNの構造に一工夫することで、より長い記憶の保持を実現したのがLSTMです。
直観的には、下図のように「過去の複数データ」から「次のデータを予測」するような学習を行います。
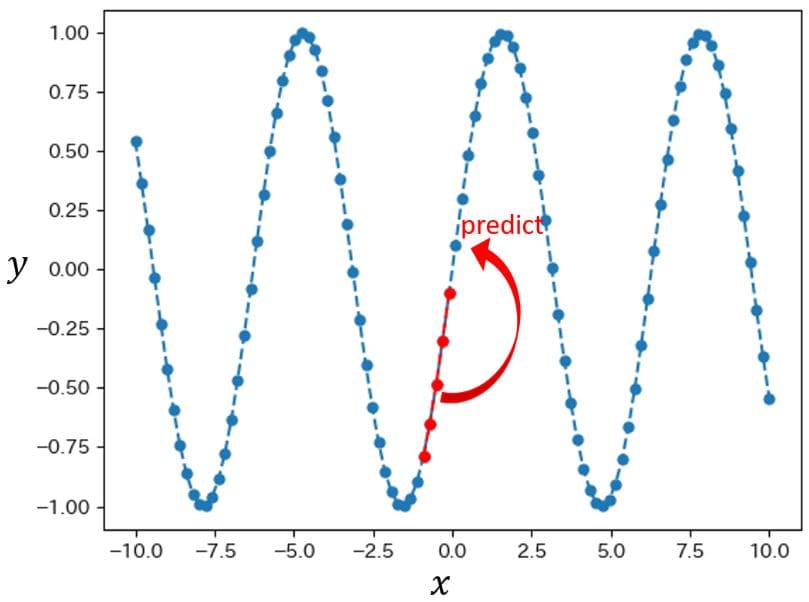
「過去どれだけのデータ数」を使って「いくつ先のデータを予測するか」については、設計者が任意に設定(チューニング)することができます。
上図の引用元:ReNom公式の記事も、図解あり・数式あり・コードありで大変勉強になります。
LSTMのネットワーク構造
LSTMについてのイメージが掴めたら…

などの構造に関する疑問をもった人や…

といったアルゴリズムに興味をもったフクロウ@kururu_owlがいるかもしれません。そんな人には、以下の動画をオススメします!
数式を使わずに11分の動画でLSTMのネットワーク構造や長期記憶の仕組みを簡潔に説明しており、とても勉強になりました。
Neural Network Console|SONY公式チャンネル動画でよく勉強させてもらっています。感謝です!
LSTMの活用事例 – LSTMの使い方 –
ここまでの説明でLSTMが時系列データの予測に使えそう!というのが分かると思います。
ただ、LSTMを勉強したばかりだと…
と考え、LSTMの活用法や応用例が気になるかもしれません。そこで…

を考えてみます。
- 傾向把握:対象データが将来的に”上昇 or 下降”などの傾向を把握できる
- 異常検知:予測値と実データに大きな差⇒異常の可能性を検知できる
- 時系列の分類:時系列のパターンを分類できる
- パターン予想:AとくればB、BとくればCなどのパターンを予測ができる
- データ補間:欠落したデータを補足(予測)できる
他にもアイデア次第で色々なことにLSTMを活用できます。
本記事では、パターン予想…より具体的には『LSTMによる行動予測』を実践します。
環境構築
本記事では、LSTMの実装に深層学習フレームワークのMXNetを使います。MXNetの概要やインストール方法は以下の記事で紹介しています。
↑の記事では、GluonCVを使いましたが、今回はGluonTSを使います。
GluonTS – Probabilistic Time Series Modeling –
GluonTSとは、確率的時系列モデリングのためのGluonツールキットです。以下のコマンドでインストールできます。
pip install gluonts
MXNetのみでもLSTMを実装できますが、GluonTSがとても便利なので、積極的に使います!
GluonTSとても使い易い!時系列データ予測したい人には本当にオススメです
Requirements
以降で説明するソースコードは以下のバージョンで動作確認しました。
- Python==3.7.3
- mxnet==1.4.1
- gluonts==0.2.3
- pandas==0.24.2
- matplotlib==3.1.0
課題とデータ収集
『LSTMによる行動予測』なんて書くと”何かすごいこと”のように聞こえますが…
本記事では『敵が波動拳を撃つタイミングを予測』したいと思います!

