こんにちは。
現役エンジニアの”はやぶさ”@Cpp_Learningです。仕事でもプライベートでも機械学習で色々やってます。
今回はsklearnを活用した特徴量選定について勉強したので、備忘録も兼ねて本記事を書きます。
sklearn の version 0.24.1 で動作確認しました
Contents
モチベーション -なせ特徴量の選定や重要度把握をするのか-
下記の記事に書いた通り、モデルが何を根拠に推論したか?どの特徴量が重要だったのか?などを明示したいタスクがあります。

あるいは nつの特徴量から、3つの特徴量を選定して、精度の良いモデルを生成できるなら、『残りのn-3つの特徴量は今後収集しなくて済みそう』という意思決定のサポートに繋がります。
実践!sklearn.feature_selectionによる特徴量選定・特徴量重要度の把握
機械学習チュートリアルでお馴染みのワインのデータセットを採用し、sklearn.feature_selectionによる特徴量選定を行います。
インストール
本記事のソースコードはGoogle Colabで動作確認しました(2021/02/20)。
Google Colabの場合は、以下のコマンドでsklearnをアップグレードすれば環境構築完了です。
pip install –upgrade scikit-learn
以下のコードでバージョン確認できます。
|
1 2 3 |
import sklearn print(sklearn.__version__) |
以降から特徴量選定を実践していきます。
Import
まずはimportから
|
1 2 3 4 5 6 7 8 9 10 |
import matplotlib.pyplot as plt # from sklearn.neighbors import KNeighborsClassifier from sklearn.ensemble import RandomForestClassifier # from sklearn.ensemble import ExtraTreesClassifier from sklearn.feature_selection import SequentialFeatureSelector from sklearn.feature_selection import SelectFromModel from sklearn.datasets import load_wine |
データセットとタスク
以下のコードでデータセットのダウンロードから中身(頭3行)の確認まで行います。
|
1 2 |
X, y = load_wine(return_X_y=True, as_frame=True) X.head(3) |
中身の説明は割愛しますが、アルコール度数・色・成分に関する13つの特徴量が存在します。
この特徴量を使ってワインのクラス(1~3)を分類するのですが、今回は分類する上で重要な3つの特徴量を選定したいと思います。
モデル設計 -機械学習アルゴリズム選定-
どの機械学習アルゴリズムでも良いのですが、今回はランダムフォレストを採用します。
|
1 2 3 4 5 6 7 8 9 |
# KNN # model = KNeighborsClassifier(n_neighbors=3) # ExtraTree # model = ExtraTreesClassifier(n_estimators=10) # RandomForest model = RandomForestClassifier(n_estimators=10) # model.fit(X, y) |
Sequential Feature Selection(SFS)による特徴量選定
まずは Sequential Feature Selector(SFS) を使ってみます。
Forward-SFS is a greedy procedure that iteratively finds the best new feature to add to the set of selected features. Concretely, we initially start with zero feature and find the one feature that maximizes a cross-validated score when an estimator is trained on this single feature. Once that first feature is selected, we repeat the procedure by adding a new feature to the set of selected features. The procedure stops when the desired number of selected features is reached, as determined by the
n_features_to_selectparameter.Backward-SFS follows the same idea but works in the opposite direction: instead of starting with no feature and greedily adding features, we start with all the features and greedily remove features from the set. The
directionparameter controls whether forward or backward SFS is used.In general, forward and backward selection do not yield equivalent results. Also, one may be much faster than the other depending on the requested number of selected features: if we have 10 features and ask for 7 selected features, forward selection would need to perform 7 iterations while backward selection would only need to perform 3.
