こんにちは。現役エンジニアの”はやぶさ”@Cpp_Learningです。Python使ってデータ分析などをしています。
本記事ではPythonライブラリの SQLAlchemy と Pandas を使って、データベースから任意データを取得し、データフレームに変換する方法を紹介します。
Contents
モチベーション
Pythonでデータ分析をするとき、以下のフローで処理する人が多いと思います。
- クラウドストレージやデータベースなどからデータ取得
- データの前処理
- データ可視化
データベースからデータ取得する際のSQLクエリを頑張れば、前処理は不要かもしれませが、大雑把にデータ取得して、Pythonで細かい前処理をする方が楽なときもあります。
上記の❶と❷をシームレスに実現する方法をいくつか検討し、ベストだと感じたのがSQLAlchemyとPandasの組み合わせだったので、本記事でやり方を解説します。
SQLAlchemyとは
SQLAlchemyとは、Python専用のSQLツールキットであり、かつORMでもあります。公式サイトでは以下のように紹介しています。
The Python SQL Toolkit and Object Relational Mapper
SQLAlchemy is the Python SQL toolkit and Object Relational Mapper that gives application developers the full power and flexibility of SQL.
引用元:SQLAlchemy|公式サイト
ORMについては、以下の記事で説明しています。

実践 SQLAlchemyとPandasでデータベース操作
SQLAlchemyとPandasを使って、データベースから任意データを取得する方法は何通りもありますが、基本的なフローは以下の通りです。
- SQLAlchemyでエンジン作成
- SQLAlchemyでクエリ組み立て(※)
- pandas.read_sqlでクエリ結果をデータフレームに格納
(※)上記❷でクラスの使用・未使用、filterの使用・未使用など様々
何パターンか実践してみます。なお本記事で使うバージョンは以下の通りです。
- SQLAlchemy==1.4.23
- pandas==1.3.3
以降からソースコード書いていきます。
SQLAlchemyのみを使用するパターン
まずはPandasを使わず、SQLAlchemyのみを使ってデータベースから任意データを取得します。
❶エンジン生成
最初にデータベースと接続するためのエンジンを生成します。SQLiteの場合は以下の通りです。
|
1 2 3 4 5 6 7 |
from sqlalchemy import create_engine # db file_path = '/db/user.db' # Create engine for SQLite engine = create_engine(f'sqlite://{file_path}', echo=True) |
user.dbにはユーザー情報を登録した以下のテーブルが存在します。
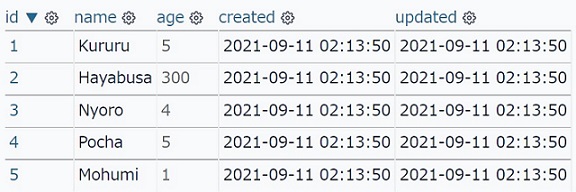
本記事で扱うデータベースは SQLite ですが、SQLAlchemyを使うことでデータベースの違いを吸収できます。
❷SQLAlchemyのsession機能を使用してSELECT
SQLAlchemyのみでデータベースから任意データを取得するコードが以下です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
from sqlalchemy import create_engine, Column, table, Integer, String, DATETIME from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import sessionmaker # from sqlalchemy.sql import select # import pandas as pd Base = declarative_base() class User(Base): ''' Column definition ''' __tablename__ = 'user' # テーブル名 id = Column('id', Integer, primary_key=True) # 主キー name = Column('name', String(200)) age = Column('age', Integer) created = Column('created', DATETIME) updated = Column('updated', DATETIME) def main(): # db file_path = '/db/user.db' # Create engine for SQLite engine = create_engine(f'sqlite://{file_path}', echo=True) # Create session SessionClass = sessionmaker(engine) session = SessionClass() # Target user_name = "Kururu" user_age = 5 # SELECT users = session.query( User.id, User.name, User.age ).filter( (User.name == user_name) & (User.age >= user_age) ).limit(10) for user in users: print(f"id:{user.id}, name:{user.name}, age:{user.age}") # DBと切断 session.close() # エンジン破棄 engine.dispose() if __name__ == "__main__": main() |
id:1, name:Kururu, age:5
生SQLを使わずにクエリを組み立て、Python側で定義したUserクラスに従ってクエリ結果をマッピングすることで型安全を保障しています。
つまりusersに格納されたクエリ結果の id:1, name:Kururu, age:5 の内、nameはstr型、ageはint型で扱うことができます。
最後の session.close() や engine.dispose() の書き忘れに要注意
➌クエリ結果をPandasデータフレームに格納
以下のコードで先ほど組み立てたクエリのSQL文を取得できます。またpandas.read_sql_queryを使うと簡単にデータベースへの接続とクエリ結果のデータフレーム格納を実現できます。
|
1 2 3 4 5 6 7 8 9 10 11 |
import pandas as pd # SELECT users = session.query(...略...).limit(10) # Get row SQL sql_statement = users.statement print(sql_statement) df = pd.read_sql_query(sql=sql_statement, con=engine) print(df) |
ただし、このやり方だと users と df の両方にクエリ結果が格納されます。df のみに格納したい場合は、以降から紹介する session を使わないコードの方がスマートです。
SQLAlchemyとPandasとクラスを使ってクエリ結果を取得するパターン
先ほど紹介したコードをベースに session未使用にしたものが以下です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