これが出来れば、非力な私でも波動拳を回避&反撃ができるかもしれません(*・ω・)ノ♪
プログラミングや勉強を楽しも―!好きなものと組み合わせてもOK♪
波動拳データセンシング
ゲームプレイ動画からデータ収集…でも良かったのですが、より実戦的にリアル波動拳のデータを収集します。
上の動画を見て10秒で波動拳モーションをマスターした後、以下のスマホアプリがインストール済みのスマホを右手に持って波動拳を6回撃ちます🔥


※このAppはiOSデバイス向けです。
そのときのジャイロスコープのデータを使います。
加速度も計測しましたが、ジャイロの方が綺麗なデータだったので、今回はジャイロを採用しました
データ確認
このアプリで取得したデータはCSV形式でテキストファイルに保存されます。
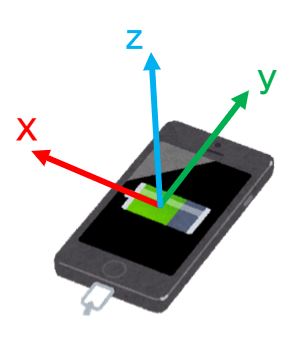
上図のxyz軸に対応したデータが存在するので、以下のコードで波動拳データを確認します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt import numpy as np df_x = pd.read_csv('./hadou_data/train/x.txt', names=['time', 'x']) df_y = pd.read_csv('./hadou_data/train/y.txt', names=['time', 'y']) df_z = pd.read_csv('./hadou_data/train/z.txt', names=['time', 'z']) # 表出力 print(df_x.shape) df_x.head() |
ジャイロデータは以下の形式で保存されています。
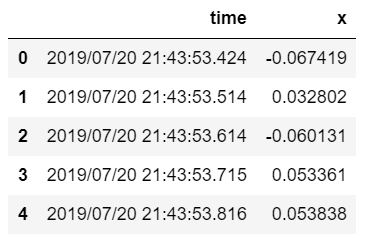
↑の表は”x.txt”のデータですが、”y.txt”と”z.txt”も同じ形式で保存されます。
前処理
LSTMによる時系列データ予測モデルを生成するために、前処理を行います。
波動拳データ可視化
最初に波動拳データを可視化して、時系列データの形状を確認します。
|
1 2 3 4 5 |
# 可視化 df_x.plot(figsize=(10, 5), grid=True, color="r") df_y.plot(figsize=(10, 5), grid=True) df_z.plot(figsize=(10, 5), grid=True, color="g") plt.show() |
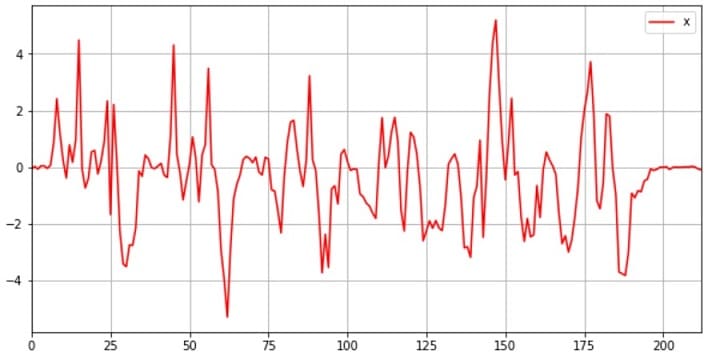
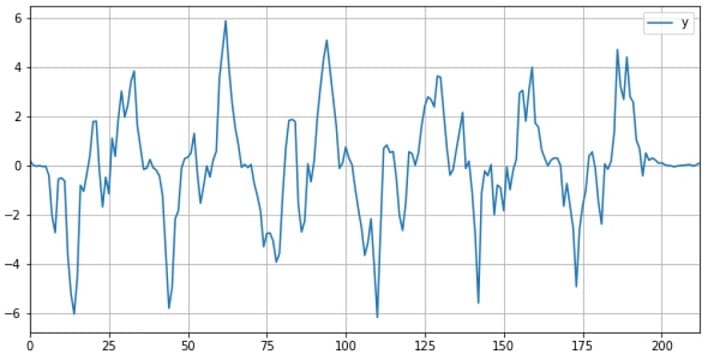
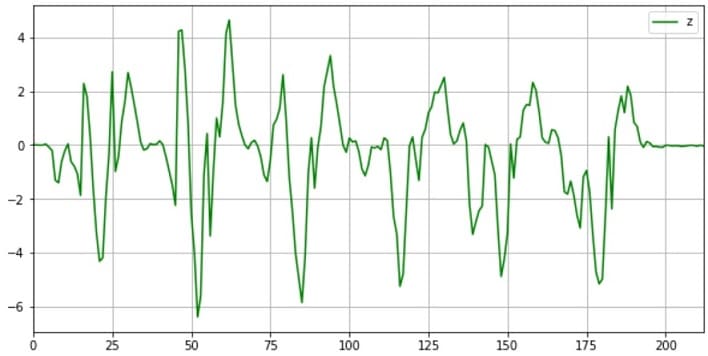
可視化により、傾向を把握することは、とても重要です
特徴量選択
z軸とy軸のジャイロ値が比較的きれいなデータ(周期的なデータ)なので使えそうです。今回はy軸データを採用します。
テーブルデータの1列目は日時のままでも良いのですが、今回はサンプリング周期0.1秒というのが明確に分かるように変換しておきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
y = df_y["y"] tmp_time = np.arange(0, len(y)) tmp_time = tmp_time * 0.1 df_train = df_y df_train["time"] = tmp_time plt.figure(figsize=(10, 5)) plt.plot(df_train["time"], df_train["y"]) plt.grid(True) plt.show() df_train.head() |
