こんにちは。
現役エンジニアの”はやぶさ”@Cpp_Learningです。最近、因果推論・因果探索を勉強してます。
今回は有向非循環グラフ(DAG:Directed Acyclic Graph)を推定する構造学習(Structure Learning)について勉強しました。
実践としてテーブルデータから説明変数を定義し、変数間の因果関係を推論するソースコード作成にも挑戦たので、備忘録も兼ねて本記事も書きます。
Contents
因果ダイアグラム -グラフ表現と因果関係について-
変数間の因果関係をグラフで表現したものを因果ダイアグラムと呼びます。下図は変数xと変数yの因果関係を表現した因果ダイアグラムです。
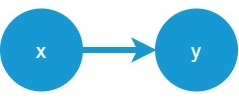
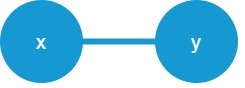
変数xが変数yに影響を与えるなど、向きが明確な場合は矢印(有向エッジ)を用います。一方、因果はあるけど、向きが分からない場合は線のみ(無向エッジ)で結合します。
ここでいう変数(青●)をノード、矢印をエッジと呼ぶこともあります。グラフ関連の用語については、以下の記事で紹介しています。
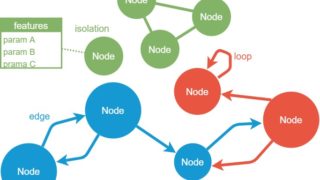
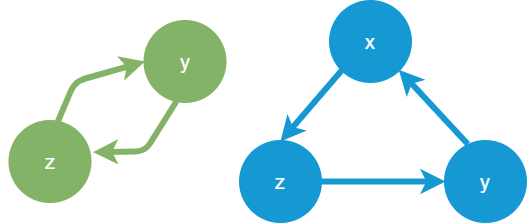
循環グラフとは
下図のように、あるノード(変数zなど)を起点としたとき、巡り巡って変数zに戻ってくるグラフのことを循環グラフ(または巡回グラフ)と呼びます。
有向非循環グラフ(DAG:Directed Acyclic Graph)とは
本記事では代表的な因果ダイアグラムの有向非循環グラフを扱います(下図参照)。
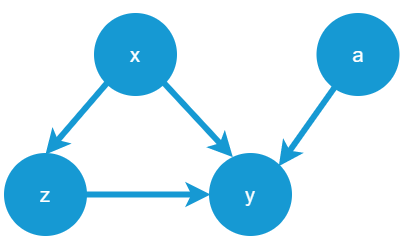
有向は矢印、非循環はループ無しというの意味です。つまり有向非循環グラフとは、因果関係を有向エッジで表現し、かつ(非循環なので)ループせずに必ずどこかのノードが終点となるグラフのことです。
ベイジアンネットワーク
ノード間の因果関係をグラフと条件付き確率表(CPT:Conditional Probability Table)で表現したものをベイジアンネットワークと呼びます。
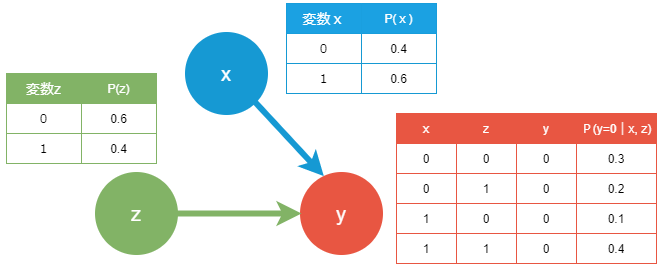
構造学習とは
今まで説明したグラフ構造(またはネットワーク構造)を推定する手法に構造学習があります。
本記事の後半で、構造学習による観測データの因果関係を考慮したネットワーク構造(DAG)推定に挑戦します。
DAG推定後、条件付き確率まで算出することも可能です。つまり構造学習でベイジアンネットワーク推定もできます。
構造学習用のPythonライブラリ CausalNex
今回は構造学習用のPythonライブラリ CausalNex を使います。
- 最先端の構造学習手法 DAG with NO TEARS を使用できる
- ドメイン知識によるグラフ補正機能あり
- 各変数の因果関係を考慮したグラフ構造を推定できる
- 推定結果のグラフを簡単に可視化(変数間の因果関係を目視確認)できる
- 条件付き確率も算出できる
など
公式Githubに書いてありますが、以下のコマンドで簡単にインストールできます。
pip install causalnex
実践!構造学習 -テーブルデータからDAGを推定-
機械学習チュートリアルでお馴染みの ボストンの住宅価格データセット を採用し、目的変数の住宅価格(PRICE)と各説明変数との因果推論に挑戦します。
Import
まずはimportから
|
1 2 3 4 5 6 7 8 9 |
