こんにちは。
現役エンジニアの”はやぶさ”@Cpp_Learningです。CVPR2020を眺めてたら、距離学習がやりたくなってきた!
というわけで 損失関数のCircle Loss について勉強したので、備忘録も兼ねて本記事を書きます。
CVPR2020とは
CVPR(Computer Vision and Pattern Recognition)とは、コンピュータビジョン分野における有名な国際学会です。CVPRに論文採択されるのは、とても名誉なことです。
CVPR2020については、以下の記事が参考になります。
深層距離学習(Deep Metric Learning)のCVPR2020採択論文
深層距離学習(Deep Metric Learning)関連のCVPR2020採択論文をまとめました。
【CVPR2020 Deep Metric Learning】
- Deep Metric Learning via Adaptive Learnable Assessment
- Proxy Anchor Loss for Deep Metric Learning
- End-to-End Illuminant Estimation Based on Deep Metric Learning
- Universal Weighting Metric Learning for Cross-Modal Matching
- Moving in the Right Direction: A Regularization for Deep Metric Learning
- Circle Loss: A Unified Perspective of Pair Similarity Optimization
- Hyperbolic Image Embeddings
- Embedding Expansion: Augmentation in Embedding Space for Deep Metric Learning
- Fast(er) Reconstruction of Shredded Text Documents via Self-Supervised Deep Asymmetric Metric Learning
今回は Circle Loss: A Unified Perspective of Pair Similarity Optimization を紹介します。
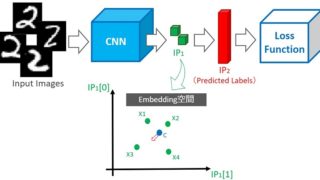
深層距離学習とは
深層距離学習とは、空間に埋め込んだデータに対し、クラスが同じデータ間の距離”Sn”は小さく・クラスが違うデータ間の距離”Sp”は大きくするように学習する手法です。
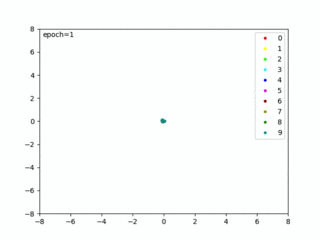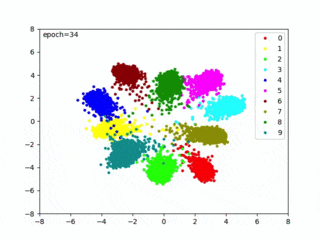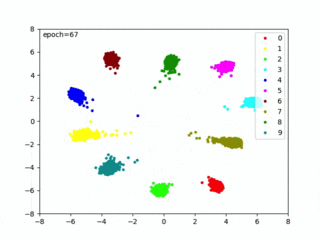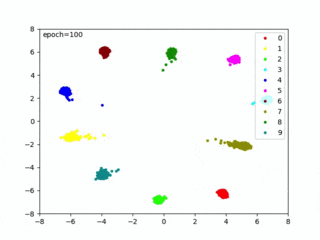
クラスタリング容易な埋め込み空間(Embedding Space)を生成しているともいえます。上図を実現する Center Loss については、以下の記事で紹介しています。
ソースコードも公開しているので、是非触ってみてください。
深層距離学習とは「データ間距離を最適化にする学習手法」あるいは「クラスタリング容易な埋め込み空間(Embedding Space)を生成する手法」
深層距離学習の手法
深層距離学習には大きく2つの系統があります。一つはデータ間のユークリッド距離を最適化する手法です(代表的な手法はTriplet Loss)。
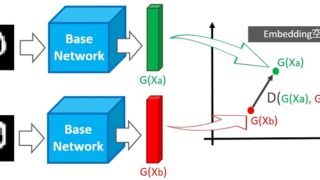
もう一方はSoftmax Lossをベースにし、空間に埋め込むデータ(および決定境界)の角度を最適化する手法です。
手法が違っても本質は同じ
Circle Lossの論文では Triplet Loss系・Softmax Loss系 のどちらの手法も(Sn-Sp)を目指しており、本質的には同じ最適手法だと主張しています。
【Loss func ⇒ Sn-Sp】
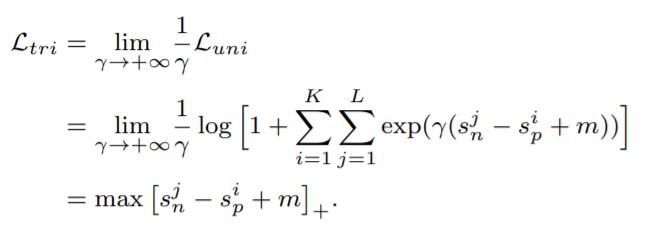
実際に各Loss関数を変形すると、上記の式が得られます。
従来手法 L=Sn-Sp について
繰り返しますが、従来手法は(Sn-Sp)を目指した最適手法です。
【Loss Func】
L = Sn – Sp
- クラスが同じデータ間の距離:Sn(データ間距離)を近くしたい
- クラスが違うデータ間の距離:Sp(クラス間距離)を遠くしたい
この式にマージンmを加えると以下の式が得られます。
【Loss Func with margin】
L = Sn – Sp + m
※マージン:m
説明の都合上、この式を少しだけ変形します。
【Loss Func with margin】
L = (Sn + m) – Sp
※mはハイパーパラメータ
この損失関数Lを”0”にする距離SnとSpを考えます。もしm=1ならSn⇒0、Sp⇒1に収束させれば、良いことが分かります。
つまり、距離Sn+mと距離Spの差分が小さくなるように学習(重みを自動調整)します。
従来手法の課題
従来手法のハイパーパラメータはmしかないので、距離Snおよび距離Spに対し、同じ強さのペナルティを与えています。