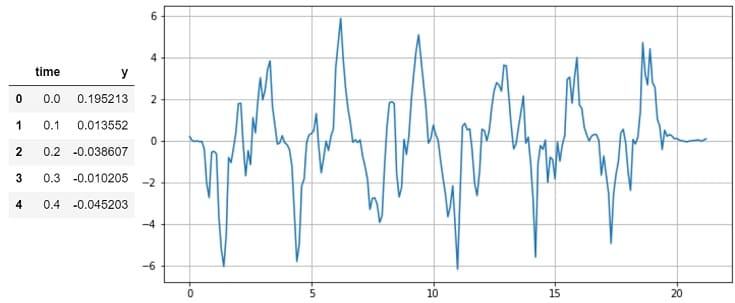
- モデル生成で使用するデータのことを”特徴量”と呼びます
- どの特徴量を採用するか?を検討する作業を”特徴量選定”と呼びます
波動拳データ抽出
波動拳6発の全データから、最初の1発目(0~4secのデータ)を抽出します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
y = df_train.iloc[0:40, 1] time = df_train.iloc[0:40, 0] plt.figure(figsize=(10, 5)) # 波動が放たれるタイミング(網掛け部分) plt.axvspan(2.5, 3.5,color="orange") plt.plot(time, y) plt.title("HADOUKEN !!") plt.xlabel("[s]") # plt.ylabel("[m/s^2]") plt.grid(True) plt.show() |
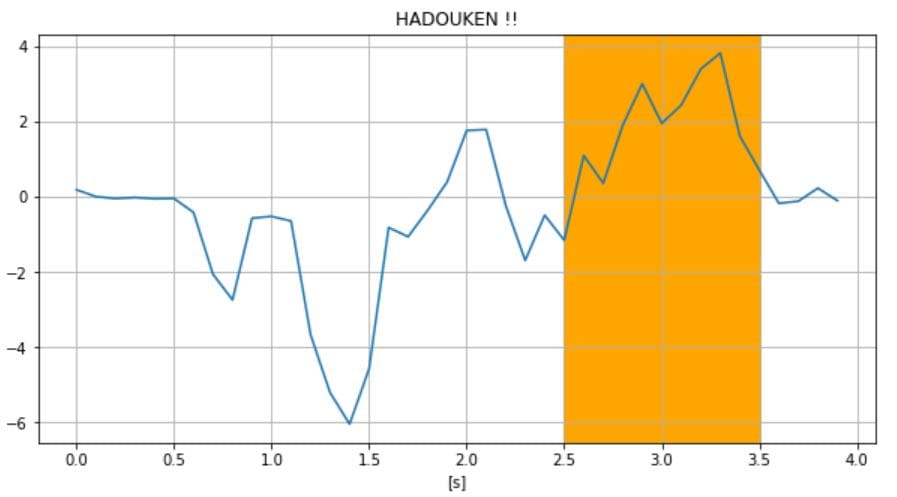
- データ全体を俯瞰することも重要
- データの一部を抽出して変化点などを観測するのも重要
多角的にデータを眺めることが非常に重要です(自論)
波動拳データ分析
波動拳データの波形を分析します。
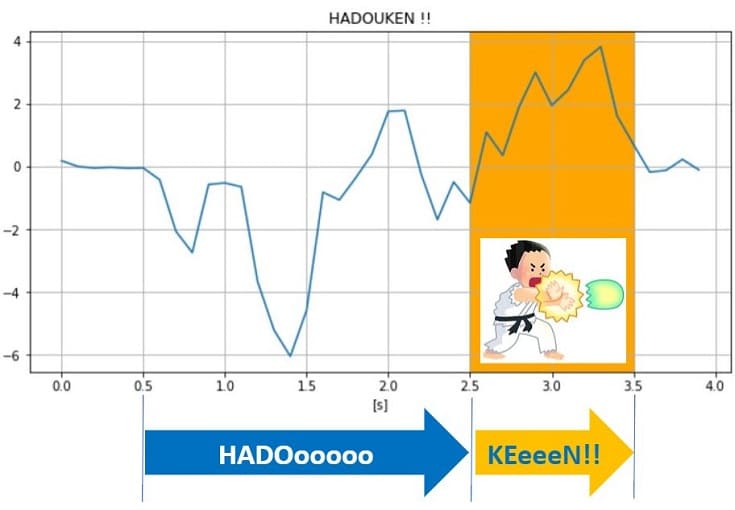
波動拳初心者”はやぶさ”の場合、撃ち始め~撃ち終わるまで3秒かかることが分かりました。
- 0~2.5sec:波動拳を撃つためのパワー捻出
- 2.5~3.5sec:波動を撃ち始めている(網掛け部分)
- 3.5~*sec:波動が飛んでくる
問題設定
波動拳の波形データを簡単に言語化すると以下の通りです。
『小さい谷→大きい谷→小さい山→大きい山(網掛け部分)』
波動パワーを捻出している『小さい谷→大きい谷→小さい山』を検出し、次に『大きな山(網掛け部分)』が来ることを予測できれば…
『1秒後に波動が飛んでくることを予測できた!』と言えます。
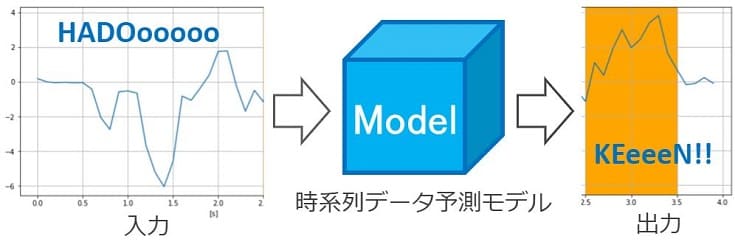
この予測にLSTMを使います!
機械学習(深層学習含む)は「いい加減なデータを入力 ⇒ 欲しい情報を出力」という”万能ツール”ではありません。適切なデータ入力・適切な問題設定が重要ですし、問題次第では機械学習以外の手法を選択することが重要です(自論)
【実践】LSTMで時系列データ予測
以降から、LSTMを実践していきます。訓練(学習)フェーズと予測(推論)フェーズがあるので、順番に説明します。
【LSTM実践フロー】
- 波動拳のパターン(時系列データ)を学習
- 波動パワー捻出 “小谷→大谷→小山” ⇒ 波動が飛んでくる”大山”を予測
データセット生成
波動拳6発の全データのうち、1~5発(時系列データ:0~16.3sec)を訓練データとします。以下のコードで訓練用データセットを生成します。
|
1 2 3 4 5 6 |
from gluonts.dataset.common import ListDataset training_data = ListDataset( [{"start": df_train.index[0], "target": df_train.iloc[0:163, 1]}], freq = "0.1S") |
また、6発目の波動拳(時系列データ:16.3~18.3sec)でテスト用データセットを生成します。
|
1 2 3 |
