こんにちは。
コンピュータビジョン(『ロボットの眼』開発)が専門の”はやぶさ”@Cpp_Learningです。最近は Pytorch を使って深層学習を楽しんでいます。
Pytorchなどの深層学習フレームワークを使うと比較的簡単にCNN設計ができますよね。
ところでCNNが何の略か知ってますか? Kernel(カーネル)の役割りは?画像処理の基礎は習得できてますか?

と思っているフクロウ@kururu_owl や人がいるかもしれません。

という想いで本記事『Pytorchで画像処理 -Kernelを自作してCNNに組み込む-』を書きました。
微力ではありますがコンピュータビジョンが専門の”はやぶさ”が皆様の勉強をサポートさせて頂きます。本記事をきっかけに画像処理をもっと学びたい!という人が増えると嬉しいです。
Contents
対象読者
本記事は OpenCV でも scikit-image でもなくPytorchで画像処理をしたい人 が対象です。
より具体的にいえば PytorchでKernel(Sobelフィルタなど)を自作したい人が対象です。
そのため以下の注意点があります。
- Pytorch の基本的な使い方の説明は割愛します※
- Kernel自作という少しマニアック(?)な内容がメインです
- CNNが出てくるのは記事の後半(実践編)なので、前半(入門編)を飛ばして読んでもOKです
※ MNISTのソースコード を理解していれば問題ないかと
以上の注意点を読んで知的好奇心をくすぐられた人は、ぜひ続きを読んでみてください。
画像処理の基礎
画像処理の基礎については以下の記事で丁寧に説明しています。

この記事を読んでから以降の『超入門!Pytorchによる画像処理』を読むと”スッと”理解できると思います。
本記事を最後まで読めば、PytorchでKernelを自作できるようになります
超入門!Pytorchによる画像処理 -オリジナルカーネル作成-
さっそくですが『Pytorchによる画像処理』をしていきます。使用するライブラリ一覧は以下の通りです。
- torch 1.4.0
- torchvision 0.5.0
- Pillow 6.2.2
- matplotlib 3.1.3
- numpy 1.17.5
※Google Colaboratoryで動作確認しました(2020/02/22)
Import
最初はimportから
|
1 2 3 4 5 6 7 8 9 |
import torch import torch.nn as nn import torch.nn.functional as F from torchvision import models, transforms from torch.utils.data import DataLoader import numpy as np from PIL import Image import matplotlib.pyplot as plt |
画像取得
まずは Pillow を使って画像を取得します。また説明の都合上、何らかの処理をする度に matplotlib で画像を描画していきます。
|
1 2 3 4 |
image = Image.open('/content/owl.jpg') plt.imshow(image) # 描画 |
 ‘/content/owl.jpg’というpathは適当に変更して下さい。
‘/content/owl.jpg’というpathは適当に変更して下さい。
Pillowでグレースケール化
Pillowを使って3chのカラー画像を1chのグレースケール画像に変換します。
|
1 2 3 4 |
gray_img = image.convert('L') plt.imshow(gray_img) # 描画 |

