こんにちは。
コンピュータビジョン(『ロボットの眼』開発)が専門の”はやぶさ”@Cpp_Learningです。
最近は、PythonとOpenCVを使った画像処理にハマっています!
OpenCV便利ですよね~画像処理に関する知識があまりなくても、関数をレゴブロックのように繋げるだけで目的の処理ができますからね~
ただ、OpenCVが便利すぎるせいで『画像処理の基礎』を学ぶ機会を失っている人が多いような気がしています。。

という要求があれば、OpenCVの関数を使って一発で変換できますが…

という要求に対し、OpenCVの関数使えないなら無理!というのは悲しいと思うのです。。

という想いで、本記事『画像処理の基礎 -画素操作をマスターする方法-』を書きました。
微力ではありますが、コンピュータビジョンが専門の”はやぶさ”が皆様の勉強をサポートさせて頂きます。本記事をきっかけに、画像処理をもっと学びたい!という人が増えると嬉しい(*・ω・)ノ♪
画像処理の基礎は完全に理解しているので、画素操作のソースコードだけ見せて!という人は、目次から『【実践】OpenCVとPythonで画素(pixel)操作』に飛んで下さいな。
Contents
画像処理の基礎を学ぶモチベーション
冒頭で述べた通り、OpenCVを使えば専門的な知識がなくても、関数の使い方を覚えるだけで、多様な処理を行うことができます。
そのため、以下のようなフローで画像処理を扱う人が多いような気がしています。
- 画像処理で○○がしたい
- OpenCVのサンプルソースを調べる(ブログ記事含む)
- OpenCVの関数を調べる
- 関数の使い方を調べる
- ソースコードを書く
- ○○を実現する
↑のフローで大正解です!やりたいことの実現のために調査・実践を行う姿勢はすごくイイと思います(*・ω・)ノ♪
個人的には、OpenCV使おうが、別のライブラリを使おうが、やりたいことが実現できるなら問題ないと考えています。
後輩も↑のフローで画像処理を頑張っている時期がありました。ただ、後輩の仕事を見ていて以下の点が勿体ないなぁと思う時がありました。
- OpenCV以外のライブラリでやりたいことを実現できない
- ”ライブラリが変わる”と採用できる関数に依存して”やり方も変わる”
- ライブラリ未使用の制約に対応できない
- 基礎的な処理で実現できるのに、トリッキーなやり方をしてしまう
- 基礎がないため調べた内容が正解だと思い込んでしまう
色々書きましたが、↑の多くは基礎をマスターするだけで解決できる場合がほとんどです。
画像処理に限らず基礎をしっかりマスターし、あらゆる局面に対応できる『骨太な技術者』を目指してほしい!と考えています。
やりたいことベースで何かを学ぶ姿勢は素晴らしい!!ただし、やりたいことの実現に注力するあまり、基礎が疎かになるのは勿体ない!基礎をマスターして、あらゆる局面に対応できる『骨太な技術者』を目指してほしい!
画像とコンピュータ
『コンピュータは数値しか扱えない!』という前提は常に頭の片隅に入れておいて下さいな。この前提がないとPCで魔法も使える!と勘違いする人がいます。
コンピュータビジョン…つまりコンピュータで扱う画像も数値で表現されてます。
光の三原色
小学生の理科で『光の三原則』について学んだのを覚えているでしょうか?『赤緑青(RGB)の3色であらゆる色を表現できる』というものです。
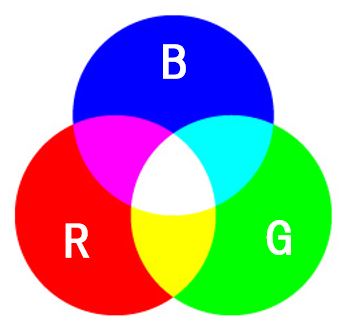
より正確には、『R成分・G成分・B成分の強さを調整することで、あらゆる色を表現できる』というものです。コンピュータやデジカメなどは、各成分を8bit(256諧調)、、つまり0~255の数値で、あらゆる色を表現します。