test_data = ListDataset( [{"start": df_train.index[0], "target": df_train.iloc[163:183, 1]}], freq = "0.1S") |
学習
今回は、SimpleFeedForwardEstimatorを使用し、時系列データ予測モデル生成します。
HADOooooo(context_length=20プロットのデータ)を使って、KEeeen!!(prediction_length=10プロットのデータ)を予測するように学習(訓練)したいので、ハイパーパラメータを以下のように設定しました。
【ハイパーパラメータ】
- サンプリング周期:freq=”0.1S”
- 予測に使うデータ数:context_length=20
- 予測するデータ数:prediction_length=10
- 学習回数:epochs=1000
- バッチサイズ:batch_size=32
- 学習率:learning_rate=0.001
※他の項目は”デフォルト設定”です(引数に何も書かなければ”デフォルト設定”になります)
コードは以下の通りです。
|
1 2 3 4 5 6 7 8 9 10 11 |
from gluonts.model.simple_feedforward import SimpleFeedForwardEstimator from gluonts.trainer import Trainer estimator = SimpleFeedForwardEstimator(freq="0.1S", context_length=20, prediction_length=10, trainer=Trainer(epochs=300, batch_size=32, learning_rate=0.001)) predictor = estimator.train(training_data=training_data) |
推論
学習済みモデル(predictor)を使って、波動拳が飛んでくる”大山”を予測してみます。
|
1 2 3 4 5 6 7 8 9 10 11 |
from gluonts.dataset.util import to_pandas for test_entry, forecast in zip(test_data, predictor.predict(test_data)): plt.figure(figsize=(10, 5)) to_pandas(test_entry).plot(linewidth=2) forecast.plot(color='g', prediction_intervals=[50.0, 90.0]) plt.title("HADOUKEN Prediction !!") plt.legend(["observations", "median prediction", "90% confidence interval", "50% confidence interval"], loc='lower left') plt.grid(which='both') |
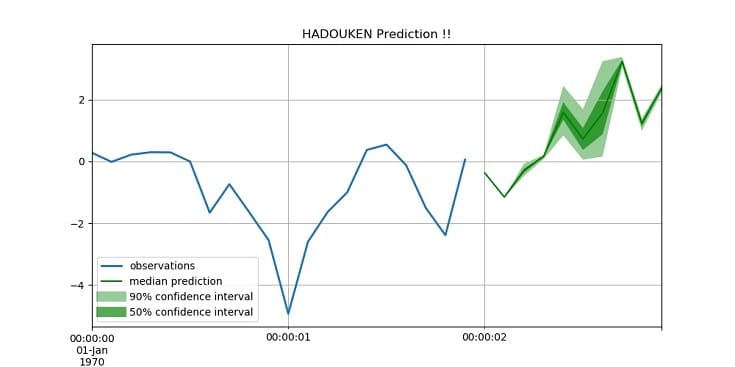
↑予測結果。↓作りたいモデルです。ちゃんと“大山”がくることを予測できていますね!
ノリノリの”くるる”ちゃんが今日も可愛い(*・ω・)ノ♪
以上までが時系列データモデルの学習から推論までのフローになります。
モデル保存
良いモデルを生成できたら、tmpフォルダに保存しましょう。
|
1 2 3 4 |
# save the trained model in tmp/ from pathlib import Path predictor.serialize(Path("./tmp/")) |
学習済みモデルで推論