こんな感じでPillowなどの画像処理ライブラリを使えば、比較的簡単に画像処理ができます。ただし今回は、Pytorchで画像処理をします。
Pytorchでtransforms(グレースケール化とtensor変換)
PillowとPytorch(tensor)では扱う画像の配列が異なります。
- Pillow:[h, w, c]
- Pytorch(tensor):[c, h, w]
※c:チャンネル, h:画像の高さ, w:画像の幅,
なので順番を入れ替える処理が必要です。
例えば、以下のように numpy.transpose を使えば、軸の入れ替えができます。
|
1 2 3 4 5 |
# [h,w,c] ⇒ [c,h,w] image = np.asarray(image, np.float32) / 255 img = image.transpose(2, 0, 1).astype(np.float32) img = torch.from_numpy(img) print(img.size()) # [c,h,w] |
ただし今回は transforms を採用し、グレースケール ⇒ 軸変換(以下 この一連の処理を前処理と呼ぶ)を実現する my_transforms を作成します。
|
1 2 3 4 |
my_transform = transforms.Compose([ transforms.Grayscale(num_output_channels=1), transforms.ToTensor(), ]) |
my_transforms により、以下のスッキリしたコードで入力画像:imageの前処理を実現できます。
|
1 2 3 4 |
img = my_transform(image) print(img.size()) # [c,h,w] |
※ 前処理後の出力画像:img
transformsの活用で、前処理をスマートに実現できます
描画関数
画像(tensor)を描画する関数を作成します。
|
1 2 3 4 5 6 7 |
def imshow(tensor): image = tensor.clone().detach() # copy image = image.squeeze(0) # remove the fake batch dimension unloader = transforms.ToPILImage() # reconvert into PIL image image = unloader(image) plt.imshow(image) plt.pause(0.001) # pause a bit so that plots are updated |
以下のように描画したい画像(tensor)を引数に渡すだけで使えます。
|
1 2 3 |
imshow(img) |
Pillowによるグレースケール化と同じ結果が得られます。
ミニバッチ化
あとでCNNに組み込むことを意識して、tensorをミニバッチ化しておきます。
つまり [c,h,w] ⇒ [mb,c,h,w] にします。
|
1 2 3 4 |
x = img.unsqueeze_(0) print(x.size()) # [mb,c,h,w] |
※ mb:ミニバッチ(mb = 1)
以上までが『Pytorchによる画像処理』の前準備になります。次からカーネルを自作していきます。
Pytorchで平滑化
取得した画像にノイズが乗っていると、後処理に悪影響を及ぼすことがあります。なので、最初に平滑化を行います。
平滑化にもいくつか種類がありますが、今回はシンプルに以下のカーネルを作成します。
- カーネルサイズ:3×3
- 要素:全て1 / 9
以下のコードで平滑化を実現できます。
|
1 2 3 4 5 6 7 8 9 10 |
# Blur k = 9 kernel = torch.FloatTensor([[1/k, 1/k, 1/k], [1/k, 1/k, 1/k], [1/k, 1/k, 1/k]]) blur_filter = kernel.expand(1, 1, 3, 3) # [h,w] ⇒ [mb,c,h,w] blur_img = F.conv2d(x, blur_filter) imshow(blur_img) # 描画 |

カーネルサイズ:3×3を画像に合わせて拡張(expand)し、畳み込み演算(conv2d)すれば平滑化(自作カーネル処理)ができます。
自作カーネルの作成から畳み込み演算までの手順
-
torch.FloatTensorで任意のカーネルを作成
- expandを使って作成したカーネルを画像に合わせて拡張
- conv2dで畳み込み演算
PytorchでSobel(垂直方向)
今度は『【深層学習入門】画像処理の基礎(画素操作)からCNN設計まで』で紹介したSobelフィルタを作成します。
|
1 2 3 4 5 6 7 8 9 |
# Sobel kernel = torch.FloatTensor([[1, 0, -1], [2, 0, -2], [1, 0, -1]]) sobel_filter = kernel.expand(1, 1, 3, 3) sobel_img = F.conv2d(x, sobel_filter) imshow(sobel_img) # 描画 |

カーネルサイズと要素(CNNでいう重み)が決まれば、あとは平滑化フィルタと同じ要領で作成できます。
PytorchでSobel(水平方向)
Sobelフィルタでは検出するエッジの方向によって、カーネルの中身が異なります。
先ほど作成したカーネルは垂直方向のエッジを検出するものでした。今度は水平方向のエッジを検出するカーネルを作成します。
|
1 2 3 4 5 6 7 8 9 |
# Sobel2 kernel2 = torch.FloatTensor([[1, 2, 1], [0, 0, 0], [-1, -2, -1]]) sobel_filter2 = kernel2.expand(1, 1, 3, 3) sobel_img2 = F.conv2d(x, sobel_filter2) imshow(sobel_img2) # 描画 |