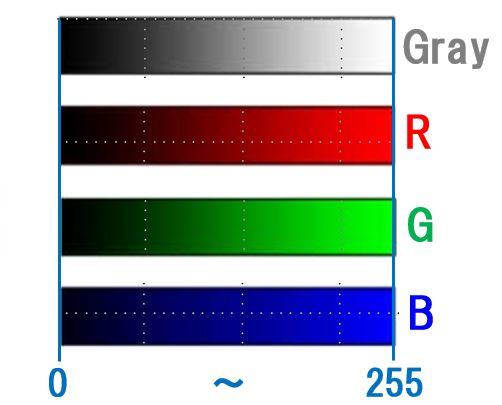
※カラー画像の場合はRGBの3成分ですが、モノクロ画像は光の明暗(グレースケール)のみで表現します。
256以外の諧調で”色”を扱う場合もありますが、コンピュータビジョンの世界では、256諧調(8bit)で各成分を表現する場合がほとんどです。
例えば、カラー画像の場合、以下ようなRGBの組み合わせがあります。
- (R, G, B) = (0, 0, 0)なら”黒”
- (R, G, B) = (255, 255, 255)なら”白”
- (R, G, B) = (255, 0, 0)なら”赤”
- (R, G, B) = (0, 255, 0)なら”緑”
- (R, G, B) = (0, 0, 255)なら”青”
以上のように各成分を0~255で表現するため、色の組み合わせは256×256×256通り存在します。
コンピュータなどで”色”をデジタルデータとして扱う場合、R・G・Bの各成分を256諧調で扱うことが多く、各成分の組み合わせで、多様な色を表現しています。
画素(pixel)
RGB成分の組み合わせで、あらゆる色を表現できることが分かったと思います。次に柄の表現について説明します。
画像とは、画素(pixel)の集合体です。画像の一部分を拡大していくと、画像を構成する最小単位:画素(pixel)まで分解することができます。
画素1つ1つがRGB成分を持っているため、多様な色を表現できます。そのため、各画素の組み合わせで、あらゆる柄を表現することができます。
![]() 柄の組み合わせは、画素数(pixel数)に依存します。例えば、切手サイズの画像が4つの画素で構成されていたら、せいぜい「Windowsロゴ」しか表現できません。一方、無数の画素で構成されていれば「浮世絵」だって表現できます。
柄の組み合わせは、画素数(pixel数)に依存します。例えば、切手サイズの画像が4つの画素で構成されていたら、せいぜい「Windowsロゴ」しか表現できません。一方、無数の画素で構成されていれば「浮世絵」だって表現できます。
このように画素数で表現できる柄が変わり、多様な柄を表現できる画素数が多いものを高画質(高解像度)と呼び、画素数が少ないものを低画質(低解像度)と呼びます。
(セルサイズの話しは控えます。少しマニアックな話題になるので…)
- 画像は画素(pixel)の集合体
- 各画素はRGB成分を持っている
- 1つの画像が表現できる柄は画素数に依存する
画素(pixel)操作とは
カメラが好きな人だと、↑で説明した内容は既知だったかもしれませんね。(知らなかった人は、この記事で勉強できてラッキーだったね!)
ただし、ここまでの説明と画像処理が結びついていない人が意外と多いような気がしています。
というのは半分正解です。しかし、より正確には…
が大正解だと考えています。以下のイメージだよ!
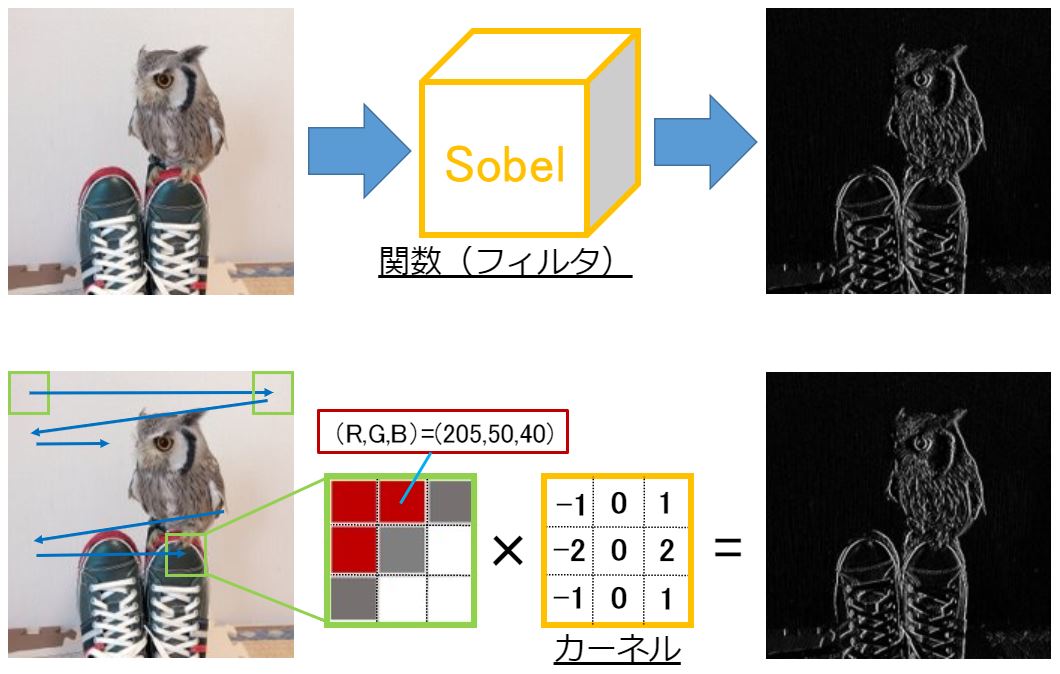
分かるかな?上が画像全体に対し関数を使うイメージで、下が画像全体から3×3の画素を抽出して、カーネルを使うイメージです。最終的には、画像全域にカーネルを使うため、どちらのやり方でも出力結果は同じになります。
繰り返しですが、画像は画素の集合体で、各画素はRGB成分の数値を持っています。つまり、「画像の画素(pixel)」=「行列の要素」と考えれば、画像は行列として扱うことができます。
上図のように一部の画素(部分行列)を抽出して、行列演算するも良し!全ての画素に対し行列演算するも良しです!
