
こんにちは。現役エンジニアの”はやぶさ”@Cpp_Learningです。
WSL2 + Docker + VS Code の Remote – Containers のPython開発環境が最高だったので、構築方法と実践チュートリアルを紹介します。
Contents
いままでのPython開発環境
WSL + VS Code のPython開発環境については下記で紹介しました。

上記と本記事では以下の点が異なります。
- WSL1 ⇒ WSL2 に移行
- Docker 導入
- VS Code の Remote – Containers 導入
各種のインストール手順を説明します。
WSL2インストール
Windows 10 のバージョンが WSL2 の実行に関する要件を満たしていること
BIOS画面からCPUの仮想化を有効にする
以下を参考にBIOS画面からCPUの仮想化を有効にします。
BIOS画面の表示方法はPCによって異なります。私が使っているHP の場合、PC起動時にF10を連打すれば、BIOS画面が立ち上がります。
Linux ディストリビューション:Ubuntu 20.04 LTSのインストール
あとはの通りにやればOKです。手順6で任意のLinux ディストリビューションをインストールします。悩む人には Ubuntu 20.04 LTS をオススメしておきます。
以上で WSL2 のインストール完了です。
Visual Studio Codeインストール
Visual Studio Code(通称VS Code)を公式サイトからインストールします。
以下の手順で VS Code から WSL2 に接続できます。
- VS Code左下の「><」をクリック
- Remote-WSLを選択
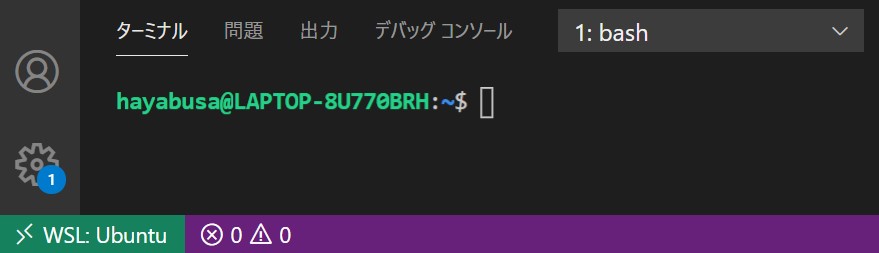
- 左下が「>< WSL: Ubuntu」になったら、ターミナルを開く
問題なければ、下図のように表示されます。Windowsマシンで VS Code + Ubuntu ターミナルが使える時点で既に快適です。
Docker Desktopインストール
続いて Docker Desktop をインストールします。インストール途中で WSL2 を利用するか聞かれるので、チェックを入れます☑
先ほどのターミナルに docker -v と入力し、問題なければ下図のように Docker バージョンが表示されます。
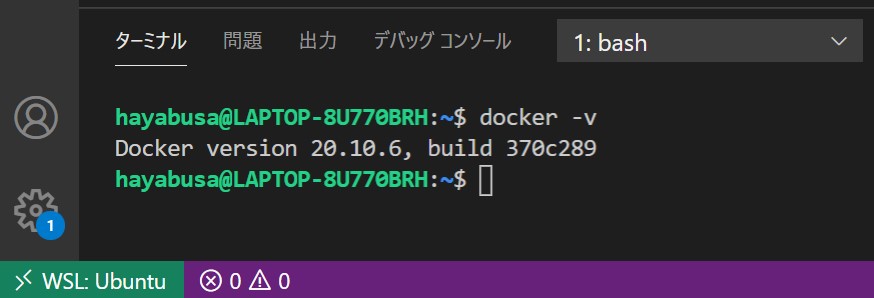
この時点で WSL2 + Docker + VS Code の環境構築完了です。
VS Code 拡張機能:Remote – Containersインストール
最後に VS Code 拡張機能の Remote – Containers をインストールします。あと拡張機能の Docker も便利なので、インストール推奨です。
以下の手順で VS Code から Docker に接続できます。
- プロジェクトフォルダにDockerfile または docker-compose.ymlを用意
- プロジェクトフォルダをVS Codeから開く
- VS Code左下の「><」をクリック
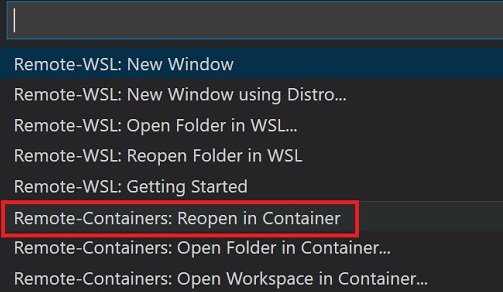
- Reopen in Container を選択
- From Dockerfile を選択
- 左下が「Dev Container: Existing Dockerfile」になったら接続成功
※次章の「チュートリアル」で詳しく説明します
Remote – Containers の使い方から後述するDockerfileの書き方まで、以下の記事が大変参考になりました。
実践 Dockerチュートリアル -Pythonで機械学習アプリ開発-
構築した開発環境を使って、簡単な機械学習サンプルコードを動かしてみます。
適当な場所に下記構成のプロジェクトフォルダ:docker-ml を作成します。
|
1 2 3 4 5 6 7 8 9 |
workspace └─docker-ml │──Dockerfile │──main.py │──pyproject.toml │ └──model |
Dockerfile
Python公式イメージに依存関係管理ツールの Poetry を入れたDockerfileを作成します。
|
1 2 3 4 5 6 7 8 9 10 |
FROM python:3.8 RUN set -x && \ curl -sSL https://raw.githubusercontent.com/sdispater/poetry/master/get-poetry.py | python ENV PATH /root/.poetry/bin:$PATH RUN poetry config virtualenvs.create false COPY pyproject.toml ./ RUN poetry install --no-root --no-dev |
下の2行を追加すれば、イメージのビルド時(コンテナ生成時)に pyproject.toml で定義した各パッケージを自動でインストールしてくれます。
pyproject.toml
pyproject.toml には main.py の動作に必要なパッケージをバージョン指定で定義します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
[tool.poetry] name = "docker-test" version = "0.1.0" description = "" authors = ["hayabusa <hayabusa@example.com>"] [tool.poetry.dependencies] python = ">=3.7.1" numpy = "^1.19.5" pandas = "^1.2.1" scikit-learn = "^0.24.1" palmerpenguins = "^0.1.4" [tool.poetry.dev-dependencies] pytest = "^6.2.2" [build-system] requires = ["poetry-core>=1.0.0"] build-backend = "poetry.core.masonry.api" |