カーネルの自作って意外と簡単!と感じてくれたら嬉しいです。
基礎を習得すれば、応用が利きます
Pytorchでアンシャープマスク(鮮鋭化)
最後に鮮鋭化もやってみます(これも『【深層学習入門】画像処理の基礎(画素操作)からCNN設計まで』で紹介してますね)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
k = 0.3 # Shape Strength kernel = torch.FloatTensor([[0, -k, 0], [-k, 1+4*k, -k], [0, -k, 0]]) kernel2 = torch.FloatTensor([[-k, -k, -k], [-k, 1+(8*k), -k], [-k, -k, -k]]) shape_filter = kernel.expand(1, 1, 3, 3) shape_filter2 = kernel2.expand(1, 1, 3, 3) shape_img = F.conv2d(x, shape_filter) shape_img2 = F.conv2d(x, shape_filter2) imshow(shape_img) # 描画 # imshow(shape_img2) # 描画 |

カーネル2つ作成してるけど、あえて描画は1つだけでしておきます。もう一方の描画を見たい人は、手を動かして確認してみて下さい(*・ω・)ノ♪
記事を読むだけでなく、手を動かすことで知識が定着しやすくなります(自論)
まとめ -Pytorchによる画像処理【超入門】-
ここまでの内容が『Pytorchによる画像処理』の入門編になります。
- transformsを活用した前処理
- PytorchでSobelフィルタなどのカーネルを自作する方法
以下の記事では、OpenCV でカーネルを自作しましたが、今回はPytorchを使いました。
上の記事を読んでくれた人なら、ちゃんと画像処理とCNN(深層学習)をリンクできてるよね?
画像処理とCNNどちらもカーネル設計が重要だし、CNN設計が得意な深層学習フレームワークのPytorchを使えば、オリジナルのカーネル(Sobelフィルタなど)を自作することができます。
私のプロフィールにも書いていますが、修得した知識やスキルは必ずどこかで活かせます。画像処理と深層学習(CNN)を別々に学んだ人は、本記事を読んで、リンクできると良いですね。
(入門編 完)
━━━━━━━━━━━━━━━━
ここまで読んで、まだ元気な人は続き『Pytorchによる画像処理』の実践編も読んでみて下さい。
超実践!Pytorchによる画像処理 -自作カーネルをCNNに組み込む-
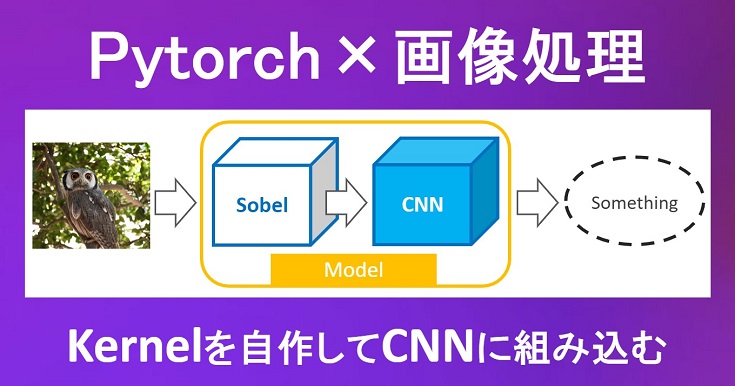
『Pytorchによる画像処理』の実践編で説明する内容のイメージは以下の通りです。
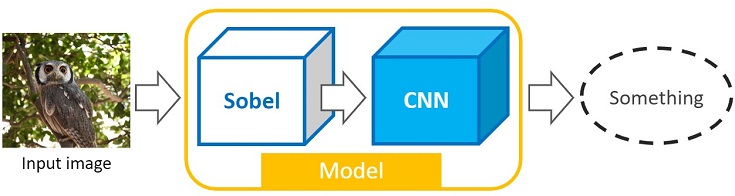
上図のようにCNNにSobelフィルタなどの自作カーネルを組み込んだmodel(ネットワーク)を作成していきます。
「Sobelフィルタlayerを作成してCNNに組み込む」という表現の方が適切かもしれません
【前知識】CNNの重みとバイアスを確認-
PytorchのCNN(conv)の「重み」と「バイアス」は以下のコードで確認できます。
|
1 2 3 4 5 6 |
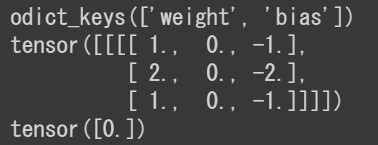
conv1 = nn.Conv2d(in_channels=1, out_channels=2, kernel_size=3, stride=1, padding=1) print(conv1.state_dict().keys()) print(conv1.state_dict()['weight']) print(conv1.state_dict()['bias']) |