この『画像⇒画素の集合⇒行列で扱える』という画像処理の基礎を知らずにOpenCVの関数を使っている人が意外と多いような気がしています。OpenCVの関数の中身を覗いてみると行列演算をしているものが沢山ありますよ。
画像は行列として扱えます!!
【実践】OpenCVとPythonで画素(pixel)操作
ここまでの説明が『画像および画像処理の基礎知識』です。この基礎知識を使って、画像処理を実践します!(Python3.6.5 + OpenCV3.4.1を使いました。)
課題❶ -単色画像生成-
最初の課題は「単色画像生成」です。今まで説明した言葉を使うなら、『全画素(pixel)のRGB成分が同じ画像の生成』です。
何故この課題にしたかというと、シンプルゆえに色んな手法が考えられる上、基礎知識の有無も判断しやすい課題だからです。
例えば、以下のような「単色画像生成」の手法があります。
- 適当な画像を生成 or 読み込む ⇒ 画像上に矩形図(■)を上書き描画する
- ペイント等の描画ソフトで単色画像を生成 ⇒ 読み込む
- Numpy等で0行列生成 ⇒ 行列演算 ⇒ OpenCVの画像データに変換
本記事の前半で書いた通り、OpenCV使おうが、別のライブラリやソフトを使おうが、やりたいこと(この例では単色画像生成)が実現できるなら問題ないと考えています。
ただ、❶~➌の手法は以下の点が勿体ないなぁと感じました。
- 矩形図(■)の上書きは描画位置(座標)の指定が必須のため、少し冗長的
- 複数のソフトを使用するため人の作業が多い
- OpenCVで行列が扱えないと思ってる?
画像は行列として扱えるし、コンピュータビジョン専用ライブラリのOpenCVは行列演算(画素操作)も得意ですよ(*・ω・)ノ♪
単色画像生成も画素操作でやるとスマートです。
本記事の『画素操作』とは、より正確には『画素が持っているRGB成分を任意に変更する処理』のことです。
”黒”画像生成
黒は(R, G, B) = (0, 0, 0)でしたね!以下のソースコードで”黒”画像生成ができます。
|
1 2 3 4 5 6 7 8 9 10 |
import cv2 # Image Read cv_img = cv2.imread('owl.jpg') cv2.imshow("cv_img", cv_img) # Create Black_img black_img = cv_img * 0 cv2.imshow("black_img", black_img) cv2.waitKey(0) & 0xFF == ord('q') |
ポイントは8行目の以下の部分です。
black_img = cv_img * 0
読み込んだ画像データ”cv_img”は行列として扱えます。↑のように”×0”すると全ての画素のRGB成分を0にできます。(ただの積算です)
ね?スマートでしょ?
”白”画像生成
じゃあ”白”画像生成はどうやる?私ならこうやるかなぁ↓
|
1 2 3 |
# Create White_img white_img = black_img + 255 cv2.imshow("white_img", white_img) |
白は(R, G, B) = (255, 255, 255)なので、黒画像の全画素に”+255″するだけです。
”赤”画像生成
RGB成分をチャンネル(channel)と表現することがあります。黒/白画像生成はRGB成分(3ch)全てに同一の演算をしました。
赤は(R, G, B) = (255, 0, 0)なので、ch別で演算を変える必要があります。つまり、以下のフローで黒/白画像以外の単一画像生成が実現できます。
- カラー画像のRGB成分を分離する(ch分離)
- ch毎に演算
- 分離したchを結合する
以下がソースコード
|
1 2 3 4 5 |
# Create Red_img(Split ⇒ Marge) blue_img_cb, green_img_cb, red_img_cb = cv2.split(black_img) # all "0" blue_img_cw, green_img_cw, red_img_cw = cv2.split(white_img) # all "255" red_img = cv2.merge((blue_img_cb, green_img_cb, red_img_cw)) # (b,g,r) = (0,0,255) cv2.imshow("red_img", red_img) |
色々なやり方が考えられますが、今回は黒/白画像が生成済みだったので、利用しました。