(※) poetry init で pyproject.toml の雛形を作成できます
機械学習サンプルコード main.py
機械学習ソースコードを作成し、main.py という名で保存。モデル保存用フォルダ:modelも事前に作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
import numpy as np import joblib from palmerpenguins import load_penguins from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix from sklearn.experimental import enable_iterative_imputer from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import classification_report, accuracy_score def train(): # load dataset X, y = load_penguins(return_X_y=True, drop_na=True) # # check missing values # print(X.isnull().any()) # False # print(X.isnull().sum()) # 0 # split dataset (train:valid = 7:3) X_train, X_valid, y_train, y_valid = train_test_split( X, y, test_size=0.3, random_state=42) # learn model = DecisionTreeClassifier() model.fit(X_train, y_train) # predict y_pred = model.predict(X_valid) # print precision, recall, f1-score, support print(classification_report(y_valid, y_pred)) print("score:", accuracy_score(y_valid, y_pred)) # save model name = "decisiontree_model" joblib.dump(model, f"model/{name}.pkl") print(f"save model: {name}") def predict(): # model name + path name = "decisiontree_model" saved_filename = (f"model/{name}.pkl") # test data x_test = np.array([[39.2, 17.7, 181, 3740]]) # load model model = joblib.load(saved_filename) # predict y_pred = model.predict(x_test) print("predict:", y_pred) if __name__ == "__main__": train() predict() |
以上でプロジェクトフォルダ:docker-ml の中身を全て用意できました。
Dockerコンテナ内で機械学習
プロジェクトフォルダをVS Codeから開き、VS Code左下の「><」をクリック後、Reopen in Container を選択します。
From Dockerfile を選択すると、イメージのビルドが実行されます(初回のみ)。
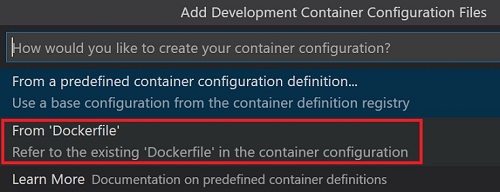
左下が「Dev Container: Existing Dockerfile」になったら接続成功です。
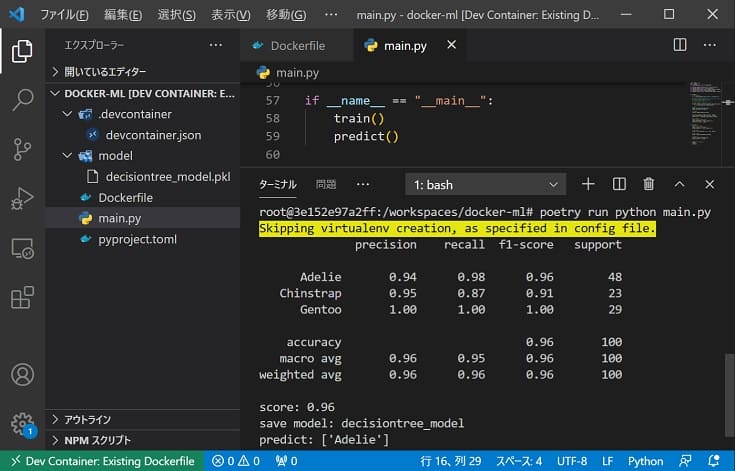
ターミナルに以下のコマンドを入力し、main.pyを実行します。
poetry run python main.py
スコアレポートなどが表示され、学習済みモデルがmodel/decisiontree_model.pklに保存できればOKです。
以上で「実践 Dockerチュートリアル -Pythonで機械学習アプリ開発-」終了です。
【おまけ】チュートリアル後の次ステップ -オリジナル機械学習アプリをつくろう-
main.py 実行後に表示される predict: [‘Adeli’] というのは、predict() による「学習済みモデルで未知のデータを推論した結果」です。

本チュートリアルの次ステップとして、main.py から predict() を切り離し、推論専用のオリジナル機械学習アプリ app.py を作成してみましょう。
例えば、本記事の predict() では未知のデータ[39.2, 17.7, 181, 3740]をコード内にべた書きしてますが、外部から受け取るようにし、推論結果を返すような機械学習アプリを作るのはいかがですか?
まとめ
WSL2 + Docker + VS Code の Remote – Containers のPython開発環境が最高だったので、構築方法と実践チュートリアルを紹介しました。
Docker入門や機械学習アプリ開発の勉強にもなると思うので、参考になれば嬉しいです。
【おまけ】に書いた「オリジナル機械学習アプリ開発」にも、ぜひ挑戦してみて下さい。


