from sqlalchemy import create_engine, Column, table, Integer, String, DATETIME from sqlalchemy.ext.declarative import declarative_base # from sqlalchemy.orm import sessionmaker from sqlalchemy.sql import select import pandas as pd Base = declarative_base() class User(Base): ''' Column definition ''' __tablename__ = 'user' # テーブル名 id = Column('id', Integer, primary_key=True) # 主キー name = Column('name', String(200)) age = Column('age', Integer) created = Column('created', DATETIME) updated = Column('updated', DATETIME) def main(): # db file_path = '/db/user.db' # Create engine for SQLite engine = create_engine(f'sqlite://{file_path}', echo=True) # # Create session # SessionClass = sessionmaker(engine) # session = SessionClass() # Target user_name = "Kururu" user_age = 5 # SELECT sql_statement = ( select([ User.id, User.name, User.age ]).filter( (User.name == user_name) & (User.age >= user_age) ).limit(10) ) # Get row SQL print("============== row SQL =================") print(sql_statement) print("========================================") df = pd.read_sql_query(sql=sql_statement, con=engine) print("=========== query result ===============") print(df) print("========================================") # # DBと切断 # session.close() # エンジン破棄 engine.dispose() if __name__ == "__main__": main() |
============== row SQL =================
SELECT “user”.id, “user”.name, “user”.age
FROM “user”
WHERE “user”.name = :name_1 AND “user”.age >= :age_1
LIMIT :param_1
========================================
=========== query result ===============
id name age
0 1 Kururu 5
========================================
SQLAlchemyのORM機能…というよりクエリビルド機能をフル活用して、クエリを組み立て、Pandasでクエリ結果の取得とデータフレームへの格納を行っています。
以上がSQLAlchemyとPandasとクラスを使うパターンです。
session が無いので、engine.dispose() のみでOK
クラスを使わないパターン
クラスを使わずにクエリ結果をデータフレームに格納するパターンは以下の通りです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
from sqlalchemy import create_engine, Column, table, Integer, String, DATETIME from sqlalchemy.sql import select import pandas as pd def main(): # db file_path = '/db/user.db' # Create engine for SQLite engine = create_engine(f'sqlite://{file_path}', echo=True) # Target user_name = "Kururu" user_age = 5 # SELECT sql_statement = ( select([ Column('id', Integer), Column('name', String), Column('age', Integer), ]).select_from(table('user')).where( Column('name', String) == user_name, Column('age', Integer) >= user_age ).limit(10) ) print("============== row SQL =================") print(sql_statement) print("========================================") # query result to df df = pd.read_sql_query(sql=sql_statement, con=engine) print("=========== query result ===============") print(df) print("========================================") # エンジン破棄 engine.dispose() if __name__ == "__main__": main() |
============== row SQL =================
SELECT id, name, age
FROM “user”
WHERE name IN ([POSTCOMPILE_name_1]) AND age >= :age_1
LIMIT :param_1
========================================
=========== query result ===============
id name age
0 1 Kururu 5
========================================
クラス使いたくないし、生SQLも書きたくない人にオススメのコードです。
クエリを組み立てるとき、filterのかわりに select_from(テーブル).where(条件)という書き方もできます
SQLAlchemyとPandasによるデータベース操作(SELECT)の雛形コード
クラスを使う・使わない(filterを使う・使わない)を選択できる雛形コード作成したので、紹介します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 |