コードの2行目で黒画像、3行目で白画像のchを分離し、
blue_img_cb, green_img_cb, red_img_cb = cv2.split(black_img)
blue_img_cw, green_img_cw, red_img_cw = cv2.split(white_img)
4行目で白画像の赤成分と黒画像の緑青成分を結合しています。
red_img = cv2.merge((blue_img_cb, green_img_cb, red_img_cw))
この手法で様々な色の生成が可能です。
RGB成分(3ch)を分離することができ、ch毎に演算後、再結合できます。
”グレー”画像生成
単色画像を生成する手法で以下を説明しました。
- 適当な画像を生成 or 読み込む ⇒ 画像上に矩形図(■)を上書き描画する
↑の手法は上書きですが、2つの画像(画素)に”重み”をかけて結合するという手法もあります。以下がソースコード
|
1 2 3 |
# Create gray_img(overlay) gray_img = cv2.addWeighted(black_img, 0.5, white_img, 0.5, 0) cv2.imshow("gray_img", gray_img) |
この例では、黒/白の両画像に0.5の重みをかけて結合することで、グレー画像を生成できます。このように画像を重ねる技術を『オーバーレイ』と呼びます。
『上書き』と『オーバーレイ』って何が違うの?という人のために以下の画像を生成してみました。上書きじゃないので、白画像にはならない。
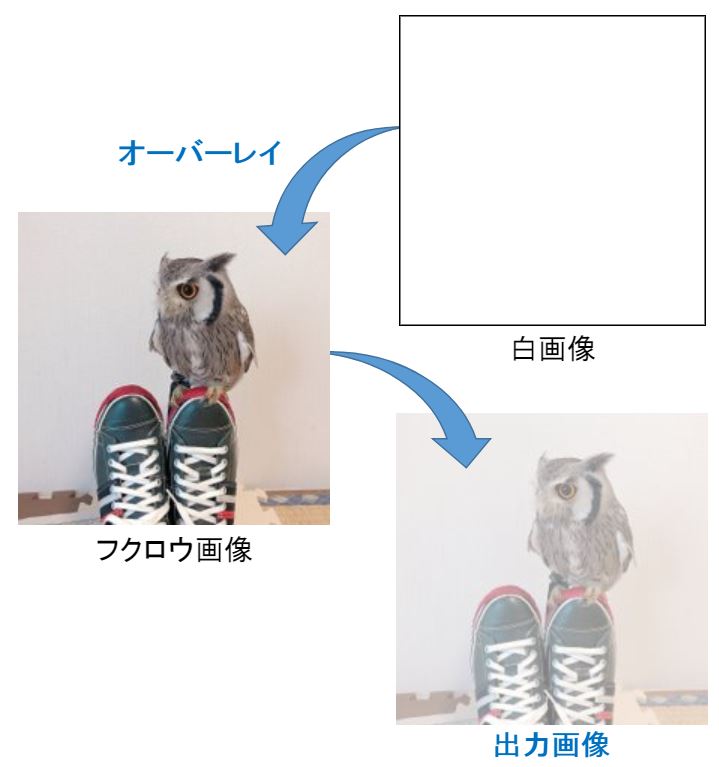
課題❷ -Myカーネルによる画像処理-
課題❶は色に関する画素操作の説明でした。次は柄に関する画素操作を説明します。概要については、既に説明済みですが、下図のカーネルを使った演算を掘り下げて説明していきます。
画像(行列)に対し、カーネルを使って演算することを『畳み込み(Convolution)』と呼びます。畳み込み演算は行列同士の各要素を積算後に和算する…言葉で説明するより、数式を見た方が分かりやすいね↓
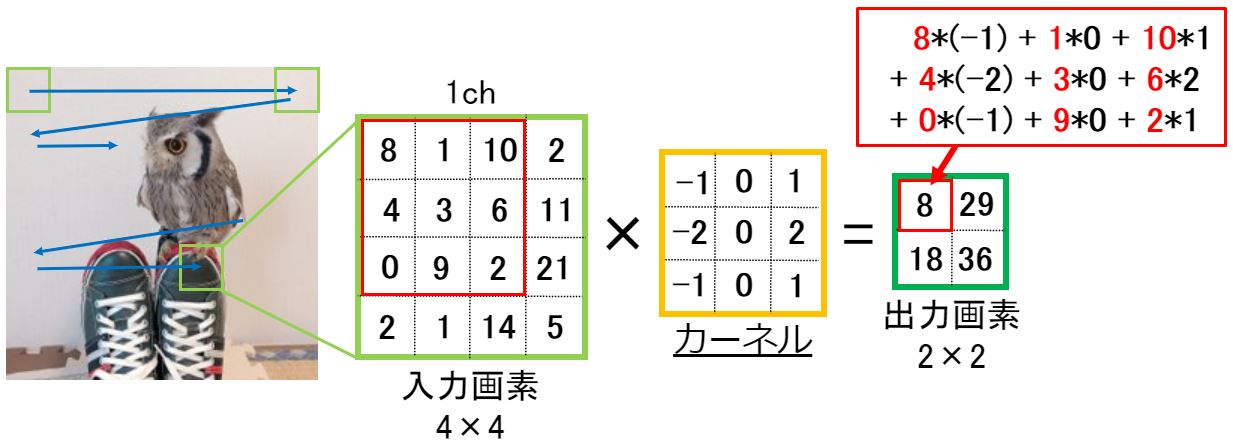
↑のようなカーネルを使うことで画像から特定の特徴抽出を行うことができます。(特定の特徴抽出については以降で説明します。)
- カーネルを使った画像処理を『畳み込み(Convolution)』と呼びます。
- 畳み込み演算で画像から特定の特徴抽出が可能。
Sobelフィルタ生成
『カーネル内の要素にどんなパラメータを設定すべきか?』という研究は日々行われており、優秀な先輩エンジニア達が様々なカーネルを考案しています。
例えば、今までの図で登場した±2・±1・0の要素で構成されたカーネルは『Sobelフィルタ』と呼ばれるもので、画像内のエッジ(輪郭)を抽出したいときに使います。
OpenCVには、Sobelフィルタ用の関数が用意されており、以下のコードで使えます。
|
1 2 3 4 |
# Sobel Filter x gray_img = cv2.imread('owl.jpg', 0) # input gray sobel_img = cv2.Sobel(gray_img, cv2.CV_32F, 1, 0, ksize=3) # cv2.CV_32F cv2.imshow("Sobel Kernel", sobel_img) |
このSobelフィルタは以下のように自作カーネルでも実現できます。
|
1 2 3 4 5 6 7 |
# Kernel for Sobel Filter x sobel_kernel = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]) sobel_img_k = cv2.filter2D(gray_img, -1, sobel_kernel) cv2.imshow("Sobel Kernel", sobel_img_k) |
一般的にカーネルサイズは3×3や5×5が多いです。(↑は3×3のカーネルです。)
カーネルは自作できる!