推論(予測)をするだけなら、学習(訓練)を毎回する必要はありません。最後に、学習済みモデルを使った推論を実践します。コードは以下の通りです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import matplotlib.pyplot as plt from pathlib import Path import pandas as pd from gluonts.dataset.util import to_pandas from gluonts.dataset.common import ListDataset from gluonts.model.predictor import Predictor # 波動拳サンプルデータ読込み df_sample = pd.read_csv('./hadou_data/train/y.txt', names=['time', 'y']) # df_sample = pd.read_csv('./hadou_data/test/y.txt', names=['time', 'y']) # 学習済みモデル読込み(epoch=1000) predictor_deserialized = Predictor.deserialize(Path("./tmp/")) # テスト用データセット生成 test_sample = ListDataset( [{"start": df_sample.index[0], "target": df_sample.iloc[163:183, 1]}], freq = "0.1S") # test_sample = ListDataset( # [{"start": df_sample.index[0], "target": df_sample.iloc[163:-30, 1]}], # freq = "0.1S") # 予測 for test_entry, forecast in zip(test_sample, predictor_deserialized.predict(test_sample)): plt.figure(figsize=(10, 5)) to_pandas(test_entry).plot(linewidth=2) forecast.plot(color='g', prediction_intervals=[50.0, 90.0]) # 可視化 plt.title("HADOUKEN Prediction !!") plt.legend(["observations", "median prediction", "90% confidence interval", "50% confidence interval"], loc='lower left') plt.grid(which='both') plt.show() |
エッジディバイスなどでは、推論(予測)処理のみを行いたい場合が多いので、”推論用コード”も作っておきました。
まとめ
LSTMの概要説明から始まり、実データを使った時系列データ予測まで実践しました。
今回は、SimpleFeedForwardEstimatorを使いましたが、DeepAREstimatorなども、同じ要領で試せるので、本記事のコードを改良して色々と楽しんで頂ければと思います。
今回は、題材として”波動拳”を採用しましたが、アイデア次第で様々な応用が考えられます。本記事をきっかけに…
という人が現れたら最高に嬉しいです。
”くるる”ちゃんのように自由に楽しく勉強してくれたら嬉しいです(*・ω・)ノ♪

