import pandas as pd import numpy as np import matplotlib.pyplot as plt import networkx as nx from sklearn.datasets import load_boston from causalnex.structure.notears import from_pandas from causalnex.structure import StructureModel |
データセットをダウンロード
データセットをダウンロードし、テーブルデータの中身を確認しておきます。
|
1 2 3 4 5 |
boston = load_boston() boston_df = pd.DataFrame(boston.data, columns=boston.feature_names) # 説明変数 boston_df['PRICE'] = boston.target # 目的変数を追加 boston_df.head(3) |

構造学習によるDAG推定
CausalNexを使えば、わずか1行でテーブルデータからDAGを推定できます。
|
1 2 3 |
SM = from_pandas(boston_df) |
DAG(ネットワーク)可視化
推定結果のグラフ(ネットワーク)構造を NetworkX で可視化します。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
plt.figure(figsize=(18,10)) pos = nx.spring_layout(SM, k=60) edge_width = [ d['weight']*0.3 for (u,v,d) in SM.edges(data=True)] nx.draw_networkx_labels(SM, pos, fontsize=16, font_family="Yu Gothic", font_weight="bold") nx.draw_networkx(SM, pos, node_size=4000, arrowsize=20, alpha=0.6, edge_color='b', width=edge_width) |
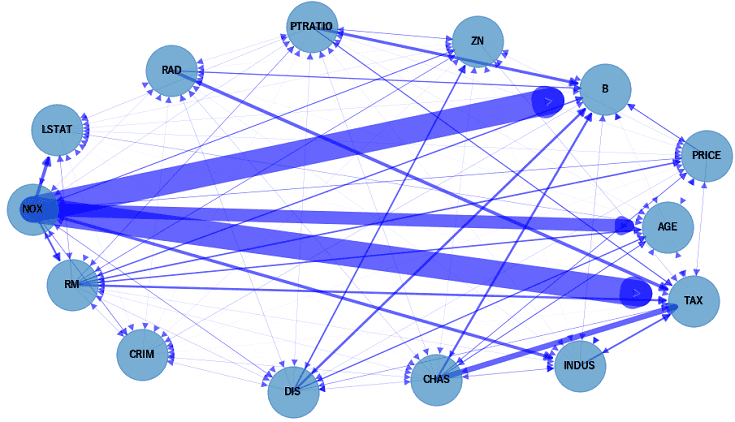
因果関係の強弱をエッジ(矢印)の太さで表現しています。例えば、NOXはB/AGE/TAXと強い因果関係があることが分かります。
因果関係の弱いエッジを削除
因果関係の弱いエッジ(線が細い矢印)を削除してから、再び可視化します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# グラフをコピー COPY_SM = SM.copy() # 因果関係の弱いエッジを削除 COPY_SM.remove_edges_below_threshold(0.5) # 可視化 plt.figure(figsize=(18,10)) pos = nx.spring_layout(COPY_SM, k=60) edge_width = [ d['weight']*0.3 for (u,v,d) in COPY_SM.edges(data=True)] nx.draw_networkx_labels(COPY_SM, pos, fontsize=16, font_family="Yu Gothic", font_weight="bold") nx.draw_networkx(COPY_SM, pos, node_size=4000, arrowsize=20, alpha=0.6, edge_color='b', width=edge_width) |
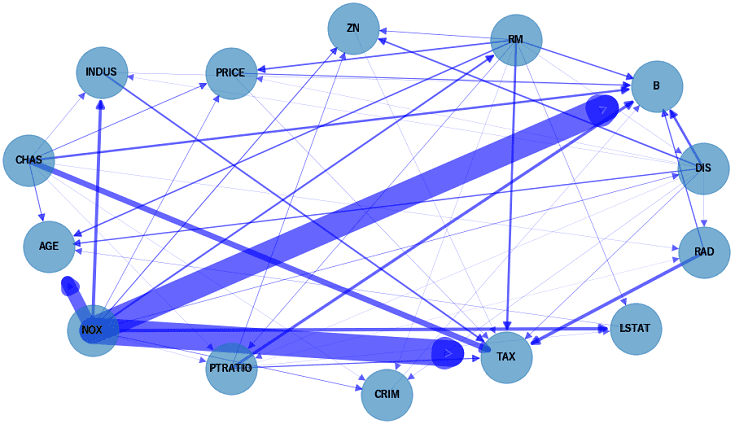
スッキリしたグラフになりました。さてエッジを確認すると、目的変数のPRICEと因果関係のある説明変数がRM/CHAS/NOX/DISだと分かります。
特にRM(部屋数)から伸びるエッジは太いので「部屋数が住宅価格に強い影響を与える」という推定結果です。
そのグラフ推定結果は適切か?
