こんにちは。現役エンジニアの”はやぶさ”@Cpp_Learningです。全文検索エンジンや検索システムに興味があって勉強中です。
実践を兼ねた勉強として、検索アプリを作っています。
https://twitter.com/Cpp_Learning/status/1457284611998830598
作り方などの備忘録として本記事を書きます。
Contents
今回つくる検索アプリの概要
今回つくる検索アプリを含むアーキテクチャの概要は下図の通りです。Webアプリ経由でユーザーが入力した検索語のリクエストを送信し、各APIから検索結果をJSONで受信します。
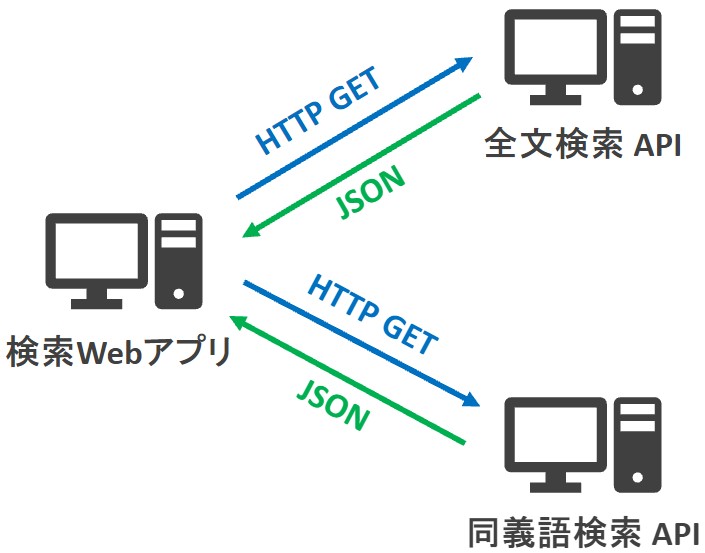
上図のWebアプリと全文検索APIについては、以下の記事で解説済みです。
なので、本記事のメインは以下になります。
- 同義語辞書をつくる(既存のものを活用してもOK)
- FastAPIで同義語検索APIをつくる
- Webアプリ(Streamlit製)から同義語検索APIにリクエストを投げて、入力したキーワード(検索語)の同義語をJSONで受信
Sudachiで同義語辞書をつくる -SudachiDict-
Sudachiとは、Works Applicationsが開発・公開している形態素解析器です。
同義語辞書も公開しているので、同義語辞書ソース フォーマットを参考に独自の辞書を作成できます。登録に必要な最低限の情報は、同義語として登録する共通の「0:グループ番号」と「8:見出し(語句)」です。例えば、以下の通りです。
023714,,,,,,,,画像処理,,
023714,,,,,,,,Image processing,,
023714,,,,,,,,コンピュータビジョン,,
023714,,,,,,,,computer vision,,
023714,,,,,,,,CV,,
ゼロから辞書をつくっても良いのですが、synonyms.txt に追加登録するのが簡単です。
2021/11/13時点で synonyms.txt に 23,713 の 同義語(グループ番号)が登録済なので、使わないのは勿体ない
辞書を活用した同義語検索をつくる
独自の辞書が完成したら、以下のフローで同義語検索を行います。
- 辞書から検索語と一致する語句を検索
- 検索語のグループ番号を取得
- 同一グループ番号の語句(=同義語)を検索
- 各レコードから同義語(見出し)のみ抽出
Pythonで実装したものが以下です(Pandas使うのが楽です)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
import pandas as pd def search_synonym(q: str = None): '''同義語検索''' # 辞書読込み columns = ['group_id', 'type', 'expansion', 'vocab_id', 'relation', 'abbreviation', 'spelling', 'field', 'heading', 'reserved1', 'reserved2'] df = pd.read_csv('./synonyms.txt', skip_blank_lines=True, names=columns) # 同義語検索 try: # 1. 辞書から検索語と一致する語句を検索 # 2. 検索語のグループ番号を取得 target_id = df[df['heading'] == q].group_id # 3. 同一グループ番号の語句(=同義語)を検索 target_df = df[df['group_id'] == int(target_id)] # 4. 各レコードから同義語(見出し)のみ抽出 result = target_df['heading'] except: # 検索失敗時の例外処理 result = '同義語辞書に未登録の単語です.' return result def main(): keyword = '画像処理' result = search_synonym(q=keyword) print(result) if __name__ == '__main__': main() |
61356 画像処理
61357 Image processing
61358 コンピュータビジョン
61359 computer vision
61360 CV
Name: heading, dtype: object
「画像処理」などのキーワードを入力すると「Image processing」などの同義語を検索して、出力します。このソースコードをAPI化します。
FastAPIで同義語検索APIをつくる
PythonでREST APIを作るなら、Webフレームワークの FastAPI がオススメです。
インストールから使い方まで公式サイトが丁寧に解説しているので、本記事では割愛して、直ぐにソースコードのmain.pyを公開します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
