こんにちは。
現役エンジニアの”はやぶさ”@Cpp_Learningです。仕事でもプライベートでも機械学習で色々やってます。
今回は機械学習モデルの説明性・解釈性(Interpretable Machine Learning)について勉強したので、備忘録も兼ねて本記事を書きます。
Contents
機械学習とタスクについて
回帰や分類などのタスクに機械学習モデルを活用することがあります。
例えば、以下の記事ではフクロウの種類を分類するために深層学習モデルを活用しています。

この記事の場合「推論精度が良ければOK」・「誤差が小さければOK」などモデルの出力結果のみを考慮するタスクでしたが…
「なぜモデルが○○という予測をしたのか?」というモデルの説明性・解釈性が重要なタスクもあります。


※頭部から異常発熱
例えば上図のように異常(ロボットの故障)を検出するだけでなく、異常の要因(頭部の異常な発熱など)を明らかにしたいタスクがあります。
つまりモデルが何を根拠に推論したか?どの特徴量が重要だったのか?などを明示したいタスクもあります。
モデルの説明性・解釈性について
モデルの説明性・解釈性について、大きく2つのアプローチ方法があると考えています。
- 人間が解釈可能なアルゴリズムを採用
- 統計モデリング、決定木など
- ブラックボックスモデルの出力結果に対し、根拠を探求
- SHAP、LIMEなど
- ニューラルネットワークの中間層の情報を可視化など
前者の統計モデリングなどについては、そもそもアルゴリズムが解釈可能なので、当然モデルの出力結果も解釈可能です。
後者については、ニューラルネットワークなどのブラックボックスモデルに対し、大局的な説明や局所的な説明を探求する方法です。
- 大局的な説明:モデルにとって重要な特徴量を明示する方法
- 局所的な説明:モデルの出力結果に寄与した特徴量を明示する方法
以降、本記事では局所的な説明をメインで説明します。
LIMEによるモデル解釈
LIME を活用することで、ブラックボックスモデル(LightGBMや深層学習モデルなど)の出力結果に対し、寄与した特徴量を明示できます。
LIMEの詳細については以下の資料が参考になります。
SHAPによるモデル解釈
LIME以外に SHAP という手法もあります。
引用元:shap|GitHub
SHAPの詳細については以下の資料が参考になります。
各手法の比較
SHAP・LIME・Anchor などを比較している以下のスライドが非常に参考になります。スライドp35より、テーブルデータにはSHAPを採用するのが良さそうです。
https://www.slideshare.net/DeepLearningLab/blackbox-198324328
本記事で説明しきれなかった手法については、以下の資料が参考になります。
実践!SHAPによるモデル解釈
SHAPによるモデル解釈を実践してみます。
問題設定(タスク)とモデル(LightGBM)
今回は機械学習の定番チュートリアル ボストンの住宅価格の予測に LightGBM を採用します。
対象がテーブルデータなのでSHAPを採用しました
インストール
最初に以下のコマンドでSHAPをインストールします。
pip install shap
Google Colaboratoryなら以上で準備完了です。以降からソースコードを書いてきます。
本記事のソースコードはGoogle Colaboratoryで動作確認しました(2020/05/01)
Import
まずはimportから
|
1 2 3 4 5 6 7 8 9 |
import numpy as np import pandas as pd from matplotlib import pyplot as plt import lightgbm as lgb from sklearn.model_selection import train_test_split # from sklearn.metrics import mean_squared_error import shap |
データセット
データセットをtrainとtestに分けます。
|
1 2 3 4 5 |
X, y = shap.datasets.boston() X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # print(len(X_train)) # print(len(X_test)) # X.head() |