アンシャープマスク(鮮鋭化)フィルタ生成
Sobelフィルタに関してはOpenCVの関数があるため、自作カーネルを生成する旨味が薄いですが…
という要求に対して使える『アンシャープマスク(鮮鋭化)フィルタ』というものがあるのですが、OpenCVに関数がないんですよね…。なので、カーネル自作しましょう!
以下ソースコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# Kernel for Shape k = 0.3 # Shape Strength shape_kernel = np.array([[0, -k, 0], [-k, 1+4*k, -k], [0, -k, 0]]) shape_kernel2 = np.array([[-k, -k, -k], [-k, 1+(8*k), -k], [-k, -k, -k]]) shape_img_k = cv2.filter2D(cv_img, -1, shape_kernel) shape_img_k2 = cv2.filter2D(cv_img, -1, shape_kernel2) cv2.imshow("Shape Kernel1", shape_img_k) cv2.imshow("Shape Kernel2", shape_img_k2) |
2パターン用意してみました。以下が出力結果です。「フクロウの細かい羽」や「壁や靴の模様」が鮮明になってますね。
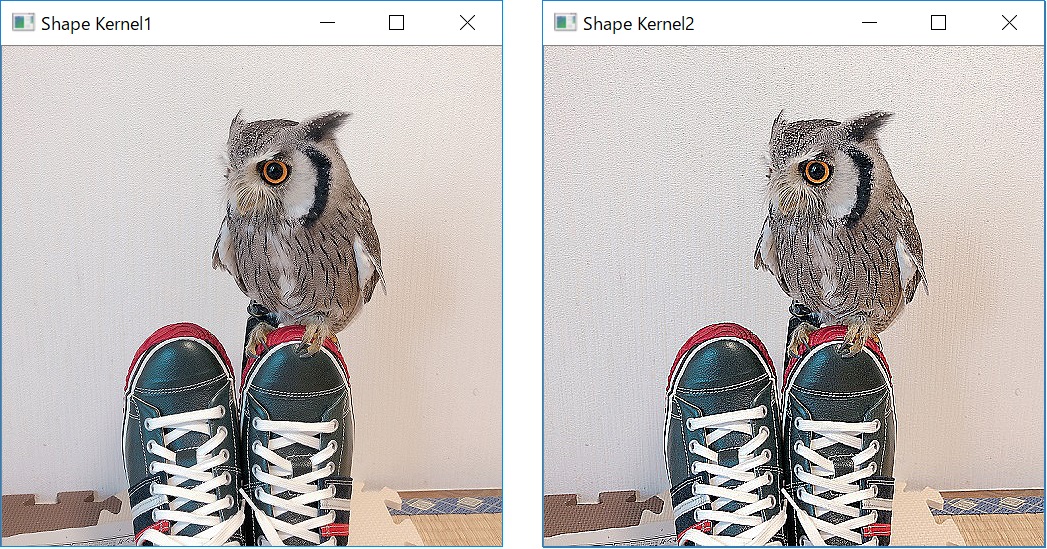
繰り返す!カーネルは自作できる!
まとめ -画像処理の基礎-
以上が、コンピュータビジョンが専門の”はやぶさ”が教えたかった『画像処理の基礎 -画素操作をマスターする方法-』の内容でした。勉強になったかな?
本記事では、OpenCVを使いましたが、どのライブラリを使うかは、重要ではありません!重要なのは、要求に合う関数がなかったときにカーネルを自作できるだけの『画像処理の基礎 』を修得しているかどうかです。
分野を問わず『無いなら作ればイイじゃん!』を本当にやっちゃう人って『基礎力』が高い人だと私は思いますよ。
画像処理は奥が深いです!しかし、今回説明した内容を自分なりに消化できれば、画像処理の多くを理解できるようになると思いますよ!