データを活用して何かするとき、手元にある観測データのみから、各種検討している点について、常に意識する必要があります。
例えば、機械学習(本記事では構造学習)などを使う際、観測データのみからモデル生成している点について、注意が必要です。
改めて上図のグラフを見ると、CHAS ⇒ PRICE を確認できますが、CHAS(川辺の家か否か)が住宅価格に直接影響を与えるものでしょうか?
美味しい魚が大量にとれる川なら、その土地の価値は高そうですし、川の氾濫などの災害を考慮した丈夫な住宅なら、住宅価格は高そうです。他にも文化的に価値の高い川とか…
要するに 川(特徴的な土地)⇒ ○○ ⇒ 住宅価格 という因果関係が常識的な気がします。
また PRICE ⇒ TAX/B という因果関係も確認できます。今回は住宅価格に影響を与える説明変数を知りたいので、HOGE ⇒ PRICE と逆向きのエッジあるいはノードは削除して良いと思います。
ドメイン知識・常識的な知識・モデル生成に使用しなかった情報なども考慮して、推定結果を考察することが重要です。
私は住宅価格に関するドメイン知識を持っていません(*・ω・)ノ♪
ドメイン知識によるグラフ補正
CausalNex にはドメイン知識によるグラフ補正機能があります。今回は TAXとBのノード削除 と CHAS ⇒ PRICE のエッジ削除 をしてみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# グラフをコピー D_SM = SM.copy() # 因果関係の弱いエッジを削除 D_SM.remove_edges_below_threshold(0.5) # ノード削除 D_SM.remove_nodes_from(['TAX', 'B']) # エッジ削除 D_SM.remove_edge('CHAS', 'PRICE') # 可視化 plt.figure(figsize=(18,10)) pos = nx.spring_layout(D_SM, k=60) edge_width = [ d['weight']*0.6 for (u,v,d) in D_SM.edges(data=True)] nx.draw_networkx_labels(D_SM, pos, fontsize=16, font_family="Yu Gothic", font_weight="bold") nx.draw_networkx(D_SM, pos, node_size=4000, arrowsize=20, alpha=0.6, edge_color='b', width=edge_width) |
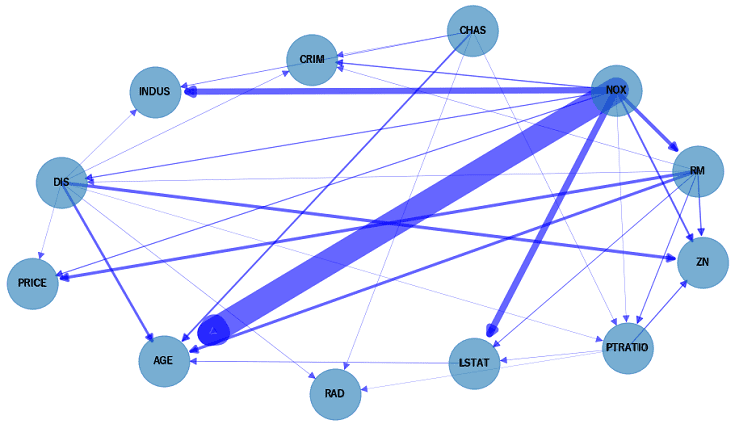
今回はエッジやノードを削除する補正をしましたが、追加する補正もできます(例えば AGE ⇒ PRICE のエッジ追加 など)
以上から PRICE(住宅価格)に影響を与える説明変数は RM/NOX/DIS で、特にRM(部屋数)の因果関係が強いという推定結果でした。
つまり RM/NOX/DIS のみから、PRICE を推定できる見込みがあります。
【おまけ】モデル説明性・解釈性と因果推論の紐づけ
実は下記の記事でも、重要な説明変数(特徴量)を把握するために、色々トライしています。

この記事では LSTAT も重要という結果でしたが、RMとLSTAT に相関関係があるので、最終的には「RMが分かれば、ある程度PRICEを推定できそう」という結論でした。
今回の構造学習でも RM ⇒ LSTAT の因果関係を確認でき、かつ RM ⇒ PRICE の因果関係が強いことも分かったので、「RMさえ分かれば良いかも」という同じ結論を出せます。
各種検討を行い、多角的な視点で考察することが重要です(自論)
まとめ
本記事で以下の内容を説明しました。
- 有向非循環グラフ(DAG:Directed Acyclic Graph)の概要
- 構造学習というグラフ(ネットワーク)推定手法について
- 構造学習用のPythonライブラリ CausalNex の紹介
- テーブルデータのグラフ推定から可視化までの実践ソースコード
- データや推定結果を疑うマインド(考え方)について
本記事が少しでも参考になれば嬉しいです。また内容の誤りに気付いた人は、優しく教えて頂けたら嬉しいです。
因果推論は奥が深いので、もっと勉強したいと思いました。