学習
LightGBMの各パラメータを適当にセットして学習します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# create dataset for lightgbm lgb_train = lgb.Dataset(X_train, y_train) lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train) # LightGBM parameters params = { 'objective' : 'regression', 'metric' : 'rmse', 'num_leaves' : 31, 'learning_rate' : 0.1, 'feature_fraction' : 1.0, 'bagging_fraction' : 1.0, 'bagging_freq': 0, 'verbose' : 0, 'min_child_samples': 5 } # train model = lgb.train(params, lgb_train, num_boost_round=200, valid_sets=lgb_eval, early_stopping_rounds=10) |
推論
以下のコードでTestデータの住宅価格を予測できます。
|
1 2 3 4 5 6 7 8 |
y_pred = model.predict(X_test, num_iteration=model.best_iteration) # metric = y_test-y_pred plt.figure(figsize=(10, 4)) plt.plot(y_test, label="y") plt.plot(y_pred, label="y_pred") # plt.plot(metric) plt.legend() plt.show |
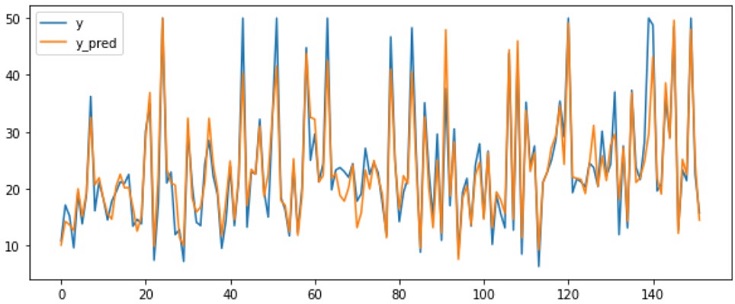
真値と予測値を可視化すると、割と精度良く価格予測できていることが分かります。
さて、本題はモデルの出力結果(価格予測の精度)ではなく、なぜモデルがそのような価格予測をしたか?を明らかにすることです。
モデルの出力結果を解釈する -任意データ-
SHAPを活用し、任意データ(ID=5など)のモデル出力結果に対し、どの特徴量が寄与したかを明示します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# target data ID = 5 print("===== Explanatory variable =====") print(X_train.iloc[ID,:]) print("====== Response variable =======") print("y:", y_train[ID]) # explain the model's predictions using SHAP # (same syntax works for LightGBM, CatBoost, scikit-learn and spark models) explainer = shap.TreeExplainer(model) shap_values = explainer.shap_values(X_train) # load JS visualization code to notebook shap.initjs() # visualize the 5th prediction's explanation (use matplotlib=True to avoid Javascript) shap.force_plot(explainer.expected_value, shap_values[ID,:], X_train.iloc[ID,:]) |
===== Explanatory variable =====
CRIM 0.16902
ZN 0.00000
INDUS 25.65000
CHAS 0.00000
NOX 0.58100
RM 5.98600
AGE 88.40000
DIS 1.99290
RAD 2.00000
TAX 188.00000