本記事を読んで「画像処理もっと勉強したい!」という人が現れたら、すごく嬉しい!
(第1部 完)
━━━━━━━━━━━━━━━━
…ここまで読んで、まだ元気な人は続き(第2部 -深層学習と画像処理-)も読んでみて下さいな。
深層学習と画像処理
深層学習の”Hello World”として有名な『手書き数字認識:MNIST』の(CNN設計)チュートリアルをやってみたけど、何をやってるかよく分からなかった…という人がいます。
個人的には、CNN設計より先にNN設計を学んだ方が深層学習を理解しやすいと思ったので、以下の記事を書きました。

- NN:Neural Network(ニューラルネットワーク)
- CNN:Convolutional Neural Network(畳み込みNN)
しかし、画像処理で深層学習を使いたいならCNNは避けては通れないと考えています。私なりに、なぜCNNが難しいのかを考え、以下の理由かな(?)という結論を出しました。
- 『画像処理の基礎』を修得できていない
- CNNを理解するのに必要な専門知識(情報量)が多すぎてパンクした
でも大丈夫!『画像処理の基礎』については、第1部の内容が理解できれば問題ないよ!
また、パンクした人のために『CNNのここだけは覚えて!』というポイントを絞り、情報量を抑えた説明を以降からしていきます。
もう少し頑張ろう(ง •̀ω•́)ง✧
困難は分割せよ!複雑な応用技術も紐解いていくと、基礎技術の集合体である場合がほとんどです。応用に目がいきがちですが、基礎技術1つ1つを丁寧に理解すると、最終的には応用技術も理解できるようになります。(自論)
深層学習と畳み込み
第1部の課題❷でカーネルの自作方法を説明しました。また、カーネルの役割は『画像から特定の特徴抽出』をすることでした。第1部で説明したカーネルについては以下の通りです。
| カーネル | 特徴抽出の内容 |
|---|---|
| Sobelフィルタ | 画像内のエッジを抽出 |
| 鮮鋭化フィルタ | 画像内の細かい柄を抽出 |
また、カーネルを使った演算を『畳み込み(”C”onvolution)』と呼びました。CNNの”C”と同じです!
画像処理より先に深層学習を勉強した人だと、『畳み込み』を深層学習の技術だと勘違いしそうですが、『畳み込み』は画像処理の…より正確には行列演算の技術です。
私のプロフィールにも書いていますが、修得した知識やスキルは必ずどこかで活かせます!大学で履修した数字は深層学習などの先進的な研究でも活かせますよ!
CNN概要
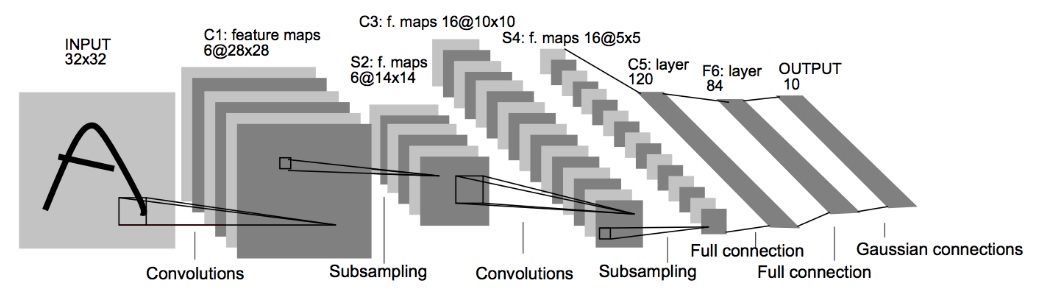
1998年にYann LeCun先生が考案した以下の『LeNet』がCNNの元祖と言われています。
また、下記の記事で書いた通り、深層学習でいう”学習”とは”重み”の自動調整のことです。
NNの場合はノード間に重みw1~Wnがありました。(下図参照)
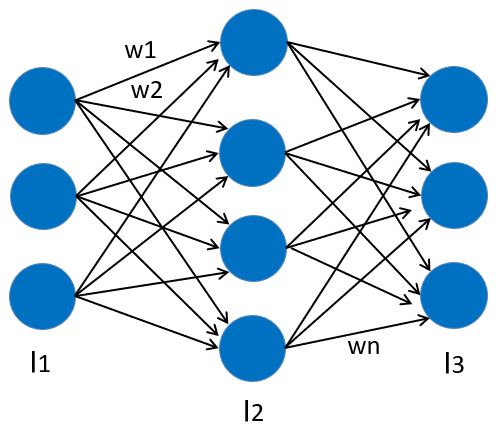
では、CNNでいう”重み”がどこにあるか分かっていますか?以降でポイントを絞って説明してみますね!