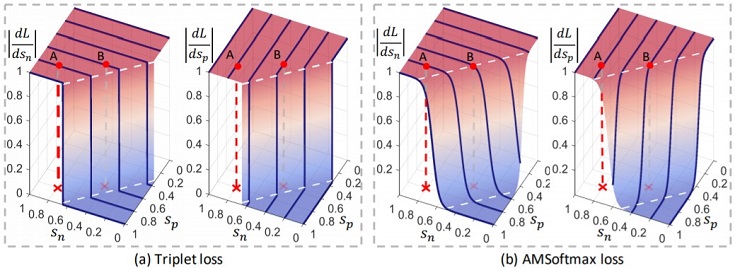
引用元:Circle Loss|論文
上図データAの各距離はSp=Sn=0.8なので、Snを”0”に収束させるため、大きく移動する必要があります。一方、Spは”1”までの距離が近いので、少し移動すれば良いです。
つまり、勾配dL/dSnを大きく、勾配dL/dSpを小さくすれば良いのですが、従来手法では距離Sn、Spともに同じ勾配になります。
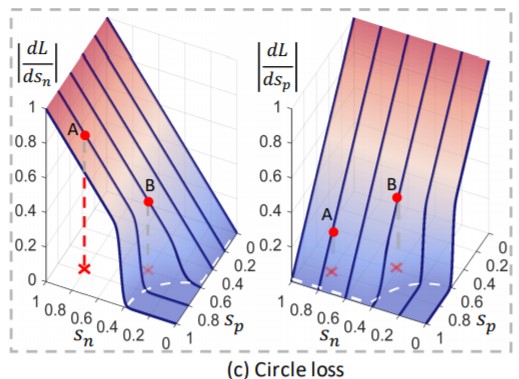
引用元:Circle Loss|論文
Circle Lossでは距離Sn、Spに応じて適度なペナルティを与えるので、データAに対し勾配dL/dSnは大きく、勾配dL/dSpは小さくを実現できます。
Circle Loss
ここまでの説明で、Circle Lossが距離Sn、Spを独立して調整できることを説明しました。具体的にどうやって調整するかについては式を見た方が分かりやすいです。
【Circle Loss】
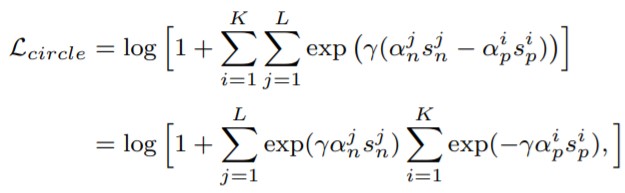
※ɤはハイパーパラメータ
Circle Lossは(Sn-Sp)を拡張した(αn*Sn-αp*Sp)を使います。このαn、αpにより独立して各距離を調整できます。
αn、αpの算出方法は割愛しますが、どちらもハイパーパラメータではないため、自動で調整されます。この式のハイパーパラメータはスケールを調整するɤのみです。
αn、αpの算出方法については、本記事の後半でCircle Lossのソースコードを公開するので、そのコードを解読してみて下さい。
Circle Loss の margin
先ほど説明した【Circle Loss】の式にマージン:Δp, Δnを追加したものが、実際に使われるLoss関数です。
【Circle Loss with margin】
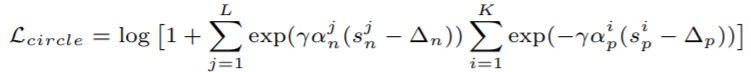
※Δp, Δn と ɤ がハイパーパラメータ
ハイパーパラメータが3つあるように見えるが、各マージンΔには以下の式が適用されます。
【margin for Circle Loss】
∆p = 1−m
∆n = m
※mがハイパーパラメータ
なので【Circle Loss】のハイパーパラメータはmとɤの2つです。
Circle Loss の ”Circle”って何
最後にハイパーパラメータmで何を調整するのかを説明します。
【Loss Func with margin】
L = (Sn + m) – Sp
従来手法の損失関数Lを”0”にするために、各距離をどう収束させるかを説明しました。同じことをCircle Lossでも考えてみます。
【Circle Loss ⇒ Sn-Sp】
αn(sn − ∆n) − αp(sp − ∆p) = 0
この式を変形したものが以下です。
【Circle】
![]()
これマージンmが半径の円の式ですね。この式からmに依存せず、Sp⇒1、Sn⇒0で最適化できることが分かります。
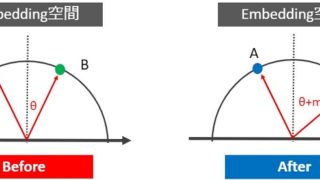
つまり下図のように、データ(緑プロット)が左上を収束するように学習します。
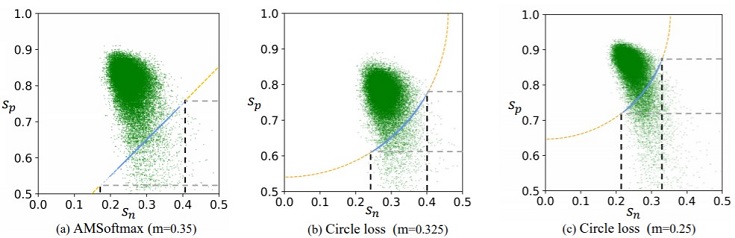
上図の破線は境界決定線を表現しており、従来手法(a)の境界決定線が直線なのに対し、Circle loss(b),(c)は円形になります。
緑プロットは”この境界”を横切りながら左上に向かいます。Circle lossでは円の半径(ハイパーパラメータm)を調整することで、各緑プロットを密集させながらSp⇒1、Sn⇒0に収束させることができます。
Circle Lossの名に相応しいアルゴリズムですね。
実践!深層距離学習 -Circle Loss編-
理論の説明はここまでにして、次は実践しましょう!circle_loss.py 参考に、お馴染みMNIST(画像分類)のソースコードを作成します。
import
最初はimportから
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import os from typing import Tuple from tqdm import tqdm import numpy as np import matplotlib.pyplot as plt from sklearn import manifold import torch from torch import nn, Tensor from torch import optim from torch.utils.data import DataLoader from torchvision import datasets, transforms import torch.optim.lr_scheduler as lr_scheduler from torchvision.transforms import ToTensor # from circle_loss import convert_label_to_similarity, CircleLoss |
最後の行をコメントアウトしているのは、本記事のコードをGoogle Colaboratoryに写経すれば簡単に実践できる形に修正したためです。