PTRATIO 19.10000
B 385.02000
LSTAT 14.81000
====== Response variable =======
y: 21.4

この結果から以下のことが分かります。
- 全Trainデータの予測値平均(base value):22.2
- ID:5の住宅価格の真値(y):21.4
- モデルの出力結果(model output value):21.22
- 予測価格を下げるのに寄与した特徴量:LSTAT=14.81など
- 予測価格を上げるのに寄与した特徴量:TAX=188など
これだけでも十分スゴイけど、なぜモデルはRM(部屋数)=5.986のとき、価格が下がると判断したのか?を深堀りしてみます。
モデルの出力結果を解釈する -全データ-
全Trainデータに対し、上図と同じ数直線を算出後、90度回転させて並べたグラフを作成します。
|
1 2 3 4 5 |
# load JS visualization code to notebook shap.initjs() # visualize the training set predictions shap.force_plot(explainer.expected_value, shap_values, X_train) |
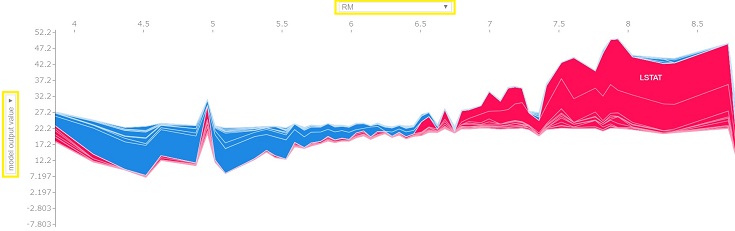
縦軸・横軸の設定は任意に変更できます。今回は縦軸をモデル出力結果(価格予測結果)、横軸をRM(部屋数)に設定しました。
どうやらモデルはRM=6.5を境界にhigher/lowerを判断してそうです。
日本だと6部屋もある住宅の価格はとても高そうですが、ボストンだと6.5部屋以下なら平均的な住宅価格よりも安いとモデルは予測したようです。
モデルの出力結果に寄与した特徴量を確認できます
特徴量別の可視化
以下のコードでも特徴量別の重要度(SHAP値)を可視化できます。
|
1 2 3 4 |
# create a dependence plot to show the effect of a single feature across the whole dataset shap.dependence_plot("RM", shap_values, X_train) |
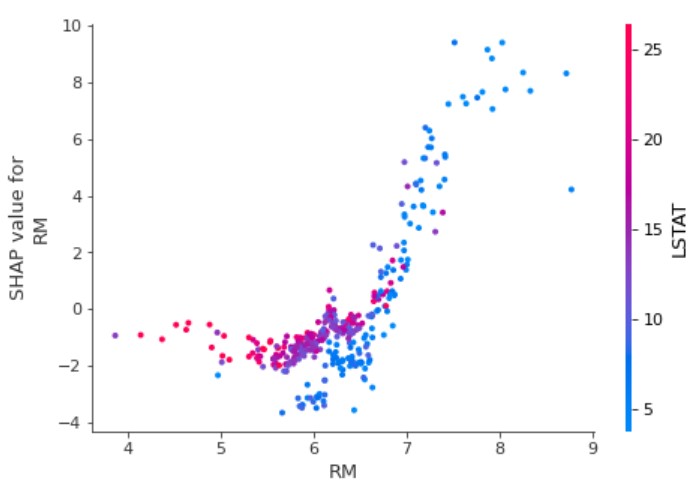
可視化することで、出力結果とRMの関係がよく分かります。
また、特に交互作用のある特徴量(今回の例だとLSTAT)を自動で選定し、色付けされます。RMが小さいほど、LSTATが大きくなる関係(負の相関)があるようです。
各特徴量の重要度を可視化
各特徴量の重要度(SHAP値の平均絶対値)を取得し、棒グラフで可視化することもできます。
|
1 2 3 |
shap.summary_plot(shap_values, X_train, plot_type="bar") |
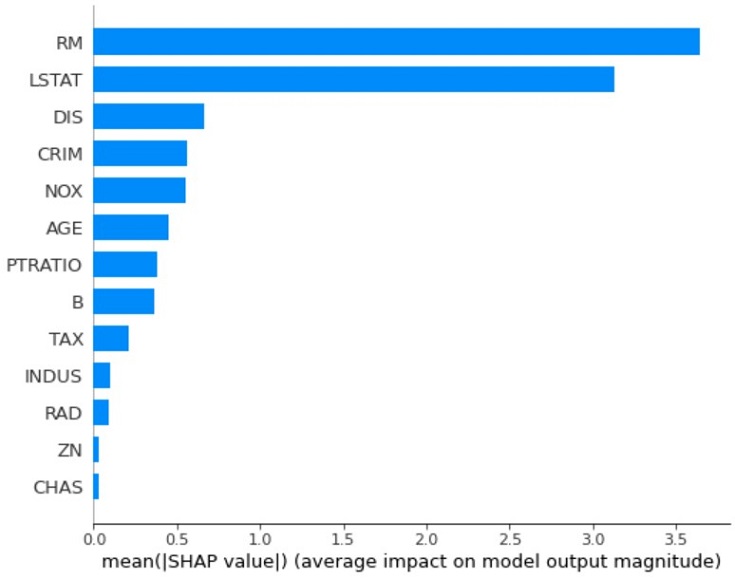
RM・LSTAT・DISが重要な特徴量であることを確認できます。
以上の結果から部屋数が分かれば、ある程度ボストンの住宅価格(平均価格よりも高いか低いかなど)を予測できそうです。
【補足】LightGBMで特徴量重要度を可視化
LightGBMにも特徴量重要度を可視化する機能があります。
|
1 2 3 |
# 特徴量の重要度をプロットする lgb.plot_importance(model) plt.show() |
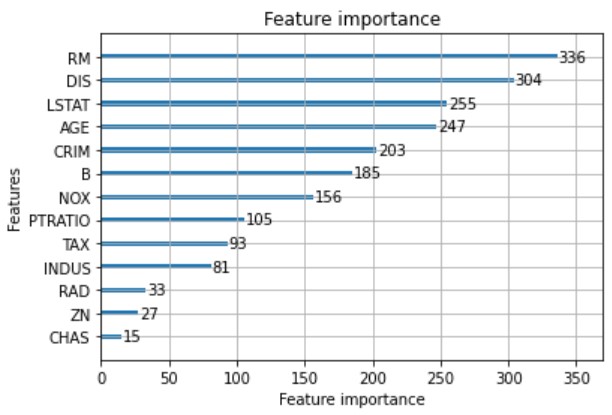
SHAP同様にRM・LSTAT・DISが重要な特徴量であることを確認できました。
おわりに -モデルの説明性・解釈性に対する注意点-
今回ブラックボックスモデルの出力結果に対し、根拠を探求するため、SHAPを活用しました。
各特徴量の重要度(SHAP値)の可視化により、モデル出力結果に対し、納得感を得られたと感じています。
ただし、ブラックボックスモデルを解釈できたか?と言われると疑問が残ります。
モデルの予測精度さえ良ければOK!ではなく、タスクやクライアントに応じて、最適な手法(ニーズにフィットする手法)を検討する必要がありますね。
問題解決に必要な技術と知識を蓄え、課題に応じて最適な技術を選択あるいは組み合わせを検討できるエンジニアはとてもカッコイイと思います(自論)