要するに ”conv”が辞書型でkeyが ”weight”と”bias” ということです(3×3サイズのweight(重み)とbias(バイアス)が2つあるのは、out_channels=2だからです)。
nn.Conv2dは辞書型で key は ”weight” と “bias”
PytorchでSobelレイヤー作成
定義したconv(下記の例ではsobel_kernel)の重みとバイアスを任意の値に上書きすれば自作カーネル(自作layer)を作成できます。
例えば、Sobelの場合は以下の通りです。
|
1 2 3 4 5 6 7 8 9 10 |
# Sobel sobel_kernel = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, stride=1, padding=1) sobel_kernel.state_dict()['weight'][0] = torch.FloatTensor([[1, 0, -1], [2, 0, -2], [1, 0, -1]]) sobel_kernel.state_dict()['bias'].zero_() print(sobel_kernel.state_dict().keys()) print(sobel_kernel.state_dict()['weight']) print(sobel_kernel.state_dict()['bias']) |
この例ではSobelですが、入門編で説明した全カーネルが同じ要領で自作できます。
nn.Conv2dの”weight”と”bias”を任意の値に上書きすれば、独自カーネル(独自layer)を自作できます
PytorchでMyFilter(nn.Module)クラス設計
入門編で作成した全カーネルを順番に実行するMyFilter(nn.Module)が以下です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
class MyFilter(nn.Module): def __init__(self): super().__init__() # Blur_filter k = 9 self.blur_kernel = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, stride=1, padding=1) self.blur_kernel.state_dict()['weight'][0] = torch.FloatTensor([[1/k, 1/k, 1/k], [1/k, 1/k, 1/k], [1/k, 1/k, 1/k]]) self.blur_kernel.state_dict()['bias'].zero_() # Sobel_filter self.sobel_kernel = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, stride=1, padding=1) self.sobel_kernel.state_dict()['weight'][0] = torch.FloatTensor([[1, 0, -1], [2, 0, -2], [1, 0, -1]]) self.sobel_kernel.state_dict()['bias'].zero_() # Sobel_filter2 self.sobel_kernel2 = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, stride=1, padding=1) self.sobel_kernel2.state_dict()['weight'][0] = torch.FloatTensor([[1, 2, 1], [0, 0, 0], [-1, -2, -1]]) self.sobel_kernel2.state_dict()['bias'].zero_() # Shape k = 0.3 self.shape_kernel = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, stride=1, padding=1) self.shape_kernel.state_dict()['weight'][0] = torch.FloatTensor([[-k, -k, -k], [-k, 1+(8*k), -k], [-k, -k, -k]]) self.shape_kernel.state_dict()['bias'].zero_() def forward(self, x): x = self.blur_kernel(x) x = self.sobel_kernel(x) x = self.sobel_kernel2(x) x = self.shape_kernel(x) return x |
CNNの学習・推論と同じようにMyFilterのインスタンスを生成して、入力画像(tensor)を流し込めば、出力画像(出力結果)を取得できます。
|
1 2 3 4 |
myfilter = MyFilter() y = myfilter(x) imshow(y) # 描画 |

MyFilterとパイプライン
先ほど作成したMyFilterはパイプラインのようなもので、作成した各フィルタの組み合わせを柔軟に変更することができます。
例えば Blur ⇒ Sobel のみしたいときは、forward(self, x)を以下のように変更すればOKです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
class MyFilter(nn.Module): def __init__(self): super().__init__() # Blur_filter ''' 略 ''' # Sobel_filter ''' 略 ''' # Sobel_filter2 ''' 略 ''' # Shape def forward(self, x): x = self.blur_kernel(x) x = self.sobel_kernel(x) # x = self.sobel_kernel2(x) # x = self.shape_kernel(x) return x myfilter = MyFilter() my_img = myfilter(x) imshow(my_img) # 描画 |