GPU/CPU設定
GPUが使用可能な環境ならGPUを使用し、そうでない場合はCPUを使用する設定にします。
|
1 2 3 4 |
use_cuda = torch.cuda.is_available() and True device = torch.device("cuda" if use_cuda else "cpu") |
DataLoader -MNISTダウンロード-
MNISTデータセットのダウンロードから前処理までを行う、関数を用意します。
|
1 2 3 4 5 6 7 8 9 10 11 |
def get_loader(is_train: bool, batch_size: int) -> DataLoader: trainset = datasets.MNIST( root="./data", train=is_train, transform=ToTensor(), download=True ) return DataLoader(trainset, batch_size=batch_size, shuffle=is_train) # data loder train_loader = get_loader(is_train=True, batch_size=64) |
今回はバッチサイズを64にします。
埋め込み空間を可視化
埋め込み空間を可視化する関数も作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
def visualize(features, labels, num_classes): # t-SNEで2次元に圧縮 tsne = manifold.TSNE(n_components=2, init='pca', random_state=501) features = tsne.fit_transform(features) # カラーマップ colors = ['C0', 'C1', 'C2', 'C3', 'C4', 'C5', 'C6', 'C7', 'C8', 'C9'] # 描画 for i in range(num_classes): plt.plot(features[labels == i, 0], features[labels == i, 1], '.', c=colors[i]) # グラフ設定 plt.legend(['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'], loc='upper right') plt.show() |
CircleLoss
Center Loss関数を自作します(circle_loss.pyコピペでOK)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
def convert_label_to_similarity(normed_feature: Tensor, label: Tensor) -> Tuple[Tensor, Tensor]: similarity_matrix = normed_feature @ normed_feature.transpose(1, 0) label_matrix = label.unsqueeze(1) == label.unsqueeze(0) positive_matrix = label_matrix.triu(diagonal=1) negative_matrix = label_matrix.logical_not().triu(diagonal=1) similarity_matrix = similarity_matrix.view(-1) positive_matrix = positive_matrix.view(-1) negative_matrix = negative_matrix.view(-1) return similarity_matrix[positive_matrix], similarity_matrix[negative_matrix] class CircleLoss(nn.Module): def __init__(self, m: float, gamma: float) -> None: super(CircleLoss, self).__init__() self.m = m self.gamma = gamma self.soft_plus = nn.Softplus() def forward(self, sp: Tensor, sn: Tensor) -> Tensor: ap = torch.clamp_min(- sp.detach() + 1 + self.m, min=0.) an = torch.clamp_min(sn.detach() + self.m, min=0.) delta_p = 1 - self.m delta_n = self.m logit_p = - ap * (sp - delta_p) * self.gamma logit_n = an * (sn - delta_n) * self.gamma loss = self.soft_plus(torch.logsumexp(logit_n, dim=0) + torch.logsumexp(logit_p, dim=0)) return loss |