import pandas as pd import uvicorn from fastapi import FastAPI app = FastAPI() # http://127.0.0.1:8888/synonyms/?q={keyword} @app.get('/synonym/') def search_synonym(q: str = None): '''同義語検索''' # 辞書読込み columns = ['group_id', 'type', 'expansion', 'vocab_id', 'relation', 'abbreviation', 'spelling', 'field', 'heading', 'reserved1', 'reserved2'] df = pd.read_csv('./synonyms.txt', skip_blank_lines=True, names=columns) # 同義語検索 try: # 1. 辞書から検索語と一致する語句を検索 # 2. 検索語のグループ番号を検索 target_id = df[df['heading'] == q].group_id # 3. 同一グループ番号の語句(=同義語)を取得 target_df = df[df['group_id'] == int(target_id)] # 4. 各レコードから同義語(見出し)のみ抽出 synonym_df = target_df['heading'] # 5. dfをjsonに変換 response = synonym_df.to_json(force_ascii=False) except: # 検索失敗時の例外処理 response = {'message': '同義語辞書に未登録の単語です.'} return response if __name__ == '__main__': uvicorn.run('main:app', host='127.0.0.1', port=8888, reload=True) |
以下のコマンドでAPIサーバーを起動できます。
python main.py
ブラウザなどから http://127.0.0.1:8888/synonym/?q={keyword} というリクエストを投げると、{keyword}の同義語がJSONで返ってきます。例えば、画像処理というキーワードでリクエストを投げたときの様子が下図です。

または以下の記事を参考に VSCode からリクエストを投げて動作確認しても良いと思います。

OpenAPI準拠のAPIドキュメントを自動生成
FastAPI の素晴らしい機能の一つにAPIドキュメントの自動生成があります。先ほど立てたAPIサーバに http://127.0.0.1:8888/docs というリクエストを投げると、OpenAPIに準拠したAPIドキュメントが Swagger UI によって表示されます。
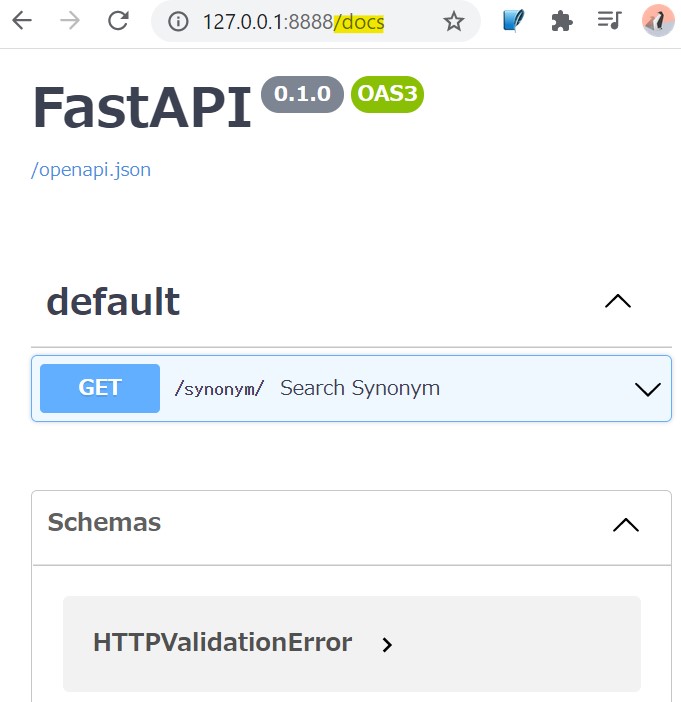
今回生成したAPIドキュメント(openapi.json)は以下の通りです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 |
{ "openapi": "3.0.2", "info": { "title": "FastAPI", "version": "0.1.0" }, "paths": { "/synonym/": { "get": { "summary": "Search Synonym", "description": "同義語検索", "operationId": "search_synonym_synonym__get", "parameters": [ { "required": false, "schema": { "title": "Q", "type": "string" }, "name": "q", "in": "query" } ], "responses": { "200": { "description": "Successful Response", "content": { "application/json": { "schema": {} } } }, "422": { "description": "Validation Error", "content": { "application/json": { "schema": { "$ref": "#/components/schemas/HTTPValidationError" } } } } } } } }, "components": { "schemas": { "HTTPValidationError": { "title": "HTTPValidationError", "type": "object", "properties": { "detail": { "title": "Detail", "type": "array", "items": { "$ref": "#/components/schemas/ValidationError" } } } }, "ValidationError": { "title": "ValidationError", "required": [ "loc", "msg", "type" ], "type": "object", "properties": { "loc": { "title": "Location", "type": "array", "items": { "type": "string" } }, "msg": { "title": "Message", "type": "string" }, "type": { "title": "Error Type", "type": "string" } } } } } } |
オフラインでOpenAPI準拠のAPIドキュメントを確認するときは、VSCode の拡張機能 Swagger Viewer を使うのがオススメです。
Streamlitで全文検索アプリをつくる
最後に前回作った全文検索アプリから今回作った同義語検索APIにリクエストを投げて、検索結果を受信することで「入力した検索キーワードの同義語を検索候補として表示する機能」をアプリに追加します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 |