ちょっとスゴイでしょ?(ง •̀ω•́)ง✧
CNNと同じ要領でMyFilter(nn.Module)を作成すれば、フィルタの組み合わせが柔軟なパイプラインのように扱えます(実験がすごく楽)
Pytorchで自作カーネルをCNNに組み込む
最後に自作カーネルをCNNに組み込んでみます。
例えば、Pytorchの公式チュートリアル を参考にCNN設計した後、以下のように自作カーネルを組み込むだけでOKです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
class MyNet(nn.Module): def __init__(self): super().__init__() # Blur_filter k = 9 self.blur_kernel = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, stride=1, padding=1) self.blur_kernel.state_dict()['weight'][0] = torch.FloatTensor([[1/k, 1/k, 1/k], [1/k, 1/k, 1/k], [1/k, 1/k, 1/k]]) self.blur_kernel.state_dict()['bias'].zero_() # Sobel_filter self.sobel_kernel = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, stride=1, padding=1) self.sobel_kernel.state_dict()['weight'][0] = torch.FloatTensor([[1, 0, -1], [2, 0, -2], [1, 0, -1]]) self.sobel_kernel.state_dict()['bias'].zero_() # CNN self.conv1 = nn.Conv2d(1, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 53 * 53, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.blur_kernel(x) x = self.sobel_kernel(x) x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 53 * 53) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x |
このMyNetを学習すれば、重みを固定した自作カーネルと深層学習で重みを自動チューニングしたカーネル(CNN)を組み合わせたモデルを作成できます(改めてイメージ図を以下に置いておきます)。
上図だと最初がSobelフィルタになってるけど、フィルタの変更・追加も可能だし、tensorサイズを気を付ければ、CNNの間や出力後に自作カーネルを組み込むこともできます。
つまり、組み合わせ無限大です!
この組み合わせが良かった!などを発見した人は情報共有して頂けると嬉しいです。あなたにとっては小さな発見でも別の人にとっては、大きな成果に繋がる発見かもしれません。
まとめ -Pytorchによる画像処理【超実践】-
長文読解お疲れさまでした。実践編では以下の内容を説明しました。
- nn.Conv2dの”weight”と”bias”を確認する方法
- 自作カーネルの柔軟な組み合わせを実現するモデル(Myfilter)作成
- 自作カーネルをCNNに組み込んだモデル(MyNet)作成
少しマニアックな内容だったかもしれませんが…楽しかったですか?参考になりましたか?
本記事で画像処理とCNN(深層学習)の両方の面白さと奥深さを伝えられたら嬉しいです。
また本記事をきっかけに…

という人が現れたら、ディープラーニングお兄さんは最高に嬉しいです!
(実践編 完)
おまけ -本ブログのサポートについて-
本記事の内容なら有料でも良い気がしたけど、無料公開にして多くの人に読んでもらうことを優先しました(無料でも手は抜かず、むしろ多くの手間と時間をかけて書き上げました)。
フクロウの”くるる”が丁寧にお辞儀してる姿がすごく可愛い。
もし本記事が参考になり、ブログ『はやぶさの技術ノート』をサポートしたいという人がいれば、以下の方法でサポートして頂けると嬉しいです!
- 本ブログの記事をSNS(Twitterやfacebookなど)でシェア
- ブログをやっている人ならリンクを張ってシェア
- 本ブログで紹介した本などを購入
- LINEスタンプ 購入
- 【くるるの野望ショップ】でフクロウグッズ購入
私のプロフィールにも書いていますが、学生さんや勉強したい人の”学び”を支援したいと考えています。
ブログ『はやぶさの技術ノート』では本記事も含め、多くのチュートリアル記事を無料で公開しています。SNSなどで友達にも教えてあげてほしいです!
また応援メッセージなどを頂けると、次も良い記事書きたいな!というモチベーションに繋がります。Twitterなどで気軽にコメントして頂けると嬉しいです。





(完)