本記事の前半で解説した理論と各パラメータや処理を見比べてみて下さい。
モデル設計
適当なCNNを設計します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
class Model(nn.Module): def __init__(self) -> None: super(Model, self).__init__() self.feature_extractor = nn.Sequential( nn.Conv2d(in_channels=1, out_channels=8, kernel_size=5), nn.MaxPool2d(kernel_size=2), nn.ReLU(), nn.Conv2d(in_channels=8, out_channels=16, kernel_size=5), nn.MaxPool2d(kernel_size=2), nn.ReLU(), nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3), nn.MaxPool2d(kernel_size=2), nn.ReLU(), ) def forward(self, input: Tensor) -> Tensor: feature = self.feature_extractor(input).mean(dim=[2, 3]) return nn.functional.normalize(feature) |
学習用の関数
学習用の関数まで作成したら、前準備完了です。
|
1 2 3 4 5 6 7 8 9 |
def train(criterion, epoch): print("Training... Epoch = %d" % epoch) for img, label in tqdm(train_loader): img, label = img.to(device), label.to(device) model.zero_grad() pred = model(img) loss = criterion(*convert_label_to_similarity(pred, label)) loss.backward() optimizer.step() |
学習
モデル/オプティマイザ(今回はSGD)/スケジューラ(必須ではない)/Loss関数を設定し、epoch=20で学習します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# model model = Model().to(device) # optimzer optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=1e-5) sheduler = lr_scheduler.StepLR(optimizer, 20, gamma=0.8) # CircleLoss criterion = CircleLoss(m=0.25, gamma=80).to(device) # Training for epoch in range(20): sheduler.step() train(criterion, epoch+1) |
CircleLossの引数(ハイパーパラメータ)を変更するなど、色々と試してみて下さい。
Center Lossの記事では学習中の埋め込み空間を可視化しましたが、今回は推論フェーズの埋め込み空間を可視化します。
(特に学習中の)埋め込み空間の可視化に時間がかかります
推論
先ほど学習したモデルを使って推論します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# data loader val_loader = get_loader(is_train=False, batch_size=2) # 保存用 all_features = [] all_labels = [] # 推論 for img, label in tqdm(val_loader): img, label = img.to(device), label.to(device) pred = model(img) all_features.append(pred.data.cpu().numpy()) all_labels.append(label.data.cpu().numpy()) # 可視化 all_features = np.concatenate(all_features, 0) all_labels = np.concatenate(all_labels, 0) visualize(all_features, all_labels, 10) |
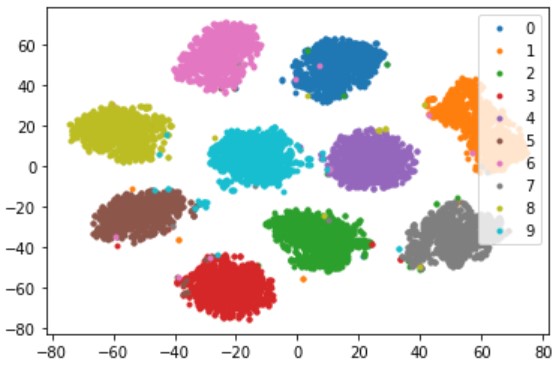
距離を最適化して、クラスタイング容易な埋め込み空間を生成できました。
まとめ
Center Lossの理論から実践まで徹底解説してみました。
最近は深層距離学習から離れてたけど、CVPR2020 で刺激をもらったので、久しぶりに解説記事を書きました。
この記事を含め、本サイトで公開中の【深層距離学習】徹底解説シリーズ記事 は4記事になりました(結構書いたな)。
本シリーズ記事は書くの大変なんだけど…

というモチベーションで書いてます。