from sqlalchemy import create_engine, Column, table, Integer, String, DATETIME from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.sql import select import pandas as pd Base = declarative_base() class User(Base): ''' Column definition ''' __tablename__ = 'user' # テーブル名 id = Column('id', Integer, primary_key=True) # 主キー name = Column('name', String(200)) age = Column('age', Integer) created = Column('created', DATETIME) updated = Column('updated', DATETIME) def my_query(user_name = "Kururu", user_age = 5): ''' Only SELECT ''' # # Target # user_name = "Kururu" # user_age = 5 # SELECT sql_statement = ( select([ Column('id', Integer), Column('name', String), Column('age', Integer), ]).select_from(table('user')).where( Column('name', String) == user_name, Column('age', Integer) >= user_age ).limit(10) ) print("============== row SQL =================") print(sql_statement) print("========================================") return sql_statement def my_query_used_class(user_name = "Kururu", user_age = 5): ''' Only SELECT used Class and filter ''' # # Target # user_name = "Kururu" # user_age = 5 # SELECT sql_statement = ( select([ User.id, User.name, User.age ]).filter( (User.name == user_name) & (User.age >= user_age) ).limit(10) ) print("============== row SQL =================") print(sql_statement) print("========================================") return sql_statement def main(): # db file_path = '/db/user.db' # Create engine for SQLite engine = create_engine(f'sqlite://{file_path}', echo=True) # my query m_sql_1 = my_query() m_sql_2 = my_query_used_class() # query result to df df_1 = pd.read_sql_query(sql=m_sql_1, con=engine) df_2 = pd.read_sql_query(sql=m_sql_2, con=engine) print("=========== query result 1 ===============") print(df_1) print("==========================================") print("=========== query result 2 ===============") print(df_2) print("==========================================") # エンジン破棄 engine.dispose() if __name__ == "__main__": main() |
アプリに合わせて雛形コードを改良して使うのが便利です。
【応用】柔軟なクエリの組み立て
最後に雛形コードを改良して、柔軟なクエリ組み立てを実現した例を紹介します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
from sqlalchemy import create_engine, Column, table, Integer, String, DATETIME from sqlalchemy.sql import select import pandas as pd def my_query(names=['Kururu', 'Mohumi'], user_age=5, conditions=0): ''' Only SELECT conditions=0 is "==" conditions=1 is "<=" conditions=2 is ">=" ''' select1 = Column('name', String).in_(names) select2 = [ (Column('age', Integer) == user_age), (Column('age', Integer) <= user_age), (Column('age', Integer) >= user_age) ] # SELECT sql_statement = ( select([ Column('id', Integer), Column('name', String), Column('age', Integer), ]).select_from(table('user')).where( select1, select2[conditions] ).limit(10) ) print("============== row SQL =================") print(sql_statement) print("========================================") return sql_statement def main(): # db file_path = '/db/user.db' # Create engine for SQLite engine = create_engine(f'sqlite://{file_path}', echo=True) # my query m_sql = my_query(names=['Hayabusa', 'Kururu'], user_age=5, conditions=2) # query result to df df = pd.read_sql_query(sql=m_sql, con=engine) print("=========== query result ===============") print(df) print("========================================") # エンジン破棄 engine.dispose() if __name__ == "__main__": main() |
============== row SQL =================
SELECT id, name, age
FROM “user”
WHERE name IN ([POSTCOMPILE_name_1]) AND age >= :age_1
LIMIT :param_1
========================================
=========== query result ===============
id name age
0 1 Kururu 5
1 2 Hayabusa 300
========================================
このようなに柔軟なクエリも組めるので、目的に応じて雛形コードを改良してみてください。
まとめ
SQLAlchemy と Pandas を使って、データベースから任意データを取得し、データフレームに変換する方法を紹介しました。
雛形コードも作成・公開したので、自由に改良して使ってください。本記事を参考にアプリを作った人が出てきたら最高に嬉しいです。