深層学習では、”重み”の自動調整のことを”学習”と呼びます。
コンピュータビジョンの課題と深層学習
優秀な先輩エンジニア達が様々なカーネルを考案し、画像内から任意の特徴を抽出することが可能になりましたが…
コンピュータビジョン最大の目的は『人と同等以上の性能の”眼”を作ること』だと私は考えています。人は眼(画像)から文字やモノを認識することができます。
つまり、人は画像から『何らかの特徴抽出』を行い、最終的には「数字の1」・「アルファベットのA」・「イヌ」・「ねこ」・「男性」・「女性」などを認識できるということです。
この『何らかの特徴抽出』を実現するカーネル設計を人類はずーーっと研究してきました。
Sobelフィルタのところでも書きましたが、要するに『カーネル内の要素にどんなパラメータを設定すべきか?』という研究です。
…で!人類が長年頑張っても良いカーネルを設計できないなら…『深層学習でカーネル内の要素(重み)を自動で調整』すればイイじゃん!というのがCNNです。
CNNでいう、”重み”とはカーネルの要素のことです。深層学習では、この要素(重み)を自動調整のことを”学習”と呼びます。
CNN設計
CNN設計の特に学習に関する部分にポイントを絞ってい説明します。
下図は『LeNet』の赤丸部分を第1部で説明したの図に書き直してたものです。
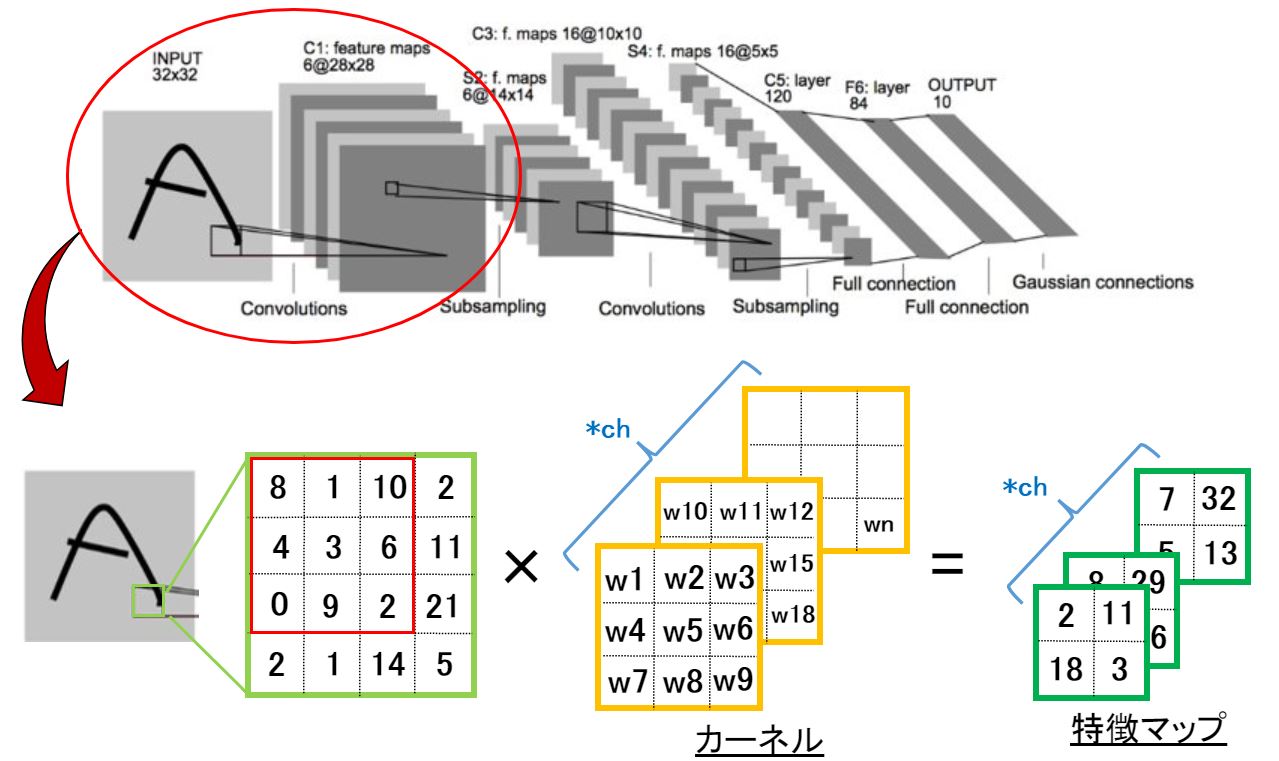
(カーネルサイズが違うとか特徴マップのサイズと数が違うとかは、目を瞑って下さい。本記事では、CNNの雰囲気が伝われば良いと考えています。)
ポイントはカーネルが複数存在する点です。第1部の課題❷では1つのカーネルのみ使用しましたが、”A”の特徴を抽出のために、カーネルの数・並列・直列を制限する理由はありません。
むしろ、カーネル数を増やすことで出力結果(特徴マップ)を増やせるというのが重要です。
また、畳み込み演算で特徴マップの数を減らすことも、プーリング処理で特徴マップのサイズを調整することもできます。
つまり、CNN設計とは、以下ことを検討する作業のことです。
- カーネルのサイズ
- カーネルの数
- カーネルの並び(並列・直列)
- ストライド設定
- プーリングを実施するタイミング
- 損失関数
(”ストライド”・”プーリング”・”損失関数”の説明は控えめにしました。一気に説明すると混乱させそうなので…)
- カーネルの数・並びは、人が検討(設計)する
- 設計次第で特徴マップのサイズや数を調整できる
CNNと学習
CNN設計後、カーネルの要素(重み)は中身空っぽ(生まれたてのベイビー)なので、大量の教師データ(認識させたい対象が写った画像)を使って学習させます。
なお、入力画像のサイズを考慮してCNN設計を行うため、準備する教師データの画像サイズは統一する必要があります。
あとはNN同様に学習するだけです!例えば、”数字の1”という画像をCNNに入力したときに、1の特徴を抽出できるカーネルの要素(重み)を自動調整するのが、CNNの学習です。
繰り返す!深層学習では、CNN・NNどちらでも、”重み”の自動調整のことを”学習”と呼びます。
まとめ -深層学習と画像処理-
長文読解お疲れさまでした。第2部はCNN設計の特に学習に関する『カーネルの重み調整』にポイントを絞って説明しました。
本記事を一読しただけでは、よく分からない!という人もいれば、頭の中がすっきりした人もいると思います。中には、物足りなかったという人もいるかもしれません。