import httpx import streamlit as st def view_response(res, res2): '''検索クエリ結果の表示''' # ステータスチェック if res["response"]["status"] != 0: st.error("検索中に問題が発生しました。管理者にご相談ください。") # 検索ヒット件数 record_count = res["response"]["record_count"] # 検索ワード q = res["response"]["q"] if record_count == 0: # 検索結果がない場合 st.error(f'{q}に一致する情報は見つかりませんでした。') # 検索語候補 with st.expander("その他の検索語候補"): st.json(res2) else: # 検索件数など page_number = res["response"]["page_number"] startRange = res["response"]["start_record_number"] endRange = res["response"]["end_record_number"] exec_time = res["response"]["exec_time"] # "q" の検索結果 232 件中 1 - 10 件目 (0.2 秒) st.write( f" **{q}** の検索結果 **{record_count}** 件中 **{startRange} - {endRange}** 件目 ({exec_time}秒)") # 検索語候補 with st.expander("その他の検索語候補"): st.json(res2) # 検索結果表示処理 results = res["response"]["result"] for i, result in enumerate(results): # 検索結果 title = result["title"] url_link = result["url_link"] digest = result["digest"] st.markdown(f"#### {i+1}. [{title}]({url_link})", unsafe_allow_html=True) st.markdown("") # 改行 st.markdown(digest) # nページ目 st.markdown(f"{page_number}ページ目") return page_number, endRange def query_ui(): '''検索クエリ用UI''' # 検索ワード入力 input_word = st.text_input(label='キーワード入力', value='') st.write(f'検索ワード: {input_word}') # 検索件数 page_size = st.sidebar.number_input(label='件数', value=10, step=10) st.sidebar.write(f'件数: {page_size}') # 開始する件数位置 start_record_number = st.sidebar.number_input( label='開始する件数位置', value=0, step=10) st.sidebar.write(f'開始する件数位置: {start_record_number}') return input_word, page_size, start_record_number def main(): '''全文検索アプリ''' # アプリ名 st.markdown('## 全文検索アプリ') # 検索クエリ input_word, page_size, start_record_number = query_ui() # 検索 if st.button("検索"): # GETリクエスト response = httpx.get( f'http://localhost:8080/json/?q={input_word}&num={page_size}&start={start_record_number}') response2 = httpx.get( f'http://localhost:8888/synonym/?q={input_word}') # 全文検索結果をJSONで受け取る res = response.json() # 同義語検索をJSONで受け取る res2 = response2.json() # 検索結果の表示処理 view_response(res, res2) # 検索結果詳細 with st.expander("検索結果詳細 for debug"): st.json(res) if __name__ == '__main__': main() |
自作アプリで全文検索および同義語検索をしている様子が以下です。
https://twitter.com/Cpp_Learning/status/1457284611998830598
※冒頭と同じ動画です。
まとめ -StreamlitとFastAPIで検索アプリをつくる-
Pythonライブラリの Streamlit と FastAPI を活用し、Pythonで全文検索アプリ(同義語検索による検索語候補の表示機能付き)を作りました。
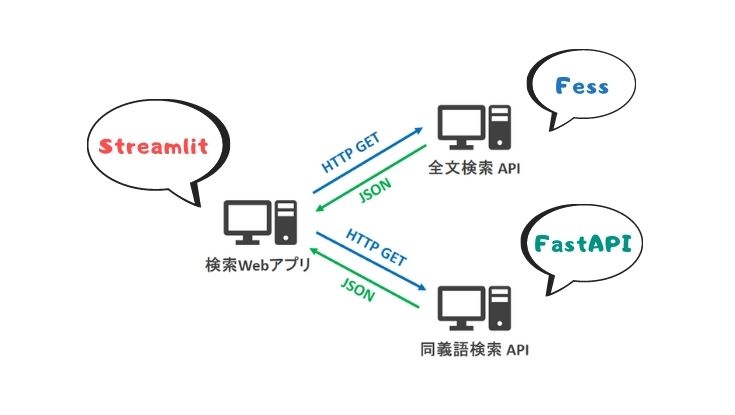
Webアプリ(Streamlit製)のソースコードを改良して、同義語検索を実現しても良かったのですが、同義語検索そのものは汎用的な処理なので、色んなアプリと連携しやすいようにAPIという形で提供する方が良いと考えました。

アプリ作りはやっぱり楽しいですね♪
検索技術や自然言語処理の勉強を始めたばかりですが、今後も勉強した内容を本ブログで公開したいと考えていますので、今後もブログ「はやぶさの技術ノート」をよろしくお願いします。
