公式サイトの説明によると、Forward-SFS では特徴量を1つずつ追加して、学習・評価を繰り返しながら、特徴量選定を行うアルゴリズムのようです。
一方 Backward-SFS は全ての特徴量から1つずつ削除していくようです。
また Forward-SFS と Backward-SFS の結果は必ずしも一致しないし、選定する特徴量の数によって、どっちの処理速度が速いか変わるようです。

Forward-SFS
以下のコードで3つの特徴量を選定できます。
|
1 2 3 4 5 6 |
n_features = 3 sfs = SequentialFeatureSelector(model, n_features_to_select=n_features, direction='forward') sfs.fit(X, y) print("Top {} features selected by forward sequential selection (direction='forward')".format(n_features)) print(X.columns[sfs.get_support()]) |
Top 3 features selected by forward sequential selection (direction=’forward’)
Index([‘magnesium’, ‘flavanoids’, ‘color_intensity’], dtype=’object’)
‘magnesium’, ‘flavanoids’, ‘color_intensity’ が選択されました。
Backward-SFS
direction=’backward’にするだけで、Backward-SFSも試せます。
|
1 2 3 4 5 6 |
n_features = 3 sfs = SequentialFeatureSelector(model, n_features_to_select=n_features, direction='backward') sfs.fit(X, y) print("Top {} features selected by forward sequential selection (direction='backward')".format(n_features)) print(X.columns[sfs.get_support()]) |
Top 3 features selected by forward sequential selection (direction=’backward’)
Index([‘magnesium’, ‘color_intensity’, ‘od280/od315_of_diluted_wines’], dtype=’object’)
‘magnesium’, ‘color_intensity’, ‘od280/od315_of_diluted_wines’ が選択されました。
確かに Forward-SFS と Backward-SFS の結果が異なりますね。ただ、どちらのアルゴリズムでも ‘magnesium’ と ‘color_intensity’ が選択された点は、ユーザが特徴量選定する上でのヒントになりそうです。
SelectFromModel(SFM)による特徴量選定 -Selecting features based on importance-
続いて SelectFromModel(SFS)を使ってみます。
SelectFromModelis a meta-transformer that can be used along with any estimator that importance of each feature through a specific attribute (such ascoef_,feature_importances_) or callable after fitting. The features are considered unimportant and removed, if the corresponding importance of the feature values are below the providedthresholdparameter. Apart from specifying the threshold numerically, there are built-in heuristics for finding a threshold using a string argument. Available heuristics are “mean”, “median” and float multiples of these like “0.1*mean”. In combination with thethresholdcriteria, one can use themax_featuresparameter to set a limit on the number of features to select.引用元:sklearn公式サイト
公式サイトの説明によると、 coef, feature_importances のうち閾値以下だったものを削除して、特徴量を選択するアルゴリズムのようです。
SFM
以下のコードで閾値0.15以上の特徴量を選定できます。
|
1 2 3 4 5 6 |
threshold = 0.15 sfm = SelectFromModel(model, threshold=threshold) sfm.fit(X, y) print("Feature selection using SelectFromModel (threshold={})".format(threshold)) print(X.columns[sfm.get_support()]) |
Feature selection using SelectFromModel (threshold=0.15)
Index([‘flavanoids’, ‘color_intensity’, ‘proline’], dtype=’object’)
‘flavanoids’, ‘color_intensity’, ‘proline’ が閾値を上回る特徴量だったようです。
SFM自作
SFMのアルゴリズムなら簡単なので、自作できますね。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 閾値 threshold = 0.15 # 学習 model = RandomForestClassifier(n_estimators=10) model.fit(X, y) # 特徴量重要度 importances = model.feature_importances_ print(importances) # 可視化 plt.figure(figsize=(14,4)) plt.bar(height=importances, x=X.columns) plt.hlines(y=threshold, xmin=-1, xmax=len(X.columns), colors="red", linestyle="--", lw=2) plt.ylabel("Feature importances", color='tab:red', fontsize=16, labelpad=20, weight='bold') plt.xticks(rotation=90); |
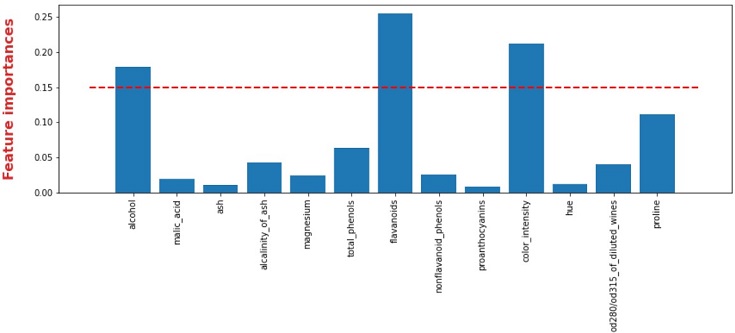 sklearnのツリー系アルゴリズムなら、 model.feature_importances_ で特徴量重要度を確認できるので、可視化して閾値以上の特徴量を確認・選択すれば良いですね。
sklearnのツリー系アルゴリズムなら、 model.feature_importances_ で特徴量重要度を確認できるので、可視化して閾値以上の特徴量を確認・選択すれば良いですね。
まとめ
sklearn.feature_selectionによる特徴量選定を実践しました。
採用するアルゴリズムによって、結果が異なることを確認できました。そのため、最終的にはユーザーの判断で特徴量選定することになりますが、判断材料にはなると思います。
便利なライブラリは積極的に活用すれば良いと思いますが、最終的には自分で意思決定する必要があるので、正しい知識と技術を習得して、価値を提供できるようになりたいですね。