と思った人!もう、あなたは深層学習の入門レベルではありません!改めて、MNISTのチュートリアルを覗いてみて下さい!もう理解できない所はほとんどないのでは?とディープラーニングお兄さんは思うのです。
学習が上手くいかなーい!と言いながら何度も失敗を繰り返して、CNN設計手法を勉強しています。CNN設計は奥が深いです!本記事を読んでCNN設計がどういうものかイメージできたら、次は実際CNN設計してみてほしい!
本記事をきっかけにCNNに興味を持ってもらい「CNNの設計ノウハウを勉強したい!」という人が現れたら、ディープラーニングお兄さんは嬉しい!
(第2部 完)
おまけ -メッセージとおすすめの書籍-
時間に余裕のある人は読んでみてね↓
メッセージ
フクロウの”くるる”は羽伸ばしストレッチをしながら呟く

良いよーと言いながら、小さく何度も頷く”くるる”がすごく可愛い
”くるる”どんどん賢くなってるな!笑
本記事、実は第1部と第2部を完全に分離して別々の記事にする予定でした。
しかし、『画像処理の基礎』と『深層学習(CNN)』がうまくリンクできておらず、CNNよく分からん(´;ω;`)となっている人を救いたいという想いから、一気に書き上げました(結構書くの大変でした。。)
そのため、”二つの重たい内容”と”丁寧な説明”により、長文になってしまいましたが、読み易くなるように最大限配慮したつもりです。。
本記事を読んだ”くるるちゃん”のように『画像処理の基礎』と『深層学習(CNN)』がリンクできた!CNNのイメージが沸いた!という人が少しでもいれば嬉しい。
おすすめの書籍
うずうず…”くるる”が羽毛を揺れしながら呟く
はい!「もっと勉強したい!」というモチベーションの高い人のために以下の本を紹介!
[詳解] 画像処理プログラミング
誤字・脱字が多い…という理由で低く評価されることも多い本ですが、画像処理ライブラリを一切使わずに、C言語のみで実装する画像処理アルゴリズムは大変参考になりました。使用する言語がPythonになっても、画像処理の基礎は変わりません。ライブラリに頼らないソースコードが書けると応用の幅が広がりますよ!

詳解 OpenCV 3
タイトルの”OpenCV 3”がミスリードして、OpenCVのHow to本と思われがちですが、図や数式で画像処理アルゴリズムそのものを丁寧に説明した上で、OpenCVでの実装方法を説明している良本です。OpenCV使いたい人はもちろん、画像処理アルゴリズムを勉強したい人にも おすすめです。

ゼロから作る Deep Learning
事あるごとに おすすめしている良本。深層学習フレームワークはとても便利ですが、フレームワークの使い方に振り回されて、深層学習そのものを学ぶ機会がなくなるのは勿体ない!深層学習そのものを学びたいなら、一度フレームワークから離れて、『ゼロから作る』と良いと思いますよ。

PythonとKerasによるディープラーニング
『ゼロから作る Deep Learning』で勉強した後は、やはり深層学習フレームワークを使ってNN・CNN設計をするのが良いと思います。深層学習フレームワークの選択で悩んでいる人は”Keras”を使うのが良いと思いますよ。そして、参考書は”Keras”作成者が書いた本が おすすめです。

画像処理・深層学習を思い切り楽しんで下さいな!
(完)

















